五分钟带你搞懂MySQL索引下推
目录
- 什么是索引下推
- 索引下推优化的原理
- 索引下推的具体实践
- 没有使用ICP
- 使用ICP
- 索引下推使用条件
- 相关系统参数
- 总结
如果你在面试中,听到MySQL5.6”、“索引优化” 之类的词语,你就要立马get到,这个问的是“索引下推”。
什么是索引下推
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。
索引下推优化的原理
我们先简单了解一下MySQL大概的架构:
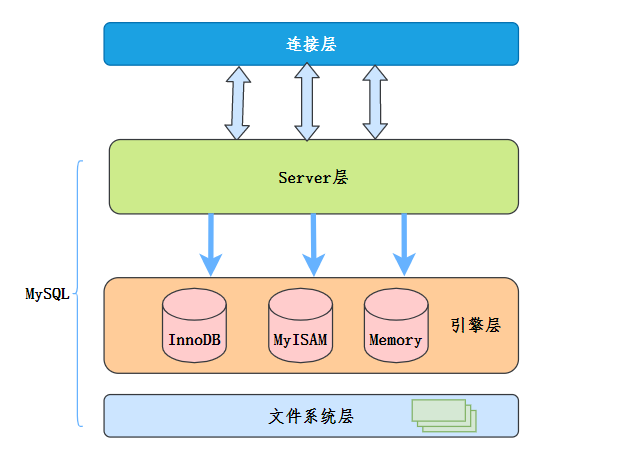
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
我们来具体看一下,在没有使用ICP的情况下,MySQL的查询:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
- 存储引擎读取索引记录(不是完整的行记录);
- 判断WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录;
- 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给Server层,Server层检测该记录是否满足WHERE条件的其余部分。
索引下推的具体实践
理论比较抽象,我们来上一个实践。
使用一张用户表tuser,表里创建联合索引(name, age)。
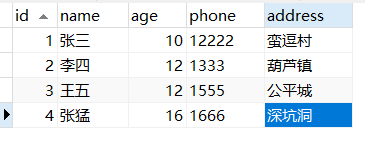
如果现在有一个需求:检索出表中名字第一个字是张,而且年龄是10岁的所有用户。那么,SQL语句是这么写的:
select * from tuser where name like '张%' and age=10;
假如你了解索引最左匹配原则,那么就知道这个语句在搜索索引树的时候,只能用 张,找到的第一个满足条件的记录id为1。
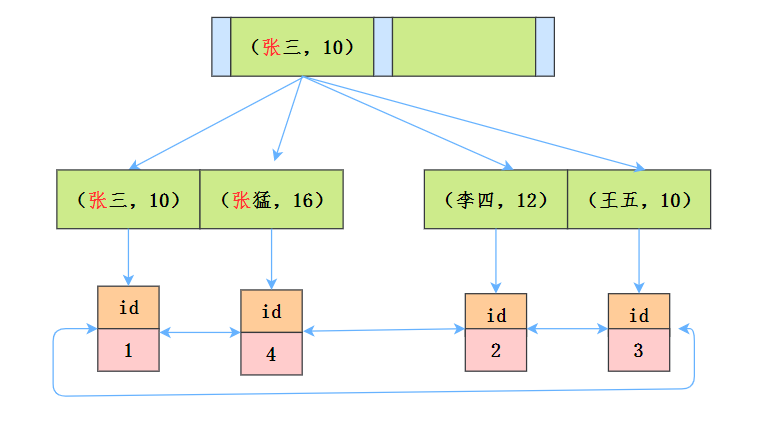
那接下来的步骤是什么呢?
