Scrapy基于scrapy_redis实现分布式爬虫部署的示例
准备工作
1.安装scrapy_redis包,打开cmd工具,执行命令pip install scrapy_redis
2.准备好一个没有BUG,没有报错的爬虫项目
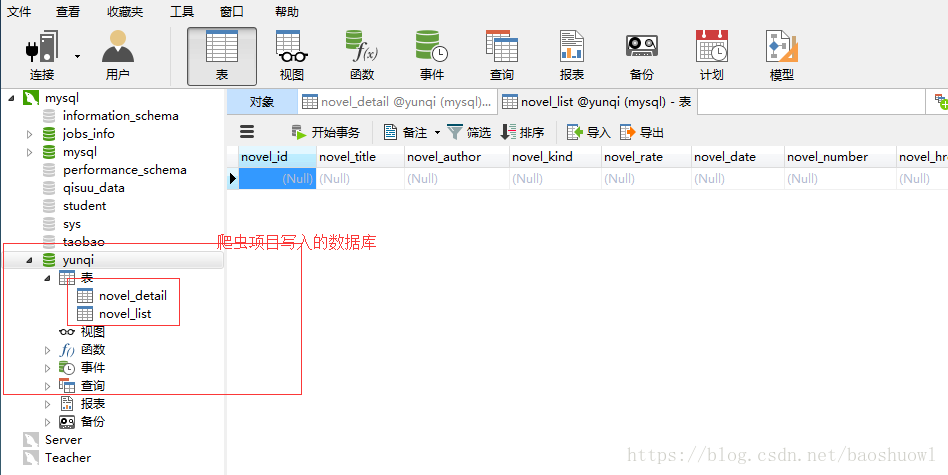
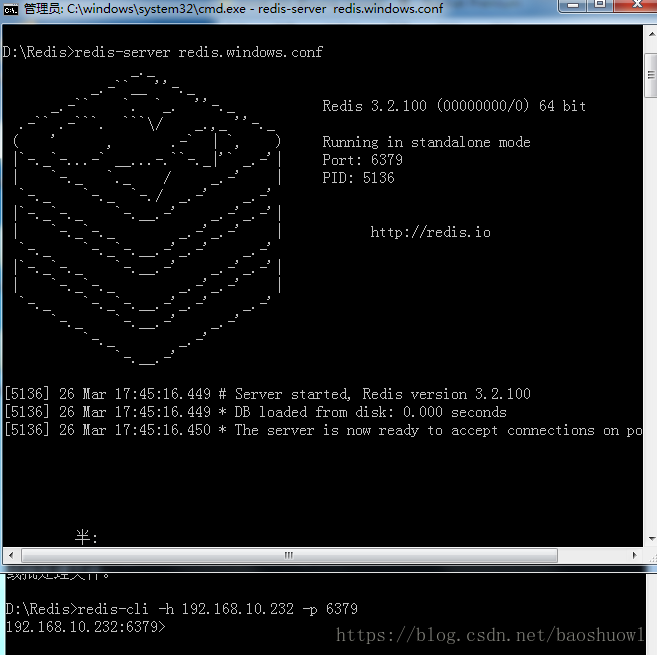
3.准备好redis主服务器还有跟程序相关的mysql数据库
前提mysql数据库要打开允许远程连接,因为mysql安装后root用户默认只允许本地连接,详情请看此文章
部署过程
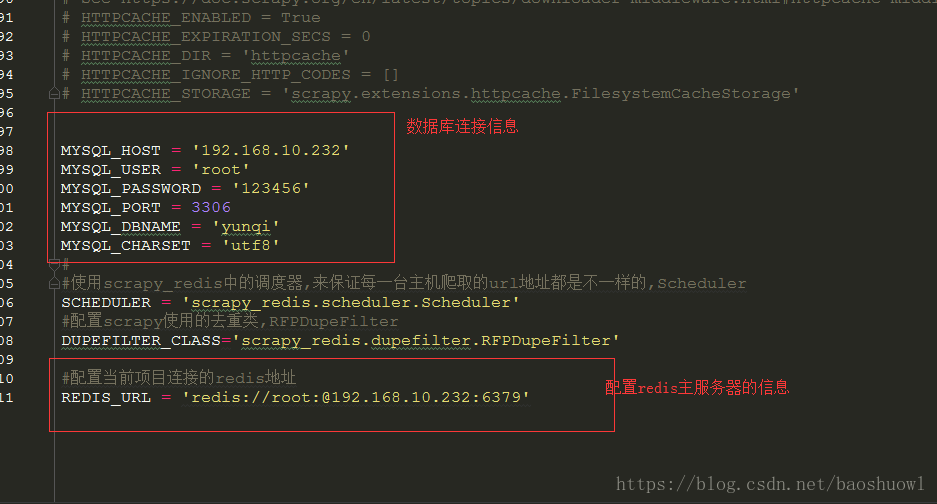
1.修改爬虫项目的settings文件
在下载的scrapy_redis包中,有一个scheduler.py文件,里面有一个Scheduler类,是用来调度url,还有一个dupefilter.py文件,里面有个类是RFPDupeFilter,是用来去重,所以要在settings任意位置文件中添加上它们

还有在scrapy_redis包中,有一个pipelines文件,里面的RedisPipeline类可以把爬虫的数据写入redis,更稳定安全,所以要在settings中启动pipelines的地方启动此pipeline

最后修改redis连接配置
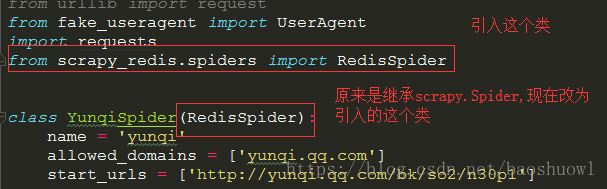
2.修改spider爬虫文件
首先我们要引入一个scrapy_redis.spider文件中的一个RedisSpider类,然后把spider爬虫文件原来继承的scrapy.Spider类改为引入的RedisSpider这个类
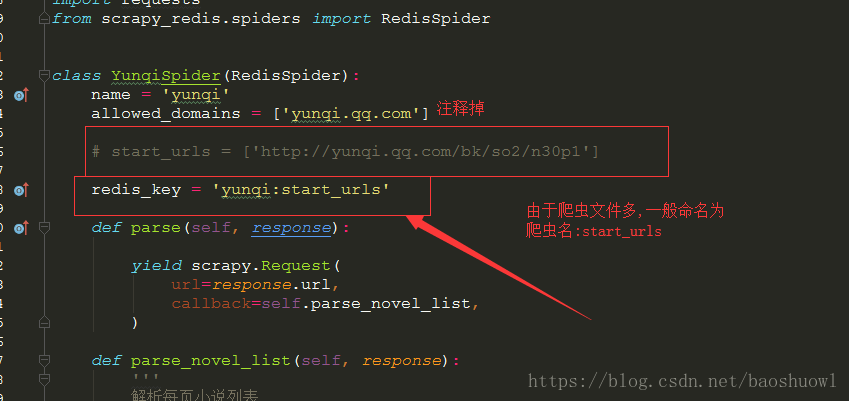
接着把原来的start_urls这句代码注释掉,加入redis_key = '自定义key值',一般以爬虫名:urls命名
测试部署是否成功
直接运行我们的项目,
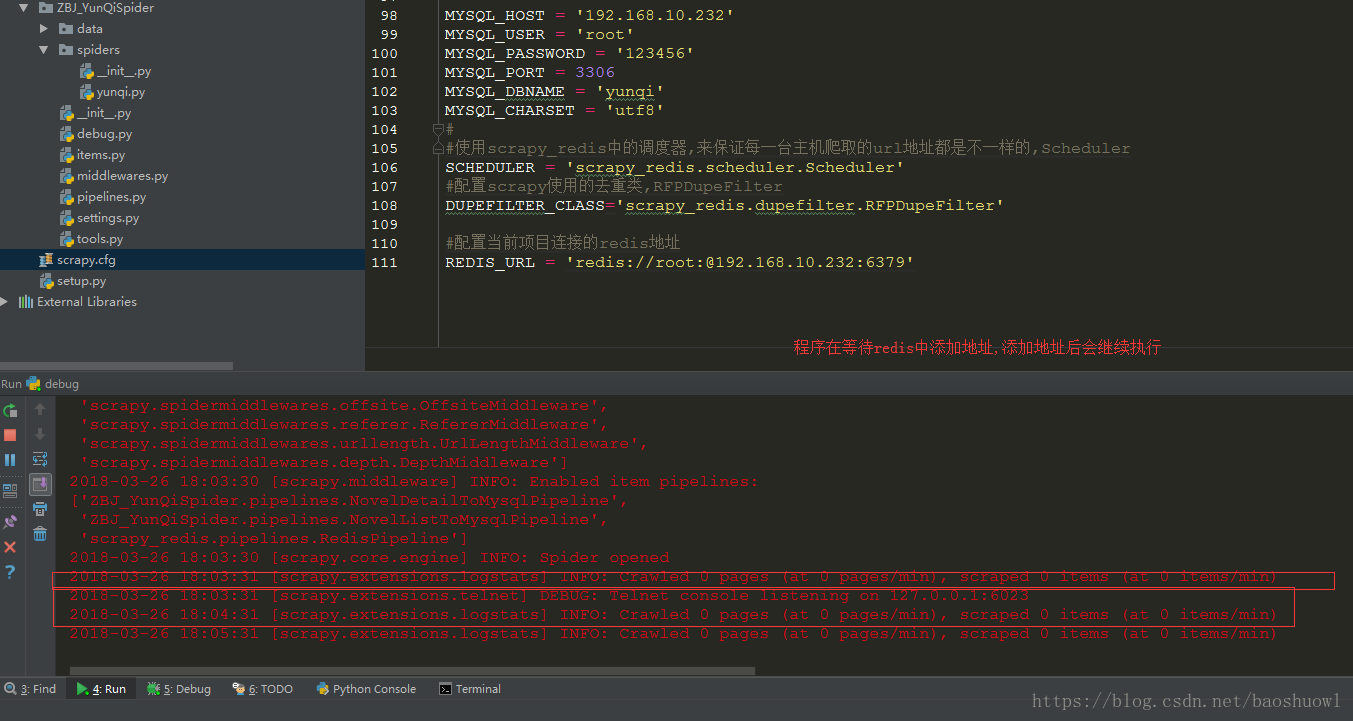
打开redis客户端在redis添加key为yunqi:start_urls的列表,值为地址
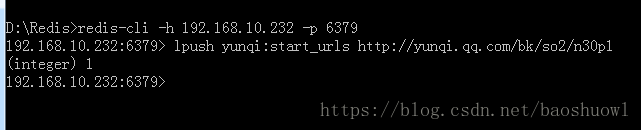
添加成功后,程序直接跑了起来
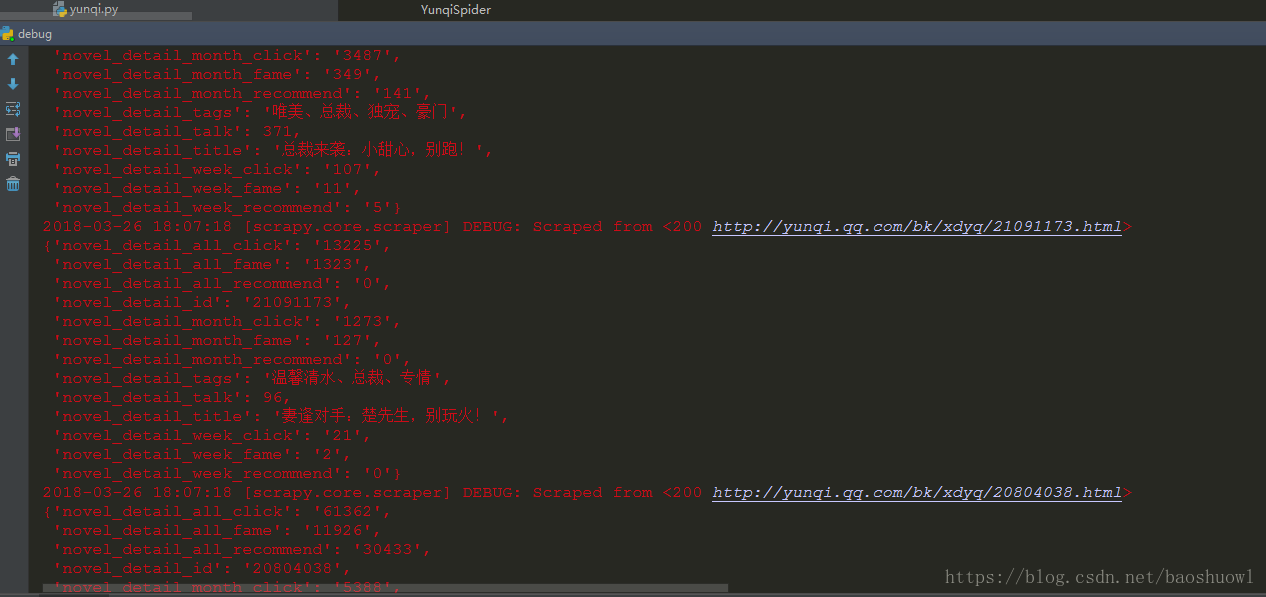
