scrapy-redis分布式爬虫的搭建过程(理论篇)
1. 背景
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
2. 环境
- 系统:win7
- scrapy-redis
- redis 3.0.5
- python 3.6.1
3. 原理
3.1. 对比一下scrapy 和 Scrapy-redis 的架构图。
scrapy架构图:
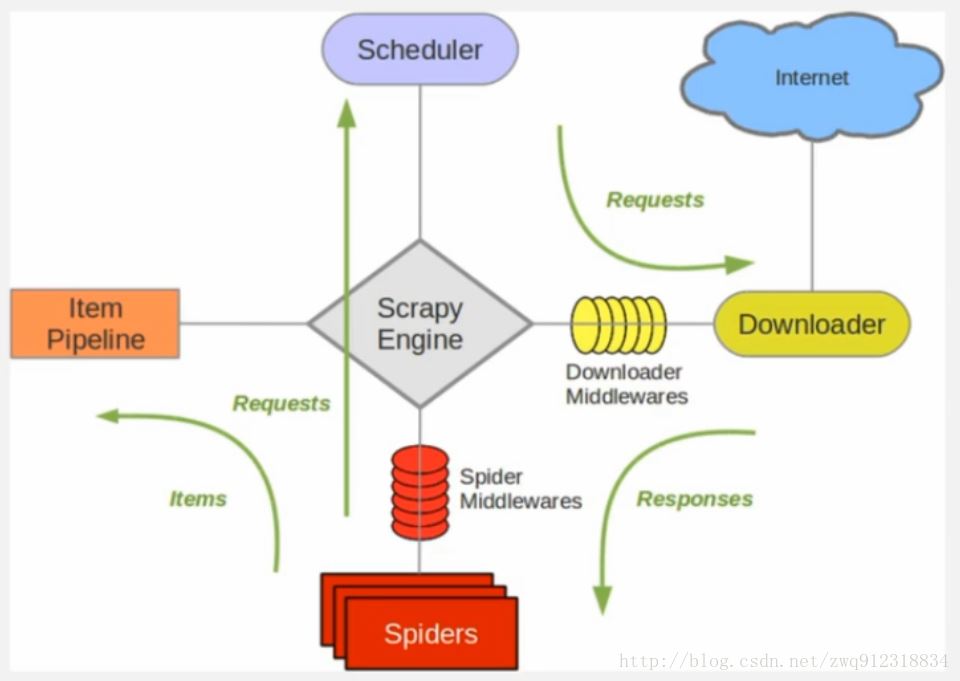
scrapy-redis 架构图:
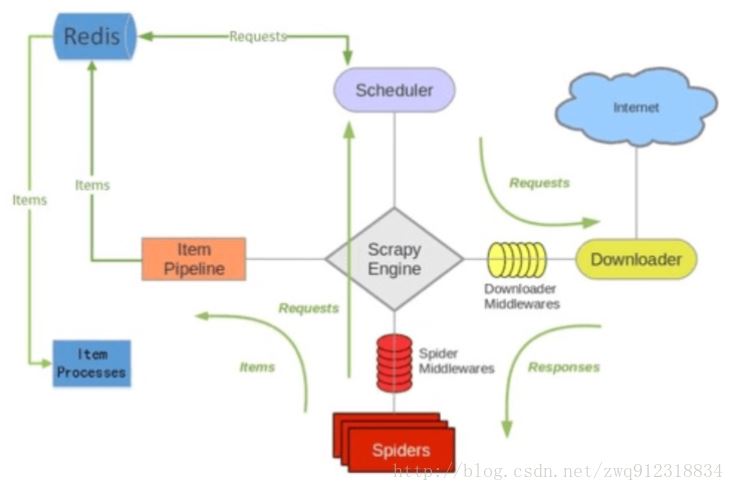
多了一个redis组件,主要影响两个地方:第一个是调度器。第二个是数据的处理。 3.2. Scrapy-Redis分布式策略。
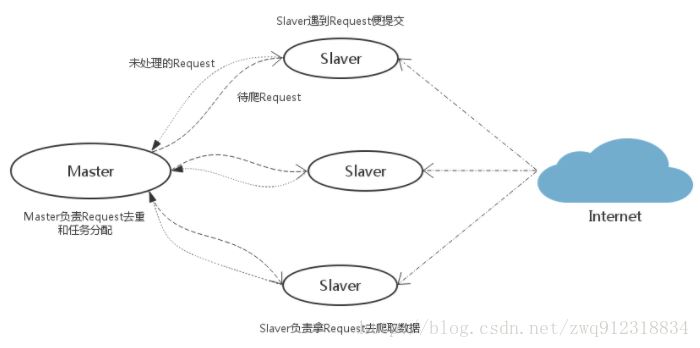
作为一个分布式爬虫,是需要有一个Master端(核心服务器)的,在Master端,会搭建一个Redis数据库,用来存储start_urls、request、items。Master的职责是负责url指纹判重,Request的分配,以及数据的存储(一般在Master端会安装一个mongodb用来存储redis中的items)。出了Master之外,还有一个角色就是slaver(爬虫程序执行端),它主要负责执行爬虫程序爬取数据,并将爬取过程中新的Request提交到Master的redis数据库中。
如上图,假设我们有四台电脑:A, B, C, D ,其中任意一台电脑都可以作为 Master端 或 Slaver端。整个流程是:
- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
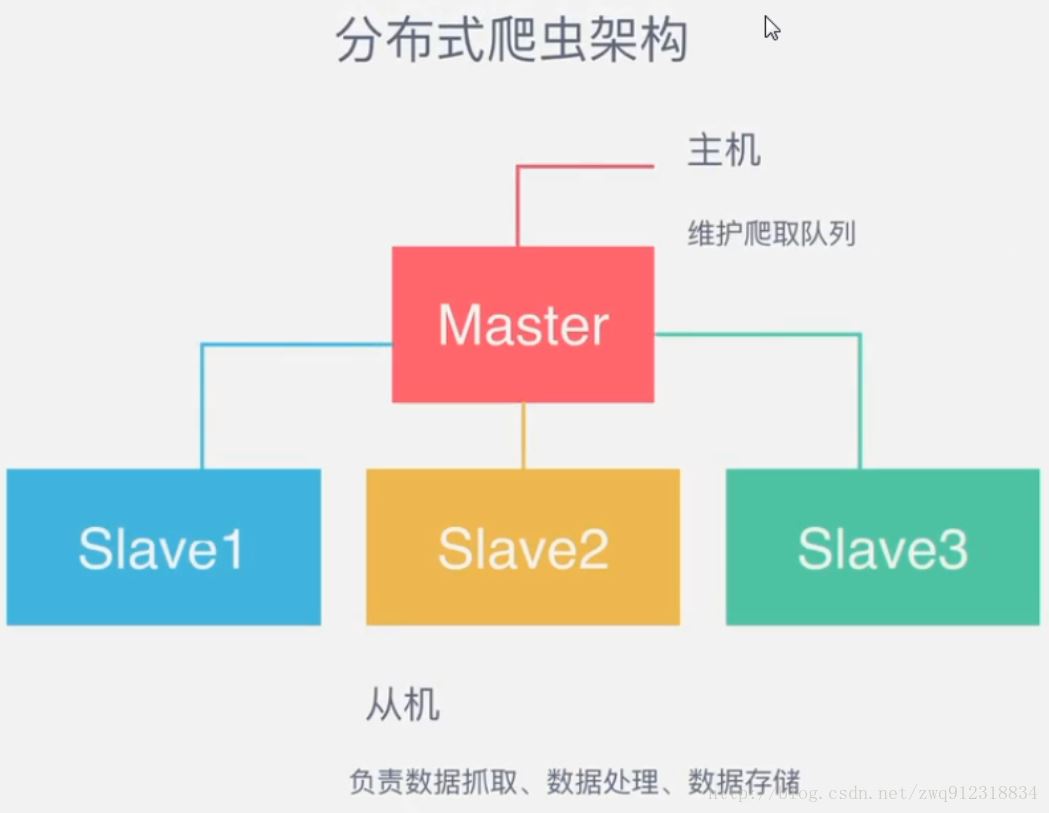

Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
4. 运行流程
第一步:在slaver端的爬虫中,指定好 redis_key,并指定好redis数据库的地址,比如:
class MySpider(RedisSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'amazon' redis_key = 'amazonCategory:start_
# 指定redis数据库的连接参数 'REDIS_HOST': '172.16.1.99', 'REDIS_PORT': 6379,
第二步:启动slaver端的爬虫,爬虫进入等待状态,等待 redis 中出现 redis_key ,Log如下:
2017-12-12 15:54:18 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapybot)
2017-12-12 15:54:18 [scrapy.utils.log] INFO: Overridden settings: {'SPIDER_LOADER_WARN_ONLY': True}
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-12-12 15:54:18 [myspider_redis] INFO: Reading start URLs from redis key 'myspider:start_urls' (batch size: 110, encoding: utf-8
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'redisClawerSlaver.middlewares.ProxiesMiddleware',