没有使用ICP
在MySQL 5.6之前,存储引擎根据通过联合索引找到name likelike '张%' 的主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
我们看一下示意图:
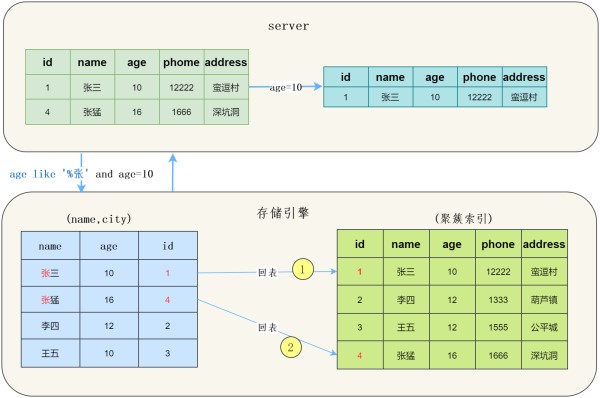
可以看到需要回表两次,把我们联合索引的另一个字段age浪费了。
使用ICP
而MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到name likelike '张%',由于联合索引中包含age列,所以存储引擎直接再联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。
我们看一下示意图:
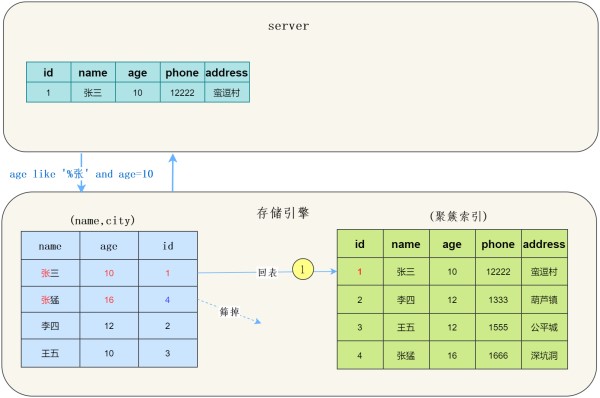
可以看到只回表了一次。
除此之外我们还可以看一下执行计划,看到Extra一列里 Using index condition,这就是用到了索引下推。
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | tuser | NULL | range | na_index | na_index | 102 | NULL | 2 | 25.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
索引下推使用条件
- 只能用于
range、ref、eq_ref、ref_or_null访问方法; - 只能用于
InnoDB和MyISAM存储引擎及其分区表; - 对
InnoDB存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
索引下推的目的是为了减少回表次数,也就是要减少IO操作。对于InnoDB的聚簇索引来说,数据和索引是在一起的,不存在回表这一说。
- 引用了子查询的条件不能下推;
- 引用了存储函数的条件不能下推,因为存储引擎无法调用存储函数。
相关系统参数
索引条件下推默认是开启的,可以使用系统参数optimizer_switch来控制器是否开启。
查看默认状态:
mysql> select @@optimizer_switch\G; *************************** 1. row *************************** @@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on 1 row in set (0.00 sec)
切换状态:
set optimizer_switch="index_condition_pushdown=off"; set optimizer_switch="index_condition_pushdown=on";
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

五分钟让你快速弄懂MySQL索引下推
大家好,我是老三,今天分享一个小知识点--索引下推. 如果你在面试中,听到MySQL5.6"."索引优化" 之类的词语,你就要立马get到,这个问的是"索引下推". 什么是索引下推 索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率. 索引下推优化的原理 我们先简单了解一下MySQL大概的架构: MySQL服务层负责SQL语法解析.生成执行计划等,并调用存储引擎层去执
-
Mysql性能优化之索引下推
索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询. 在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件 . 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出
-
MySQL索引下推(ICP)的简单理解与示例
前言 索引下推(Index Condition Pushdown, 简称ICP)是MySQL 5.6 版本的新特性,它能减少回表查询次数,提升检索效率. MySQL体系结构 要明白索引下推,首先要了解MySQL的体系结构: 上图来自MySQL官方文档. 通常把MySQL从上至下分为以下几层: MySQL服务层:包括NoSQL和SQL接口.查询解析器.优化器.缓存和Buffer等组件. 存储引擎层:各种插件式的表格存储引擎,实现事务.索引等各种存储引擎相关的特性. 文件系统层: 读写物理文件. M
-
一篇文章读懂什么是MySQL索引下推(ICP)
目录 一.简介 二.原理 三.实践 3.1 不使用索引下推 3.2 使用索引下推 四.使用条件 五.相关系统参数 总结 一.简介 ICP(Index Condition Pushdown)是在MySQL 5.6版本上推出的查询优化策略,把本来由Server层做的索引条件检查下推给存储引擎层来做,以降低回表和访问存储引擎的次数,提高查询效率. 二.原理 为了理解ICP是如何工作的,我们先了解下没有使用ICP的情况下,MySQL是如何查询的: 存储引擎读取索引记录: 根据索引中的主键值,定位并读取完
-
五分钟带你搞懂MySQL索引下推