查看数据是否插入


分布式用到的代码应该是同一套代码
1) 先把项目配置为分布式
2) 把项目拷贝到多台服务器中
3) 把所有爬虫项目都跑起来
4) 在主redis-cli中lpush你的网址即可
5) 效果:所有爬虫都开始运行,并且数据还都不一样
到此这篇关于Scrapy基于scrapy_redis实现分布式爬虫部署的示例的文章就介绍到这了,更多相关Scrapy redis分布式爬虫 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Scrapy-redis爬虫分布式爬取的分析和实现
Scrapy Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来. 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件.它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用.scrapy-redi
-
Scrapy基于scrapy_redis实现分布式爬虫部署的示例
准备工作 1.安装scrapy_redis包,打开cmd工具,执行命令pip install scrapy_redis 2.准备好一个没有BUG,没有报错的爬虫项目 3.准备好redis主服务器还有跟程序相关的mysql数据库 前提mysql数据库要打开允许远程连接,因为mysql安装后root用户默认只允许本地连接,详情请看此文章 部署过程 1.修改爬虫项目的settings文件 在下载的scrapy_redis包中,有一个scheduler.py文件,里面有一个Scheduler类,是用来调
-
Java注解如何基于Redission实现分布式锁
这篇文章主要介绍了Java注解如何基于Redission实现分布式锁,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.定义注解类 @Target({ ElementType.METHOD }) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface DistributedLock { //锁名称 String lockName() default ""; /
-
scrapy爬虫部署服务器的方法步骤