'redisClawerSlaver.middlewares.HeadersMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled item pipelines:
['redisClawerSlaver.pipelines.ExamplePipeline',
'scrapy_redis.pipelines.RedisPipeline']
2017-12-12 15:54:18 [scrapy.core.engine] INFO: Spider opened
2017-12-12 15:54:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 15:55:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 15:56:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
第三步:启动脚本,往redis数据库中填入redis_key(start_urls)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
# 将start_url 存储到redis中的redis_key中,让爬虫去爬取
redis_Host = "172.16.1.99"
redis_key = 'amazonCategory:start_urls'
# 创建redis数据库连接
rediscli = redis.Redis(host = redis_Host, port = 6379, db = "0")
# 先将redis中的requests全部清空
flushdbRes = rediscli.flushdb()
print(f"flushdbRes = {flushdbRes}")
rediscli.lpush(redis_key, https://www.baidu.com)

第四步:slaver端的爬虫开始爬取数据。Log如下:
2017-12-12 15:56:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
parse url = https://www.baidu.com, status = 200, meta = {'download_timeout': 25.0, 'proxy': 'http://proxy.abuyun.com:9020', 'download_slot': 'www.baidu.com', 'download_latency': 0.2569999694824219, 'depth': 7}
parse url = https://www.baidu.com, status = 200, meta = {'download_timeout': 25.0, 'proxy': 'http://proxy.abuyun.com:9020', 'download_slot': 'www.baidu.com', 'download_latency': 0.8840000629425049, 'depth': 8}
2017-12-12 15:57:18 [scrapy.extensions.logstats] INFO: Crawled 2 pages (at 2 pages/min), scraped 1 items (at 1 items/min)
第五步:启动脚本,将redis中的items,转储到mongodb中。
这部分代码,请参照:scrapy-redis分布式爬虫的搭建过程(代码篇)
5. 环境安装以及代码编写
5.1. scrapy-redis环境安装
pip install scrapy-redis

代码位置:后面可以进行修改定制。
5.2. scrapy-redis分布式爬虫编写