目录 什么是索引下推 索引下推优化的原理 索引下推的具体实践 没有使用ICP 使用ICP 索引下推使用条件 相关系统参数 总结 如果你在面试中,听到MySQL5.6"."索引优化" 之类的词语,你就要立马get到,这个问的是"索引下推". 什么是索引下推 索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率. 索引下推优化的原理 我们先简单了解一下MySQL大概的架构:
-
五分钟带你搞懂python 迭代器与生成器
前言 大家周末好,今天给大家带来的是Python当中生成器和迭代器的使用. 我当初第一次学到迭代器和生成器的时候,并没有太在意,只是觉得这是一种新的获取数据的方法.对于获取数据的方法而言,我们会一种就足够了.但是在我后来Python的使用以及TensorFlow等学习使用当中,我发现很多地方都用到了迭代器和生成器,或者是直接使用,或者是借鉴了思路.今天就让我们仔细来看看,它们到底是怎么回事. 迭代器 我们先从迭代器开始入手,迭代器并不是Python独有的概念,在C++和Java当中都有itera
-
一文搞懂MySQL索引页结构
目录 1.前言 2.索引页结构 2.1FileHeader 2.2PageHeader 2.3UserRecords 2.4Infimum&Supremum 2.5PageDirectory 2.6FileTrailer 3.总结 1. 前言 「页」是InnoDB管理存储空间的基本单位,也是内存和磁盘交互的基本单位.也就是说,哪怕你需要1字节的数据,InnoDB也会读取整个页的数据,下次读取的数据如果恰巧也在这个页里,就能命中缓存了.写也是一样的,写数据前要先把页加载到内存,然后在内存中修改,该
-
一文搞懂MySQL持久化和回滚的原理
目录 redo log 为什么要先更新内存数据,不直接更新磁盘数据? 为什么需要redo log? redo log是如何实现的? 为什么一个block设计成512字节? 为什么要两段式提交? crash后是如何恢复的? undo log 什么情况下会生成undo log? undo log是如何回滚的? undo log存在什么地方? redo log 事务的支持是数据库区分文件系统的重要特征之一,事务的四大特性: 原子性:所有的操作要么都做,要么都不做,不可分割. 一致性:数据库从一种状态变
-
一文带你搞懂JS中六种For循环的使用
目录 一.各个 for 介绍 1.for 2.for ... in 3.for ... of 4.for await...of 5.forEach 6.map 二.多个 for 之间区别 1.使用场景差异 2.功能差异 3.性能差异 三.for 的使用 for 循环在平时开发中使用频率最高的,前后端数据交互时,常见的数据类型就是数组和对象,处理对象和数组时经常使用到 for 遍历,因此下班前花费几分钟彻底搞懂这 5 种 for 循环.它们分别为: for for ... in for ... o
-
一文搞懂Mysql中的共享锁、排他锁、悲观锁、乐观锁及使用场景
目录 一.常见锁类型 二.Mysql引擎介绍 三.常用引擎间的区别 四.共享锁与排他锁 五.排他锁的实际应用 六.共享锁的实际应用 七.死锁的发生 八.另一种发生死锁的情景 九.死锁的解决方式 十.意向锁和计划锁 十一.乐观锁和悲观锁 总结 一.常见锁类型 表级锁,锁定整张表 页级锁,锁定一页 行级锁,锁定一行 共享锁,也叫S锁,在MyISAM中也叫读锁 排他锁,也叫X锁,在MyISAM中也叫写锁 悲观锁,抽象性质,其实不真实存在 乐观锁,抽象性质,其实不真实存在 常见锁类型 二.Mysql引擎
-
五分钟带你了解Java的接口数据校验
本篇文章给大家分享平时开发中总结的一点小技巧!在工作中写过Java程序的朋友都知道,目前使用Java开发服务最主流的方式就是通过Spring MVC定义一个Controller层接口,并将接口请求或返回参数分别定义在一个Java实体类中,这样Spring MVC在接收到Http请求(POST/GET)后,就会自动将请求报文自动映射成一个Java对象.这样的代码通常是这样写的: @RestController public class OrderController { @Autowired pr
-
一篇文章搞懂MySQL加锁机制
目录 前言 锁的分类 乐观锁和悲观锁 共享锁(S锁)和排他锁(X锁) 按加锁粒度区分 全局锁 表级锁(表锁和MDL锁) 意向锁 行锁 间隙锁 next-key lock(临键锁) 加锁规则 死锁和死锁检测 总结 前言 在数据库中设计锁的目的是为了处理并发问题,在并发对资源进行访问时,数据库要合理控制对资源的访问规则. 而锁就是用来实现这些访问规则的一个数据结构. 在对数据并发操作时,没有锁可能会引起数据的不一致,导致更新丢失. 锁的分类 乐观锁和悲观锁 乐观锁: 对于出现更新丢失的可能性比较乐观
-
一文搞懂MySQL元数据锁(MDL)
目录 一.什么是metadata lock 二.MDL和行锁有什么区别 三.MDL为什么会造成系统崩溃 四.MDL的生命周期有多长 五.如何快速找到阻塞源头 六.本文开始的案例最终如何解决 小结 某日,路上收到用户咨询,为了清除空间,想删除某200多G大表数据,且已经确认此表不再有业务访问,于是执行了一条命令‘delete from bigtable’,但好长时间也没删完,经过咨询后,获知drop table删除表速度快,而且能彻底释放空间,于是又在另外一个session中执行了‘drop ta