目录 一.scrapy爬虫部署服务器 1.scrapyd 2.安装 2.scrapy-client 3.scrapydweb(可选) 二.实际操作(一切的操作都在scrapyd启动的情况下) 三.数据展示 四.问题与思考 五.收获 一.scrapy爬虫部署服务器 scrapy通过命令行运行一般只用于测试环境,而用于运用在生产环境则一般都部署在服务器中进行远程操作. scrapy部署服务器有一套完整的开源项目:scrapy+scrapyd(服务端)+scrapy-client(客户端)+scrap
-
python爬虫scrapy基于CrawlSpider类的全站数据爬取示例解析
一.CrawlSpider类介绍 1.1 引入 使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类.基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康 scrapy基于CrawlSpider类的全站数据爬取 1.2 介绍和使用 1.2.1 介绍 CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是 LinkExtractor()和rules
-
Java多线程及分布式爬虫架构原理解析
这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦.这一篇我们来聊一聊爬虫架构相关的内容. 前面几章内容我们的爬虫程序都是单线程,在我们调试爬虫程序的时候,单线程爬虫没什么问题,但是当我们在线上环境使用单线程爬虫程序去采集网页时,单线程就暴露出了两个致命的问题: 采集效率特别慢,单线程之间都是串行的,下一个执行动作需要等上一个执行完才能
-
使用Docker Swarm搭建分布式爬虫集群的方法示例
在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况.此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新? 有时候爬虫只需要在一个服务器上面运行,有时候需要在200个服务器上面运行.你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在Redis里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行? A爬虫已经在所有服务器上面部署了,现在又做了一个B爬虫,你是不是又得依次
