C语言植物大战数据结构希尔排序算法
目录
- 前言
- 一、插入排序
- 1.排序思路
- 2.单趟排序
- 详细图解
- 3.整体代码
- 4.时间复杂度
- (1).最坏情况下
- (2).最好情况下
- (3).基本有序情况下(重点)
- 5.算法特点
- 二、希尔排序
- 1.希尔从哪个方面优化的插入排序?
- 2.排序思路
- 3.预排序
- 4.正式排序
- 5.整体代码
- 6.时间复杂度
- (1).while循环的复杂度
- (2).每组gap的时间复杂度
- 结论:
“至若春和景明,波澜不惊,上下天光,一碧万顷,沙鸥翔集,锦鳞游泳,岸芷汀兰,郁郁青青。”
C语言朱武大战数据结构专栏
C语言植物大战数据结构快速排序图文示例
C语言植物大战数据结构堆排序图文示例
C语言植物大战数据结构二叉树递归
前言
学习希尔排序要先学习插入排序,希尔排序是在插入排序上的优化,可以这么说,插入排序你只要会了,希尔排序的学习也就是水到渠成。
一、插入排序
假如给你以下代码,让你对 5 4 3 2 1 排升序,你会怎么排?会怎么写?
5 4 3 2 1
void InsertSort(int* a, int n)
{
//排序代码
}
int main()
{
int arr[] = { 5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
InsertSort(arr, sz);
return 0;
}
1.排序思路
思路:总体来说是分治思想,把大问题化为小问题来解决。想让5,4,3,2,1有序。
1.第一趟:从下标为1的位置依次往后开始,先让5,4为升序
2.第二趟:来到下标为2的位置,让5,4,3为升序
3.第三趟:来到下标为3的位置,让5,4,3,2为升序
4.第四趟:来到下标为3的位置,让5,4,3,2,1为升序
这样下来,总体就都为升序了
所以总体来说,在最坏情况下。5个数排了(5-1)躺就有序了.
所以最坏情况下n个数排n-1躺才能有序。
2.单趟排序
万物归根,学习任何排序先从单趟排序开始。
可以说关键思想在单躺排序中。
以第三趟排序为例。因为这趟排序有画图意义
思路:
第三趟:来到下标为3的位置,让5,4,3,2为升序
1.起始状态。因为能走到第三趟排序,说明第一趟和第二趟已经排好序了,以红色线分割这时的数据为3 4 5 2 1
2.定义指针end指向有序序列的最后一个数,让tmp保存end+1位置的值。(这样可以防止end+1指向的值被覆盖后找不到)

3.开始打擂台赛。比较tmp的值和end的值的大小,然后end–。把比tmp大的值依次往后挪动。直到 end < 0越界 或者 tmp比end指向的值大时,单趟排序才完成。
详细图解
(1). tmp为 2 小于 5, 执行a[end+ 1] = a[end];把end+1上的值覆盖。end = end - 1。

(2). 2小于 4,继续重复以上步骤。

(3).2小于 4,继续重复以上步骤。
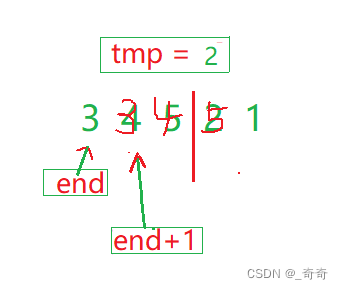
(4).end此时越界。直接跳出循环,将tmp赋值给a[end + 1];
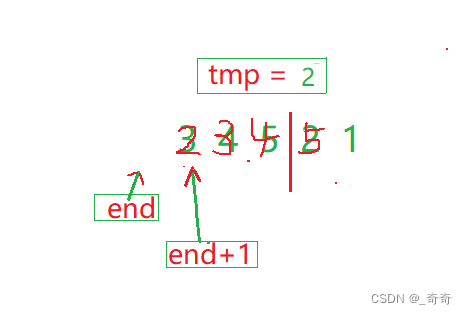
这样就完成了单趟排序的解释。
3.整体代码
#include <stdio.h>
void InsertSort(int* a, int n)
{
int i = 0;
//总共n-1躺排序
for (i = 0; i < n - 1; i++)
{
//单趟排序
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
