Spring Cloud Sleuth 和 Zipkin 进行分布式跟踪使用小结
目录
- 什么是分布式跟踪?
- 分布式跟踪的关键概念
- 带有SpringCloudSleuth的SpringBoot示例
- 使用Zipkin可视化跟踪
分布式跟踪允许您跟踪分布式系统中的请求。本文通过了解如何使用 Spring Cloud Sleuth 和 Zipkin 来做到这一点。

对于一个做所有事情的大型应用程序(我们通常将其称为单体应用程序),跟踪应用程序内的传入请求很容易。我们可以跟踪日志,然后弄清楚请求是如何处理的。除了应用程序日志本身之外,我们无需查看其他任何内容。
随着时间的推移,单体应用程序变得难以扩展,难以处理大量请求以及随着代码库规模的不断扩大向客户提供新功能。这导致将单体架构分解为微服务,这有助于扩展单个组件并有助于更快地交付。
但并非所有闪耀的都是黄金,对吧?微服务也是如此。我们将整个单体系统拆分为微服务,由一组本地函数调用处理的每个请求现在都被调用一组分布式服务所取代。这样一来,我们就失去了追踪在单体应用中很容易完成的请求之类的事情。现在,要跟踪每个请求,我们必须查看每个服务的日志,并且很难关联。
因此,在分布式系统的情况下,分布式跟踪的概念有助于跟踪请求。
什么是分布式跟踪?
分布式跟踪是一种机制,我们可以使用它跟踪整个分布式系统中的特定请求。它允许我们跟踪请求如何从一个系统进展到另一个系统,从而完成用户的请求。
分布式跟踪的关键概念
分布式跟踪包含两个主要概念:
- 跟踪 ID
- 跨度编号
跟踪 id 用于跟踪传入请求并在所有组合服务中跟踪它以满足请求。Span id 跨越服务调用以跟踪接收到的每个请求和发出的响应。
让我们看一下图表。

传入的请求没有任何跟踪 ID。拦截调用的第一个服务会生成跟踪 ID“ID1”及其跨度 ID“A”。span id“B”涵盖了从服务器一的客户端发出请求到服务器二接收、处理并发出响应的时间。
带有 Spring Cloud Sleuth 的 Spring Boot 示例
让我们创建一个集成了 Spring Cloud Sleuth 的应用程序。首先,让我们访问https://start.spring.io/并使用依赖项“Spring Web”和“Spring Cloud Sleuth”创建一个应用程序。
现在让我们创建一个带有两个请求映射的简单控制器。
public class Controller {
private static final Logger logger = LoggerFactory.getLogger(Controller.class);
private RestTemplate restTemplate;
@Value("${spring.application.name}")
private String applicationName;
public Controller(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
@GetMapping("/path1")
public ResponseEntity path1() {
logger.info("Request at {} for request /path1 ", applicationName);
String response = restTemplate.getForObject("http://localhost:8090/service/path2", String.class);
return ResponseEntity.ok("response from /path1 + "+ response);
@GetMapping("/path2")
public ResponseEntity path2(){
logger.info("Request at {} at /path2", applicationName);
return ResponseEntity.ok("response from /path2 ");
}
在这里,我创建了两条路径,Path2调用Path2固定端口 8090。这里的想法是运行同一应用程序的两个单独实例。
现在为了允许侦探将标头注入到传出请求中,我们需要将 RestTemplate 作为 bean 注入,而不是直接初始化它。这将允许侦探向 RestTemplate 添加一个拦截器,以将带有跟踪 id 和跨度 id 的标头注入到传出请求中。
@Bean
public RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}
现在,让我们启动两个实例。为此,首先,构建应用程序,mvn clean verify然后运行以下命令来启动“服务 1”。
java -jar \target/Distributed-Service-0.0.1-SNAPSHOT.jar \--spring.application.name=Service-1 \--server.port=8080
然后在不同的终端上运行“服务 2”,如下所示:
java -jar \target/Distributed-Service-0.0.1-SNAPSHOT.jar \--spring.application.name=Service-2 \--server.port=8090
应用程序启动后,调用“Service 1”,/path2如下所示:
curl -i http://localhost:8080/service/path1