第一步,下载官网的示例代码,地址:https://github.com/rmax/scrapy-redis (需要安装过git)
git clone https://github.com/rmax/scrapy-redis.git
官网提供了两种示例代码,分别继承自 Spider + redis 和 CrawlSpider + redis
第二步,根据官网提供的示例代码进行修改。
到此这篇关于scrapy-redis分布式爬虫的搭建过程(理论篇)的文章就介绍到这了,更多相关scrapy redis分布式爬虫搭建内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Scrapy基于scrapy_redis实现分布式爬虫部署的示例
准备工作 1.安装scrapy_redis包,打开cmd工具,执行命令pip install scrapy_redis 2.准备好一个没有BUG,没有报错的爬虫项目 3.准备好redis主服务器还有跟程序相关的mysql数据库 前提mysql数据库要打开允许远程连接,因为mysql安装后root用户默认只允许本地连接,详情请看此文章 部署过程 1.修改爬虫项目的settings文件 在下载的scrapy_redis包中,有一个scheduler.py文件,里面有一个Scheduler类,是用来调
-

Scrapy-redis爬虫分布式爬取的分析和实现
Scrapy Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来. 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件.它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用.scrapy-redi
-
scrapy-redis分布式爬虫的搭建过程(理论篇)
1. 背景 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件). 2. 环境 系统:win7 scrapy-redis redis 3.0.5 python 3.6.1 3. 原理 3.1. 对比一下scrapy 和 Scrapy-redis 的架构图. scrapy架构图: scrapy-redis 架构图: 多了一个redis组件,主要影响两个地方:第一个是调度器.第二个是数
-
scrapy在python爬虫中搭建出错的解决方法
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了.一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题.有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点. 问题描述: 安装位置: 环境变量: 解决办法: 文件命名叫 scrapy.py,明显和scrapy自己的包名冲突了,这里 class StackOverFlowSpider(scrapy.Spider) 会直接找当前文件(scrapy.py
-
SpringBoot+MyBatisPlus+Vue 前后端分离项目快速搭建过程(前端篇)
后端篇 SpringBoot+MyBatisPlus+Vue 前后端分离项目快速搭建[后端篇][快速生成后端代码.封装结果集.增删改查.模糊查找][毕设基础框架] 前端篇 创建vue项目 1.找个文件夹进入命令行,输入:vue create vue-front 2.直接回车,等待片刻,稍微有点小久 3.根据提示指令测试 打开浏览器输入:http://localhost:8080/ 安装所需工具 安装的工具会有点多,为了提供更好的拓展性,可以自主选择安装(不建议),后面的代码中都是使用到了,不安装
-
redis复制集群搭建的实现