//打擂台赛
if (tmp < a[end])
{
a[end + 1] = a[end];
end = end - 1;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
int main()
{
int arr[] = { 5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
InsertSort(arr, sz);
return 0;
}
4.时间复杂度
为了更好的展开对希尔排序叙述,不得不说一下插入排序的时间复杂度。
(1).最坏情况下
最坏情况下:对降序排降序。比如对5 4 3 2 1排升序。1.假如有n个降序的数。需要排n-1躺。
2.第1趟比较1次,第2趟比较2次,第3躺比较3次。第n-1躺排n-1次。
3.由 等差数列 前n项和公式 (首项 + 末项) * 项数 / 2 得。
T(n) = (n-1)*(1 + n - 1)/2
T(n) = (n-1)*n / 2
所以最坏情况下时间复杂度为(N-1)*N / 2。
4.由大O渐进法表示为O(N2)。
(2).最好情况下
最好情况下:对升序排升序。比如对1 2 3 4 5排升序。
这时,假如有n个元素。只需要对数组遍历一遍就够了,一遍也就是N-1次。
所以时间复杂度为O(N)
(3).基本有序情况下(重点)
例如:2 3 1 5 4
这个时候排升序,大概时间复杂度在 N ~ N2 之间接近 O(N).
5.算法特点
1.是稳定排序
2.代码简单,易实现
3.在数据接近有序 或者 已经有序的情况下,时间复杂度为O(N)
二、希尔排序
因 D.L.Shell 大佬于 1959 年提出而得名。
希尔排序(Shell’s Sort)是插入排序的一种又称“缩小增量排序”,是直接插入排序算法的一种更高效的改进版本。——百度百科
假如给你以下数据和代码,让你写希尔法排 升序,你会怎么写?你会怎么排?
9,8,7,6,5,4,3,2,1
void ShellSort(int* a, int n)
{
//排序代码
}
int main()
{
int arr[] = { 9,1,2,5,7,4,1,6,3,5 };
int sz = sizeof(arr) / sizeof(arr[0]);
ShellSort(arr, sz);
return 0;
}
1.希尔从哪个方面优化的插入排序?
1.因为插入排序有2个特性:当待排序的个数基本有序 和 数据个数较少 时 插入效率较高。
2.所以希尔排序基于这2个特性,先依据间隔(gap)对数据分成各个小组,然后对各组进行预排序,使得数据基本有序,最后再进行一次普通的插入排序使数据整体有序。
2.排序思路
排序实质:实质是采用分组插入的方法。
其实还是插入排序的思路。只是把数据分割为好几组。然后对每组进行插入排序。
整体思路:
1.算法先将要排序的一组数按某个增量gap分成若干组,每组中记录的下标相差gap.
2.对每组中全部元素进行预排序,然后再用一个较小的增量对它进行分组,在每组中再进行预排序。
3.当增量 等于1 时,整个要排序的数被分成一组,排序完成。(这时候相当于 普通的插入排序 了)
3.预排序
以以下10个元素为例。
9,1,2,5,7,4,1,6,3,5
预排序:是对各个间隔(gap) 不为1 的小组 进行直接插入排序。要理解这句话请继续往下看。
关于多少间隔分一组这个问题,怎么分?不要想那么多,按照以下规则分,你就自然懂了。分组规则:
1.间隔(gap)每次一半一半的分。直到最后gap == 1.
2.这样分其实每次都是折半的,常识来说:折半的时间复杂度都为O(LogN).