现在让我们看看“服务1”的日志。
INFO [Service-1,222f3b00a283c75c,222f3b00a283c75c] 41114 --- [nio-8080-exec-1] c.a.p.distributedservice.Controller : Incoming request at Service-1 for request /path1
日志包含方括号,其中包含三个部分 [Service Name, Trace Id, Span Id]。对于第一个传入的请求,由于没有传入的trace id,span id 与trace id 相同。
查看“服务 2”的日志,我们看到我们为此请求有一个新的 span id。
INFO [Service-2,222f3b00a283c75c,13194db963293a22] 41052 --- [nio-8090-exec-1] c.a.p.distributedservice.Controller : Incoming request at Service-2 at /path2
我截获了从“服务 1”发送到“服务 2”的请求,并发现传出的请求中已经存在以下标头。
x-b3-traceid:"222f3b00a283c75c", x-b3-spanid:"13194db963293a22", x-b3-parentspanid:"222f3b00a283c75c
在这里,我们看到下一个操作(对“服务 2”的调用)的跨度已经注入到标头中。这些是在客户端发出请求时由“服务 1”注入的。这意味着下一次调用“服务 2”的跨度已经从“服务 1”的客户端开始。在上面显示的标题中,“服务 1”的 span id 现在是下一个 span 的父 span id。
为了让事情更容易理解,我们可以使用名为Zipkin的拦截器工具直观地查看跟踪。
使用 Zipkin 可视化跟踪
要将 Zipkin 与应用程序集成,我们需要向应用程序添加 Zipkin 客户端依赖项。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency>
添加此依赖项后,Zipkin 客户端默认将跟踪发送到 Zipkin 服务器的 9411 端口。让我们使用其 docker 映像启动 Zipkin 服务器。我为此创建了一个简单的 docker-compose 文件。
version: "3.1"
services:
zipkin:
image: openzipkin/zipkin:2
ports:
- "9411:9411"
我们现在可以使用docker-compose up命令启动服务器。然后,您可以在以下位置访问 UIhttp://localhost:9411/
由于我们使用的是默认端口,我们不需要指定任何属性,但是如果您打算使用不同的端口,则需要添加以下属性。
spring:
zipkin:
baseUrl: http://localhost:9411
完成后,让我们使用上面相同的命令启动两个应用程序。在向路径中的“服务 1”发出请求时,/path2我们会得到以下跟踪。
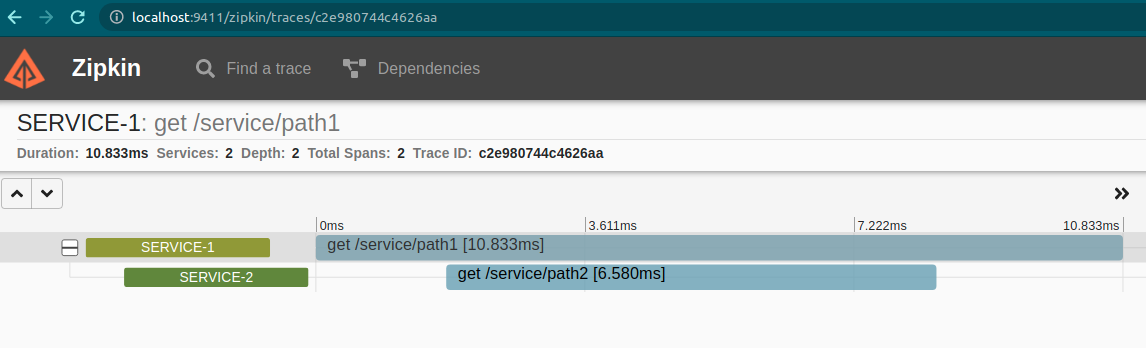
这里显示了两个服务的跨度。我们可以通过查看跨度来更深入地挖掘。
“服务 1”的跨度是一个正常的跨度,涵盖了它接收到返回响应的请求。有趣的是第二个跨度。

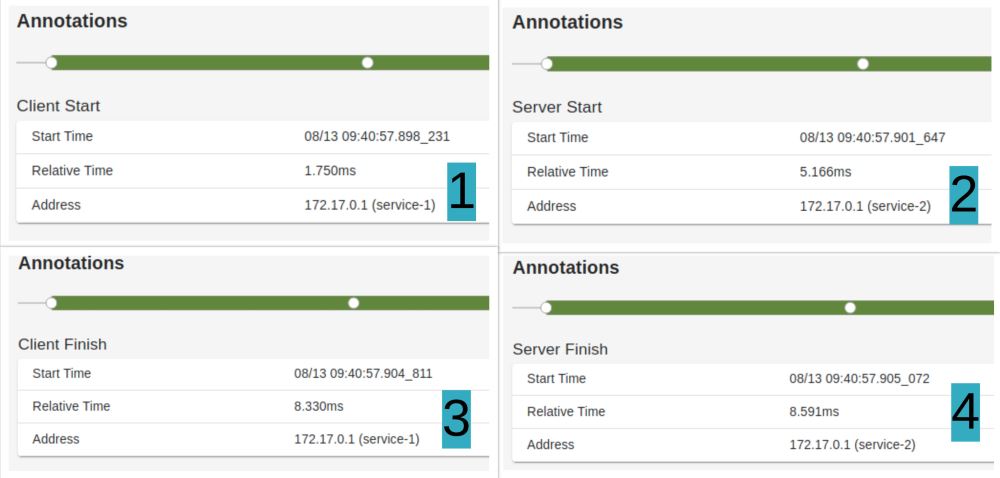
在此,跨度中有四个点。
- 第一点是指来自“服务1”的客户端何时开始请求。
- 第二点是“服务 2”开始处理请求的时间。
- 第三点是“Server 1”上的客户端完成接收响应的时间。
- 最后,“服务器 2”完成的最后一点。
因此,我们了解了如何将分布式跟踪与 Spring Cloud Sleuth 集成,并使用 Zipkin 可视化跟踪。
到此这篇关于Spring Cloud Sleuth 和 Zipkin 进行分布式跟踪使用指南的文章就介绍到这了,更多相关Spring Cloud Sleuth Zipkin 分布式跟踪内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Spring Cloud 专题之Sleuth 服务跟踪实现方法
目录 准备工作 实现跟踪 抽样收集 整合Zipkin 1.下载Zipkin 2.引入依赖配置 3.测试与分析 持久化到mysql 1.创建zipkin数据库 2.启动zipkin 3.测试与分析 在一个微服务架构中,系统的规模往往会比较大,各微服务之间的调用关系也错综复杂.通常一个有客户端发起的请求在后端系统中会经过多个不同的微服务调用阿里协同产生最后的请求结果.在复杂的微服务架构中,几乎每一个前端请求都会形成一条复杂的分布式的服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都
-
浅谈Spring-cloud 之 sleuth 服务链路跟踪
这篇文章主要讲述服务追踪组件zipkin,Spring Cloud Sleuth集成了zipkin组件. 一.简介 Add sleuth to the classpath of a Spring Boot application (see below for Maven and Gradle examples), and you will see the correlation data being collected in logs, as long as you are logging re
