spring jpa设置多个主键遇到的小坑及解决
目录
- jpa设置多个主键遇到的坑
- 解决办法
- jpa遇到多主键表如何进行查询
- 1、使用 List<Map<String, Object>>的方式去接收
- 2、自定义接收类
- 3、配置联合主键
jpa设置多个主键遇到的坑
由于项目需要,对多个业务表单独另外建立对应的历史版本记录表,为了原业务表数据能原封不动记录到历史版本表,需要建立组合主键,id+历史版本号作为主键唯一约束(rid+historyVersion)。
在实体上需要设置为主键的字段加上注解,@Id,例如:
/* * 主键-RID */ @Id @Column(name = "RID", length = 36) private String rid;
这样会导致,若是该实体存在父类,那就会启动报错,初始化不了
错误信息:does not define an IdClass。
解决办法
必须要在类声名注入@IdClass(HistoryPK.class)。
实体代码例子如下:
package com.southgis.officeHouse.entity;
import java.io.Serializable;
import javax.persistence.Id;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
*
* @author Administrator
* 组合主键
*/
@Data
public class HistoryPK implements Serializable
{
private static final long serialVersionUID = 1L;
/*
* 主键-RID
*/
private String rid;
/*
* 主键-历史版本号,保存格式年份_版本号,例如2018_1
*/
private String historyVersion;
}
package com.southgis.officeHouse.entity;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.IdClass;
import javax.persistence.Index;
import javax.persistence.Table;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
/**
*
* @author Administrator
* 单位基本信息历史版本表
*/
@Data
@EqualsAndHashCode(callSuper=false)
@NoArgsConstructor
@Entity
@IdClass(HistoryPK.class)
@Table(name = "UNIT_HISTORY",indexes={
@Index(name="inx_unitHistory_orgid",columnList="ORGID")})
public class UnitHistory extends UnitBase implements Serializable
{
private static final long serialVersionUID = -4466904221026481006L;
/*
* 主键-RID
*/
@Id
@Column(name = "RID", length = 36)
private String rid;
/*
* 主键-历史版本号,保存格式年份_版本号,例如2018_1
*/
@Id
@Column(name = "HISTORY_VERSION",length=36)
private String historyVersion;
}
jpa遇到多主键表如何进行查询
数据表是原始就存在的,里面存在两个主键:

当建好实体类,然后用jpa去关联操作查询,(根据StudyId)去进行查询的时候,发现原本可以有八条不一样的记录,只是StudyId相同,其他的不同,这个时候,出来确实是八条,但是居然每一条都一样,是根据StudyId一样的数据记录里的都一条。
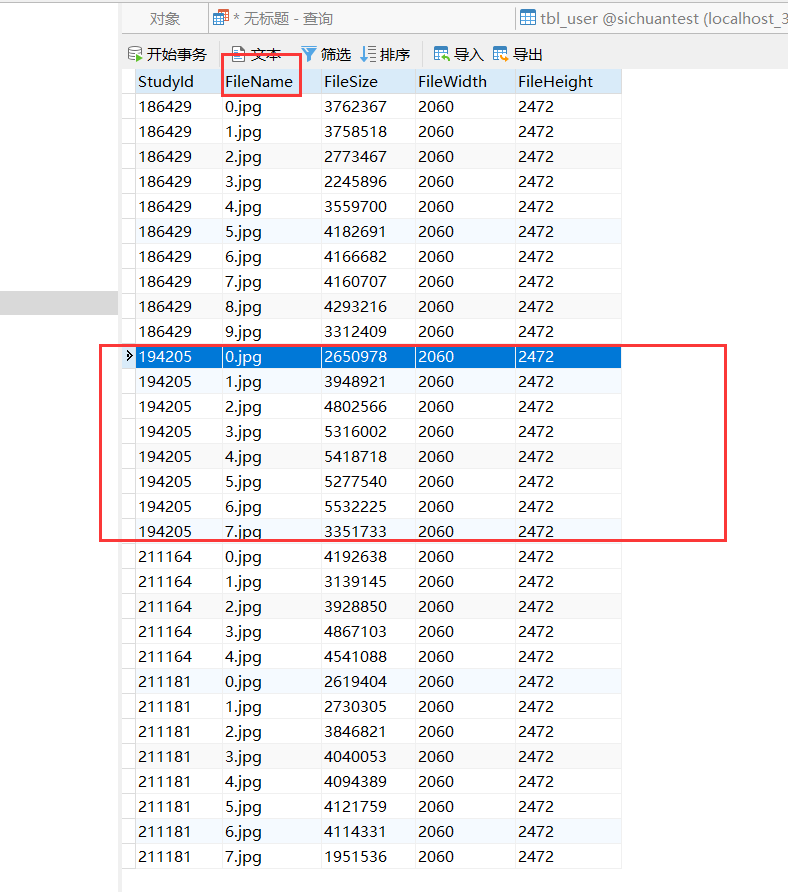
即当根据StudyId='194205'去查的时候,JPA都会返回八条一样的记录
JPA代码:
@Query(value = "select * from tbl_ic_film_info where StudyId = ?1",nativeQuery = true) List<IcFilmInfo> findByStudyIdSQL(String studyId);
service代码:
List<IcFilmInfo> icFilmInfoList= icFilmInfoRepository.findByStudyIdSQL(studyId);
然后循环打印icFilmInfoList