#include <stdio.h>
//希尔排序
void ShellSort(int* a, int n)
{
//预排序
int gap = n;
while (gap > 1)
{
//每次gap折半
gap = gap / 2;
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
ShellSort(arr, sz);
return 0;
}
以上例子有10个数。那就可以达到5个间隔分一组。2个间隔分一组。还有最后的1个间隔分一组(预排序不包括gap == 1这一组)。
1.gap == 5的分一组进行间隔为5的插入排序。
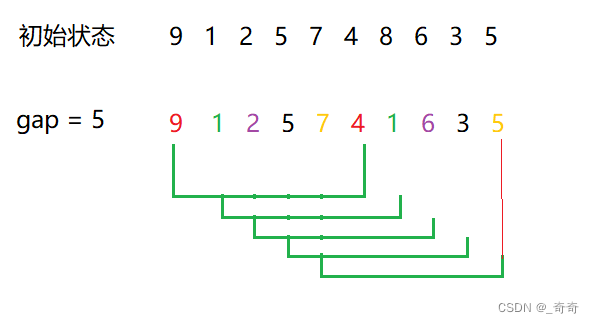
此时排完序结果为 4 1 2 3 5 9 8 6 5 7
2.gap == 2的分一组,进行间隔(gap)为2的插入排序

此时排完序结果为 2 1 4 3 5 6 5 7 8 9
这时预排序已经完成。数据基本接近有序开始进行gap为1的插入排序。
4.正式排序
此时gap == 1.直接插入排序

5.整体代码
实质:其实就是加了一个预排序,然后把 插入排序任何为1的地方替换为 gap。

#include <stdio.h>
//希尔排序
void ShellSort(int* a, int n)
{
//预排序
int gap = n;
while (gap > 1)
{
gap = gap / 2;
//进行间隔为gap的插入排序
int i = 0;
for (i = 0; i < n - gap; i++)
{
//单趟排序
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end = end - gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
ShellSort(arr, sz);
return 0;
}
6.时间复杂度
在严蔚敏老师的书上没有具体说怎么算。因为涉及一些数学上尚未解决的难题。
只给了个结论,时间复杂度为O(N3/2)
在网上有一个很巧计算方法。只是估算。仅供参考
(1).while循环的复杂度
1.假如有n个数据。n一直初以2.最后要等于1.所以公式为n / 2 / 2 / 2 / 2 / 2… = 1.
2.所以设需要初以 x 个2。也就是要执行 x 次。所以n = 2x.
所以 x = Log2n.
3.每次gap减半的 ,也就是while循环的 时间复杂度就是Log2N
int gap = n;
while (gap > 1)
{
//每次gap折半
gap = gap / 2;
}
(2).每组gap的时间复杂度
以下说法只是估算。
在预排序阶段。gap很大
1.gap很大很大时,数据跳的很快,差不多时间复杂度为O(N).正式排序时,gap == 1.
2.gap很小,因为数据接近有序,所以时间复杂度也差不多是O(N)
结论:
所以整个代码的时间复杂度为O(N*LogN).
希尔排序空间复杂度也是O(1),因为还是只需要一个辅助空间tmp。
以上就是C语言希尔排序算法实现植物大战示例的详细内容,更多关于C语言希尔排序的资料请关注我们其它相关文章!