-
Spring Cloud Sleuth整合zipkin过程解析
这篇文章主要介绍了Spring Cloud Sleuth整合zipkin过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 SpringCloud Sleuth 简介 Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案. Spring Cloud Sleuth借鉴了Dapper的术语. Span:基本的工作单元.Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-va
-
Spring Cloud Sleuth 和 Zipkin 进行分布式跟踪使用小结
目录 什么是分布式跟踪? 分布式跟踪的关键概念 带有SpringCloudSleuth的SpringBoot示例 使用Zipkin可视化跟踪 分布式跟踪允许您跟踪分布式系统中的请求.本文通过了解如何使用 Spring Cloud Sleuth 和 Zipkin 来做到这一点. 对于一个做所有事情的大型应用程序(我们通常将其称为单体应用程序),跟踪应用程序内的传入请求很容易.我们可以跟踪日志,然后弄清楚请求是如何处理的.除了应用程序日志本身之外,我们无需查看其他任何内容. 随着时间的推移,单体应用
-
利用Spring Cloud Config结合Bus实现分布式配置中心的步骤
概述 假设现在有个需求: 我们的应用部署在10台机器上,当我们调整完某个配置参数时,无需重启机器,10台机器自动能获取到最新的配置. 如何来实现呢?有很多种,比如: 1.将配置放置到一个数据库里面,应用每次读取配置都是直接从DB读取.这样的话,我们只需要做一个DB变更,把最新的配置信息更新到数据库即可.这样无论多少台应用,由于都从同一个DB获取配置信息,自然都能拿到最新的配置. 2.每台机器提供一个更新配置信息的updateConfig接口,当需要修改配置时,挨个调用服务器的updateConf
-
Spring Cloud + Nacos + Seata整合过程(分布式事务解决方案)
目录 一.简介 二.seata-server部署 1.官网下载 2.解压到本地 3.修改配置文件 4.seata数据库初始化 5.业务数据库 6.启动seata-server 三.微服务项目集成Seata 1.引入依赖 2.配置文件 一.简介 Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务. 2019 年 1 月,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback),和社区
-
详解spring cloud config整合gitlab搭建分布式的配置中心
在前面的博客中,我们都是将配置文件放在各自的服务中,但是这样做有一个缺点,一旦配置修改了,那么我们就必须停机,然后修改配置文件后再进行上线,服务少的话,这样做还无可厚非,但是如果是成百上千的服务了,这个时候,就需要用到分布式的配置管理了.而spring cloud config正是用来解决这个问题而生的.下面就结合gitlab来实现分布式配置中心的搭建.spring cloud config配置中心由server端和client端组成, 前提:在gitlab中的工程下新建一个配置文件config
-
Spring Cloud Gateway自定义异常处理Exception Handler的方法小结
版本: Spring Cloud 2020.0.3 常见的方法有 实现自己的 DefaultErrorWebExceptionHandler 或 仅实现ErrorAttributes. 方法1: ErrorWebExceptionHandler (仅供示意) 自定义一个 GlobalErrorAttributes: @Component public class GlobalErrorAttributes extends DefaultErrorAttributes{ @Override pub
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护
-
SpringCloud之分布式配置中心Spring Cloud Config高可用配置实例代码
一.简介 当要将配置中心部署到生产环境中时,与服务注册中心一样,我们也希望它是一个高可用的应用.Spring Cloud Config实现服务端的高可用非常简单,主要有以下两种方式. 传统模式:不需要为这些服务端做任何额外的配置,只需要遵守一个配置规则,将所有的Config Server都指向同一个Git仓库,这样所有的配置内容就通过统一的共享文件系统来维护.而客户端在指定Config Server位置时,只需要配置Config Server上层的负载均衡设备地址即可, 就如下图所示的结构. 服
-
Spring Cloud Config实现分布式配置中心
在分布式系统中,配置文件散落在每个项目中,难于集中管理,抑或修改了配置需要重启才能生效.下面我们使用 Spring Cloud Config 来解决这个痛点. Config Server 我们把 config-server 作为 Config Server,只需要加入依赖: <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-ser