-
scrapy-redis分布式爬虫的搭建过程(理论篇)
1. 背景 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件). 2. 环境 系统:win7 scrapy-redis redis 3.0.5 python 3.6.1 3. 原理 3.1. 对比一下scrapy 和 Scrapy-redis 的架构图. scrapy架构图: scrapy-redis 架构图: 多了一个redis组件,主要影响两个地方:第一个是调度器.第二个是数
-
分布式爬虫scrapy-redis的实战踩坑记录
目录 一.安装redis 1.首先要下载相关依赖 2.然后编译redis 二.scrapy框架出现的问题 1.AttributeError: TaocheSpider object has no attribute make_requests_from_url 原因: 2.ValueError: unsupported format character : (0x3a) at index 9 问题: 三.scrapy正确的源代码 1.items.py文件 2.settings.py文件 3.ta
-
爬虫技术之分布式爬虫架构的讲解
分布式爬虫架构并不是一开始就出现的.而是一个逐步演化的过程. 最开始入手写爬虫的时候,我们一般在个人计算机上完成爬虫的入门和开发,而在真实的生产环境,就不能用个人计算机来运行爬虫程序了,而是将爬虫程序部署在服务器上.利用服务器不关机的特性,爬虫可以不间断的24小时运行.单机爬虫的结构如下图. 然而,由于爬虫在爬取数据时,爬取频次并不能太快,即使是爬虫在服务器上不间断运行,效率可能也无法满足实际需求.这时候,就需要在多机上部署爬虫程序,用分布式爬虫架构,进行数据爬取.分布式爬虫的架构一般如下所示.
-
python分布式爬虫中消息队列知识点详解
当排队等待人数过多的时候,我们需要设置一个等待区防止秩序混乱,同时再有新来的想要排队也可以呆在这个地方.那么在python分布式爬虫中,消息队列就相当于这样的一个区域,爬虫要进入这个区域找寻自己想要的资源,当然这个是一定的次序的,不然数据获取就会出现重复.就下来我们就python分布式爬虫中的消息队列进行详细解释,小伙伴们可以进一步了解一下. 实现分布式爬取的关键是消息队列,这个问题以消费端为视角更容易理解.你的爬虫程序部署到很多台机器上,那么他们怎么知道自己要爬什么呢?总要有一个地方存储了他们