相关推荐
-

Android植物大战僵尸小游戏
Android植物大战僵尸小游戏全部内容如下: 相关下载:Android植物大战僵尸小游戏 具体代码如下所示: package com.example.liu.mygame; import com.example.liu.mygame.global.Config; import com.example.liu.mygame.tools.DeviceTools; import com.example.liu.mygame.view.GameView; import android.os.Bundl
-
C++实现希尔排序(ShellSort)
本文实例为大家分享了C++实现希尔排序的具体代码,供大家参考,具体内容如下 一.思路: 希尔排序:又称缩小增量排序,是一种改进的插入排序算法,是不稳定的. 设排序元素序列有n个元素,首先取一个整数gap<n作为间隔,将全部元素分为gap个子序列,所有距离为gap的元素放在同一个子序列中,在每一个子序列中分别施行直接插入排序.然后缩小间隔gap,重复上述的子序列和排序工作. 二.实现程序: #include <iostream> using namespace std; const int
-
python实现植物大战僵尸游戏实例代码
开发思路 完整项目地址:https://github.com/371854496/... 觉得还OK的话,点下Star,作者不易,thank you! 实现方法 1.引入需要的模块,配置图片路径,设置界面宽高背景颜色,创建游戏主入口. #1引入需要的模块 import pygame import random #1配置图片地址 IMAGE_PATH = 'imgs/' #1设置页面宽高 scrrr_width=800 scrrr_height =560 #1创建控制游戏结束的状态 GAMEOVE
-
C++实现八个常用的排序算法:插入排序、冒泡排序、选择排序、希尔排序等
本文实现了八个常用的排序算法:插入排序.冒泡排序.选择排序.希尔排序 .快速排序.归并排序.堆排序和LST基数排序 首先是算法实现文件Sort.h,代码如下: /* * 实现了八个常用的排序算法:插入排序.冒泡排序.选择排序.希尔排序 * 以及快速排序.归并排序.堆排序和LST基数排序 * @author gkh178 */ #include <iostream> template<class T> void swap_value(T &a, T &b) { T t
-
教你用Python写一个植物大战僵尸小游戏
一.前言 上次写了一个俄罗斯方块,感觉好像大家都看懂了,这次就更新一个植物大战僵尸吧 二.引入模块 import pygame import random 三.完整代码 配置图片地址 IMAGE_PATH = 'imgs/' 设置页面宽高 scrrr_width = 800 scrrr_height = 560 创建控制游戏结束的状态 GAMEOVER = False 图片加载报错处理 LOG = '文件:{}中的方法:{}出错'.format(__file__, __name__) 创建地图类
-
C++实现希尔排序算法实例
目录 1.代码模板 2.算法介绍 3.实例 1.代码模板 // 希尔排序(Shell Sort) void ShellSort(SqList *L) { int i, j; int increment = L->length; // 先让增量初始化为序列的长度 do { increment = increment / 3 + 1; // 计算增量的值 for (i = increment + 1; i <= L->length; i ++ ) { if (L->arr[i] <
-
C语言植物大战数据结构希尔排序算法
目录 前言 一.插入排序 1.排序思路 2.单趟排序 详细图解 3.整体代码 4.时间复杂度 (1).最坏情况下 (2).最好情况下 (3).基本有序情况下(重点) 5.算法特点 二.希尔排序 1.希尔从哪个方面优化的插入排序? 2.排序思路 3.预排序 4.正式排序 5.整体代码 6.时间复杂度 (1).while循环的复杂度 (2).每组gap的时间复杂度 结论: “至若春和景明,波澜不惊,上下天光,一碧万顷,沙鸥翔集,锦鳞游泳,岸芷汀兰,郁郁青青.” C语言朱武大战数据结构专栏 C语言植物
-
C语言植物大战数据结构二叉树递归
目录 前言 一.二叉树的遍历算法 1.构造二叉树 2.前序遍历(递归图是重点.) 3.中序遍历 4.后序遍历 二.二叉树遍历算法的应用 1.求节点个数 3.求第k层节点个数 4.查找值为x的节点 5.二叉树销毁 6.前序遍历构建二叉树 7.判断二叉树是否是完全二叉树 8.求二叉树的深度 三.二叉树LeetCode题目 1.单值二叉树 2. 检查两颗树是否相同 3. 对称二叉树 4.另一颗树的子树 6.反转二叉树 " 梧桐更兼细雨,到黄昏.点点滴滴." C语言朱武大战数据结构专栏 C语言
-
C语言植物大战数据结构快速排序图文示例