目录 前言 环境准备 搭建过程 问题总结 前言 redis 复制集群是开发中一种比较常用的集群模式,本篇演示如何在centos7上快速搭建一个redis复制集群: 环境准备 1.基于centos7系统的服务器(或者云服务器): 2.redis 安装包: 搭建过程 由于资源限制,本篇将在一台服务器上搭建,通过不同的端口号进行区分: 1.上传redis安装包到指定目录下(并解压) 2.在当前目录下,创建三个目录 在当前目录,分别创建 7001,7002,7003 三个文件目录 3.将redis解压包
-
使用Docker Swarm搭建分布式爬虫集群的方法示例
在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况.此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新? 有时候爬虫只需要在一个服务器上面运行,有时候需要在200个服务器上面运行.你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在Redis里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行? A爬虫已经在所有服务器上面部署了,现在又做了一个B爬虫,你是不是又得依次
-
分布式Redis Cluster集群搭建与Redis基本用法
目录 Redis集群搭建 Redis是啥 集群(Cluster) RedisCluster说明 RedisCluster节点 RedisCluster集群模式 不能保证一致性 创建和使用Redis集群 部署三个主节点 非docker docker安装 创建集群 Redis入门 Redis中的数据类型 字符串(string) 哈希(Hash) 列表(Lists) 集合(Set) 有序集合(sortedset) Redis 集群搭建 Redis 是啥 Redis(全称 REmote DIctiona
-
redis集群搭建过程(非常详细,适合新手)
目录 redis集群搭建 一.Redis Cluster(Redis集群)简介 二.集群搭建需要的环境 三.集群搭建具体步骤如下(注意要关闭防火墙) 四.结语 redis集群搭建 在开始redis集群搭建之前,我们先简单回顾一下redis单机版的搭建过程 下载redis压缩包,然后解压压缩文件: 进入到解压缩后的redis文件目录(此时可以看到Makefile文件),编译redis源文件: 把编译好的redis源文件安装到/usr/local/redis目录下,如果/local目录下没有redi
-
Linux下Redis服务器搭建过程
系统环境 操作系统:CentOS 6.9 redis版本:redis-4.0.2安装步骤 1,安装预环境 运行以下命令安装预环境. [root@redis02 redis-4.0.2]# yum -y install gcc make 2,下载redis源代码文件并解压缩 下载完redis源代码后,运行以下命令进行解压缩. [root@redis02 softwares]# tar -xzf redis-4.0.2.tar.gz 3,redis编译 运行make命令进行编译. make命令执行完
-
Python 用Redis简单实现分布式爬虫的方法
Redis通常被认为是一种持久化的存储器关键字-值型存储,可以用于几台机子之间的数据共享平台. 连接数据库 注意:假设现有几台在同一局域网内的机器分别为Master和几个Slaver Master连接时host为localhost即本机的ip _db = redis.Reds(host='localhost', port=6379, db=0) Slaver连接时的host也为Master的ip,端口port和数据库db不写时为默认值6379.0 _db = redis.Redis(host='