FileName查出来都是1
后来才发现是联合主键惹得锅,数据库表中有两个主键,一个是StudyId,还有一个是FileName。
我的实体类是这么定义的(因为我只需要StudyId和FileName的信息就行了):

当JPA在根据StudyId去查询的时候,只会将StudyId当做主键,当StudyId一样的时候,JPA会当做所有的都是同一条记录,不会管FileName是否相同了,一股脑的返回八条一样的数据。
对此其实有很多种解决办法,说下我使用的几种:
1、使用 List<Map<String, Object>>的方式去接收
由于这边数据库的记录值都字符串类型,我就直接使用List<Map<String, String>>了~
JPA代码:
@Query(value = "select StudyId,FileName from tbl_ic_film_info where StudyId = ?1",nativeQuery = true) List<Map<String,String>> findByStudyIdMap(String studyId);
循环答应查询结果:

这种方式有点就是代码简单,但是如果要对查询的结果再进行一步处理的话,就会变的更复杂,不好处理。
2、自定义接收类
新建一个IcFilmInfoVO类:
@AllArgsConstructor
@Data
public class IcFilmInfoVO {
private String studyId;
/**
* 文件名
*/
private String fileName;
}
注意添加的全参构造方法注解@AllArgsConstructor
JAP代码
@Query(value = "select new cloud.image.vo.IcFilmInfoVO(t.studyId,t.fileName) from IcFilmInfo t where t.studyId = ?1") List<IcFilmInfoVO> findByStudyId(String studyId);
注意,这个时候这里的@Query注解里面是没有加nativeQuery = true的
然后循环打印查询结果:

这样即使以后要操作查询的结果也很方便,同时这种自定义接收类的用法还可以用于统计等业务场景,可以接收sum,count等SQL内置函数查询出来的结果。
3、配置联合主键
由于表中是两个主键的存在,接下来改造一下我们的实体类:
@Entity
@Data
@IdClass(IcFilmInfoPk.class)
@Table(name = "tbl_ic_film_info")
public class IcFilmInfo implements Serializable {
private static final long serialVersionUID = 9121531612760132363L;
@Id
@Column(name = "StudyId")
private String studyId;
/**
* 文件名
*/
@Id
@Column(name = "FileName")
private String fileName;
}
在两个主键映射的字段上都标注@Id注解
同时新建一个IcFilmInfoPk类:
@Data
public class IcFilmInfoPk implements Serializable {
private static final long serialVersionUID = -1570834456846579284L;
private String studyId;
private String fileName;
}
在实体类上加上@IdClass(IcFilmInfoPk.class)注解,这个时候就可以用一下JPA代码直接去查询了
@Query(value = "select * from tbl_ic_film_info where StudyId = ?1",nativeQuery = true) List<IcFilmInfo> findByStudyIdSQL(String studyId);
总结:针对上面三种方法,貌似都可以解决我们的问题,但是个人只推荐第三种,应为第三种是最贴合数据库的,使用了联合主键的注解,数据库中也是多主键,但是第二种方式可以很好的解决我们在使用JPA去查询的时候接口其他非数据库字段的信息,例如统计等方面。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Spring Data JPA的坑点记录总结
前言 Spring-data-jpa的基本介绍:JPA诞生的缘由是为了整合第三方ORM框架,建立一种标准的方式,百度百科说是JDK为了实现ORM的天下归一,目前也是在按照这个方向发展,但是还没能完全实现.在ORM框架中,Hibernate是一支很大的部队,使用很广泛,也很方便,能力也很强,同时Hibernate也是和JPA整合的比较良好,我们可以认为JPA是标准,事实上也是,JPA几乎都是接口,实现都是Hibernate在做,宏观上面看,在JPA的统一之下Hibernate很良好的运行. 最近在
-
Spring Data Jpa 复合主键的实现
前言 这次大创有个需求,在数据库建表时发现,user表与project表的关系表 user_project的主键为复合主键: CREATE TABLE user_project( user_id INT(20), project_id INT(20), timestamp VARCHAR (50), donate_money DOUBLE(10,2), PRIMARY KEY (user_id,project_id) ); 在网上看了几篇博客,以及在spring boot干货群咨询(感谢夜升额耐
-
Spring Data JPA 建立表的联合主键
最近遇到了一个小的问题,就是怎么使用 Spring Data JPA 建立表的联合主键?然后探索出了下面的两种方式. 第一种方式: 第一种方式是直接在类属性上面的两个字段都加上 @Id 注解,就像下面这样,给 stuNo 和 stuName 这两个字段加上联合主键: @Entity @Table(name = "student") public class Student { @Id @Column(name = "stu_no", nullable = false
-