目录 快速排序 一.经典1962年Hoare法 1.单趟排序 2.递归左半区间和右半区间 3.代码实现 二.填坑法(了解) 1.单趟思路 2.代码实现 三.双指针法(最佳方法) 1.单趟排序 2.具体思路 3.代码递归图 4.代码实现 四.三数取中优化(最终方案) 1.三数取中 2.代码实现(最终代码) 五.时间复杂度(重点) 1.最好情况下 2.最坏情况下 3.空间复杂度 六.非递归写法 1.栈模拟递归快排 2.队列实现快排 浅浅总结下 “田家少闲月,五月人倍忙”“夜来南风起,小麦覆陇黄” C
-
C语言植物大战数据结构二叉树堆
目录 前言 堆的概念 创建结构体 初始化结构体 销毁结构体 向堆中插入数据 1.堆的物理结构和逻辑结构 2.完全二叉树下标规律 3.插入数据思路 依次打印堆的值 删除堆顶的值 判断堆是否为空 求堆中有几个元素 得到堆顶的值 堆排序 总体代码 Heap.h Heap.c Test.c “竹杖芒鞋轻胜马,谁怕?一蓑烟雨任平生” C语言朱武大战数据结构专栏 C语言植物大战数据结构快速排序图文示例 C语言植物大战数据结构希尔排序算法 C语言植物大战数据结构堆排序图文示例 C语言植物大战数据结构二叉树递归
-
C语言植物大战数据结构堆排序图文示例
目录 TOP.堆排序前言 一.向下调整堆排序 1.向下调整建堆 建堆的技巧 建堆思路代码 2.向下调整排序 调整思路 排序整体代码 3.时间复杂度(难点) 向下建堆O(N) 向下调整(N*LogN) 二.向上调整堆排序 1.向上调整建堆 2.建堆代码 “大弦嘈嘈如急雨,小弦切切如私语”“嘈嘈切切错杂弹,大珠小珠落玉盘” TOP.堆排序前言 什么是堆排序?假如给你下面的代码让你完善堆排序,你会怎么写?你会怎么排? void HeapSort(int* a, int n) { } int main(
-
php实现希尔排序算法的方法分析
本文实例讲述了php实现希尔排序算法的方法.分享给大家供大家参考,具体如下: 虽然现在各种程序语言都有其各自强大的排序库函数,但是这些底层实现也都是利用这些基础或高级的排序算法. 理解这些复杂的排序算法还是很有意思的,体会这些排序算法的精妙~ 希尔排序(shell sort):希尔排序是基于插入排序的,区别在于插入排序是相邻的一个个比较(类似于希尔中h=1的情形),而希尔排序是距离h的比较和替换. 希尔排序中一个常数因子n,原数组被分成各个小组,每个小组由h个元素组成,很可能会有多余的元素.当然
-
Python实现希尔排序算法的原理与用法实例分析
本文实例讲述了Python实现希尔排序算法的原理与用法.分享给大家供大家参考,具体如下: 希尔排序(Shell Sort)是插入排序的一种.也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本. 希尔排序的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个"增量"的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序.因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高
-
c语言5个常用的排序算法实例代码
1.插入排序 基本思想:插入排序就是每一步都将一个待排数据按其大小插入到已经排序的数据中的适当位置,直到全部插入完毕. void insertSort(vector<int>& nums) { int k = 0; for (int i = 0; i < nums.size(); ++i) { int temp = nums[i]; int j = i; for (; j > 0 && temp < nums[j-1]; --j) nums[j] =
-
python数据结构的排序算法
目录 十大经典的排序算法 一.交换排序 1.冒泡排序(前后比较-交换) 2.快速排序(选取一个基准值,小数在左大数在右) 二.插入排序 1.简单插入排序(逐个插入到前面的有序数中) 2.希尔排序(从大范围到小范围进行比较-交换) 三.选择排序 1.简单选择排序(选择最小的数据放在前面) 2.堆排序(利用最大堆和最小堆的特性) 四.归并排序 五.其他排序 1.计数排序(字典计数-还原) 2.桶排序(链表) 3.基数排序 十大经典的排序算法 数据结构中的十大经典算法:冒泡排序.快速排序.简单插入排序
-
C语言完整实现12种排序算法(小结)
目录 1.冒泡排序 2.插入排序 3.折半插入排序 4.希尔排序 5.选择排序 6.鸡尾酒排序 7.堆排序 8.快速排序 9.归并排序 10.计数排序 11.桶排序 12.基数排序 1.冒泡排序 思路:比较相邻的两个数字,如果前一个数字大,那么就交换两个数字,直到有序.时间复杂度O(n^2),稳定性:这是一种稳定的算法.代码实现: void bubble_sort(int arr[],size_t len){ size_t i,j; for(i=0;i<len;i++){ bool hasSwa