spring jpa设置多个主键遇到的小坑及解决
目录 jpa设置多个主键遇到的坑 解决办法 jpa遇到多主键表如何进行查询 1.使用 List<Map<String, Object>>的方式去接收 2.自定义接收类 3.配置联合主键 jpa设置多个主键遇到的坑 由于项目需要,对多个业务表单独另外建立对应的历史版本记录表,为了原业务表数据能原封不动记录到历史版本表,需要建立组合主键,id+历史版本号作为主键唯一约束(rid+historyVersion). 在实体上需要设置为主键的字段加上注解,@Id,例如: /* * 主键-RI
-
MySQL 处理插入过程中的主键唯一键重复值的解决方法
本篇文章主要介绍在插入数据到表中遇到键重复避免插入重复值的处理方法,主要涉及到IGNORE,ON DUPLICATE KEY UPDATE,REPLACE:接下来就分别看看这三种方式的处理办法. IGNORE 使用ignore当插入的值遇到主键(PRIMARY KEY)或者唯一键(UNIQUE KEY)重复时自动忽略重复的记录行,不影响后面的记录行的插入, 创建测试表 CREATE TABLE Tignore (ID INT NOT NULL PRIMARY KEY , NAME1 INT )d
-
mysql 实现设置多个主键的操作
user表,身份证号码要唯一,手机号码,邮箱要唯一 实现方式: 表结构不用动.一个主键Id 加索引实现 如图类型设置索引类型为Unique 唯一 选择栏位,命个名就行.索引方式btree 就好.ok啦~ 补充:mysql实现多表主键不重复 同一个数据库中有两张表,里面字段都是一样,只是因为存的数据要区分开.但是主键不能重复.具体实现如下: 新建数据库 mytest 新建user表和admin表 CREATE TABLE `user` ( `user_id` INT(11) NOT NULL, `
-
SQL Server主键与外键设置以及相关理解
目录 一.定义与作用 二.SSMS设置表的主键与外键 1.利用SQL语句建立查询设置 2.利用鼠标点击操作创建(SSMS环境下) 三.主键表与外键表(个人的总结与反思...) 补充:SQL Server的主键与外键约束 总结 一.定义与作用 主键:表中能够唯一地辨别事物的属性.通过主键能够查询出表中一条完整的记录,同时使用主键能防止表中出现重复的记录,避免了数据的冗余. 外键:通俗讲就是表中一个属性是来自另一张表的主键,该属性被称为该表的外键,外键可以有不止一个.外键存在的意义就是将事物与事物之
-
Redis中主键失效的原理及实现机制剖析
作为一种定期清理无效数据的重要机制,主键失效存在于大多数缓存系统中,Redis 也不例外.在 Redis 提供的诸多命令中,EXPIRE.EXPIREAT.PEXPIRE.PEXPIREAT 以及 SETEX 和 PSETEX 均可以用来设置一条 Key-Value 对的失效时间,而一条 Key-Value 对一旦被关联了失效时间就会在到期后自动删除(或者说变得无法访问更为准确).可以说,主键失效这个概念还是比较容易理解的,但是在具体实现到 Redis 中又是如何呢?最近本博主就对 Redis
-
python django model联合主键的例子
今天,在家试试django的model的设置,如何设置的联合主键,我经过查资料和实践,把结果记录如下: 例如: class user(Model): id=AutoField(primary_key=True) name = CharField(max_length=30) age =IntegerField() class role(Model): id=AutoField(primary_key=True) name=CharField(max_length=10) 这是两个model有一个
-
Mybatis insert方法主键回填和自定义操作
在数据库插入的时候,有很多属性需要我们自己处理,如主键自增字段. MYSQL中主键根据一定规则生成后,需要我们在插入后去主动获取,以便后面的操作,Mybatis为我们提供了处理的方法. 主键回填 keyProperty:指定哪个字段是主键 useGeneratedKeys:这个主键是否使用数据库内置生成策略 我们可以在XML文件中进行如下配置: <insert id="insertUser" parameterType="user" useGeneratedK
-
Mybaits处理mysql主键自动增长出现的不连续问题解决
问题产生 设置了mysql主键自动增长,但因为删除字段的操作导致主键不连续 解决方法 step1:在mapper.xml文件中添加update标签设置自动增长的增量为1 alter table student AUTO_INCREMENT=1; <!--StudentMapper.xml文件--> <mapper namespace="StudentMapper"> ... ... <update id="alter"> alte
-
MyBatis处理mysql主键自动增长出现的不连续问题解决
问题产生 设置了mysql主键自动增长,但因为删除字段的操作导致主键不连续 解决方法 step1:在mapper.xml文件中添加update标签设置自动增长的增量为1 alter table student AUTO_INCREMENT=1; <!--StudentMapper.xml文件--> <mapper namespace="StudentMapper"> ... ... <update id="alter"> alte
-
mybatis中返回主键一直为1的问题
目录 mybatis 返回主键一直为1 mybatis 自增主键 主键回传,返回id为null 踩坑 Mybatis主键回传流程 踩坑 总结 mybatis 返回主键一直为1 1是返回的插入成功的行数,这没有错 而自增id则是直接映射到对象里,直接输出 xxx.getId()即可 举例: 在xml中: <insert id="addUser" parameterType="blog.model.User" useGeneratedKeys="true