Pytorch卷积神经网络迁移学习的目标及好处
目录
- 前言
- 一、经典的卷积神经网络
- 二、迁移学习的目标
- 三、好处
- 四、步骤
- 五、代码
前言
在深度学习训练的过程中,随着网络层数的提升,我们训练的次数,参数都会提高,训练时间相应就会增加,我们今天来了解迁移学习
一、经典的卷积神经网络
在pytorch官网中,我们可以看到许多经典的卷积神经网络。
附官网链接:https://pytorch.org/

这里简单介绍一下经典的卷积神经发展历程
1.首先可以说是卷积神经网络的开山之作Alexnet(12年的夺冠之作)这里简单说一下缺点 卷积核大,步长大,没有填充层,大刀阔斧的提取特征,容易忽略一些重要的特征
2.第二个就是VGG网络,它的卷积核大小是3*3,有一个优点是经过池化层之后,通道数翻倍,可以更多的保留一些特征,这是VGG的一个特点

在接下来的一段时间中,出现了一个问题,我们都知道,深度学习随着训练次数的不断增加,效果应该是越来越好,但是这里出现了一个问题,研究发现随着VGG网络的不断提高,效果却没有原来的好,这时候人们就认为,深度学习是不是只能发展到这里了,这时遇到了一个瓶颈。
3.接下来随着残差网络(Resnet)的提出,解决了上面这个问题,这个网络的优点是保留了原有的特征,假如经过卷积之后提取的特征还没有原图的好,这时候保留原有的特征,就会解决这一问题,下面就是resnet网络模型


这是一些训练对比:
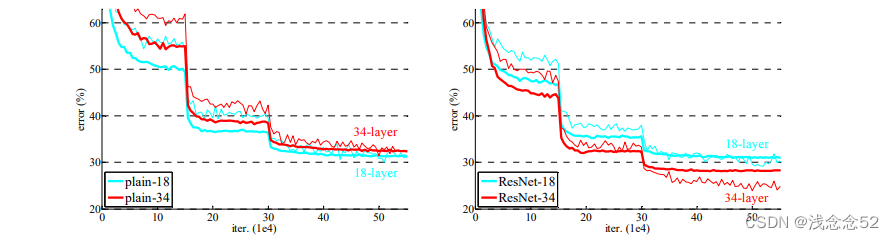
二、迁移学习的目标
首先我们使用迁移学习的目标就是用人家训练好的权重参数,偏置参数,来训练我们的模型。
三、好处
深度学习要训练的数据量是很大的,当我们数据量少时,我们训练的权重参数就不会那么的好,所以这时候我们就可以使用别人训练好的权重参数,偏置参数来使用,会使我们的模型准确率得到提高
四、步骤
迁移学习大致可以分为三步
1.加载模型
2.冻结层数
3.全连接层
五、代码
这里使用的是resnet152
import torch
import torchvision as tv
import torch.nn as nn
import torchvision
import torch.nn.functional as F
import torchvision.transforms as transforms
import torch
from torch.utils import data
from torch import optim
from torch.autograd import Variable
model_name='resnet'
featuer_extract=True
train_on_gpu=torch.cuda.is_available()
if not train_on_gpu:
print("没有gpu")
else :
print("是gpu")
devic=torch.device("cuda:0" if torch.cuda.is_available() else 'cpu')
teature_extract=True
def set_paremeter_requires_grad(model,featuer_extract):
if featuer_extract:
for parm in model.parameters():
parm.requires_grad=False #不做训练
def initialize_model(model_name,num_classes,featuer_extract,use_pretrained=True):
model_ft = None
input_size = 0
if model_name=="resnet":
model_ft=tv.models.resnet152(pretrained=use_pretrained)#下载模型
set_paremeter_requires_grad(model_ft,featuer_extract) #冻结层数
num_ftrs=model_ft.fc.in_features #改动全连接层
model_ft.fc=nn.Sequential(nn.Linear(num_ftrs,num_classes),
nn.LogSoftmax(dim=1))
input_size=224 #输入维度
return model_ft,input_size
model_ft,iput_size=initialize_model(model_name,10,featuer_extract,use_pretrained=True)
model_ft=model_ft.to(devic)
params_to_updata=model_ft.parameters()
if featuer_extract:
params_to_updata=[]
for name,param in model_ft.named_parameters():
if param.requires_grad==True:
params_to_updata.append(param)
print("\t",name)
else:
for name,param in model_ft.parameters():
if param.requires_grad==True:
print("\t",name)
opt=optim.Adam(params_to_updata,lr=0.01)
loss=nn.NLLLoss()
if __name__ == '__main__':
transform = transforms.Compose([
# 图像增强
transforms.Resize(1024),#裁剪
transforms.RandomHorizontalFlip(),#随机水平翻转
transforms.RandomCrop(224),#随机裁剪
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5), #亮度
# 转变为tensor 正则化
transforms.ToTensor(), #转换格式
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) # 归一化处理
])
trainset = tv.datasets.CIFAR10(
root=r'E:\桌面\资料\cv3\数据集\cifar-10-batches-py',
train=True,
download=True,
transform=transform
)
trainloader = data.DataLoader(
trainset,
batch_size=8,
drop_last=True,
shuffle=True, # 乱序
num_workers=4,
)
testset = tv.datasets.CIFAR10(
root=r'E:\桌面\资料\cv3\数据集\cifar-10-batches-py',
train=False,
download=True,
transform=transform
)
testloader = data.DataLoader(
testset,
batch_size=8,
drop_last=True,
shuffle=False,
num_workers=4
)
for epoch in range(3):
running_loss=0
for index,data in enumerate(trainloader,0):
inputs, labels = data
inputs = inputs.to(devic)
labels = labels.to(devic)
inputs, labels = Variable(inputs), Variable(labels)
opt.zero_grad()
h=model_ft(inputs)
loss1=loss(h,labels)
loss1.backward()
opt.step()
h+=loss1.item()
if index%10==9:
avg_loss=loss1/10.
running_loss=0
print('avg_loss',avg_loss)
if index%100==99 :
correct=0
total=0
for data in testloader:
images,labels=data
outputs=model_ft(Variable(images.cuda()))
_,predicted=torch.max(outputs.cpu(),1)
total+=labels.size(0)
bool_tensor=(predicted==labels)
correct+=bool_tensor.sum()
print('1000张测试集中的准确率为%d %%'%(100*correct/total))
以上就是Pytorch卷积神经网络迁移学习的目标及好处的详细内容,更多关于Pytorch卷积神经网络迁移的资料请关注我们其它相关文章!
相关推荐
-

Python深度学习pytorch卷积神经网络LeNet
目录 LeNet 模型训练 在本节中,我们将介绍LeNet,它是最早发布的卷积神经网络之一.这个模型是由AT&T贝尔实验室的研究院Yann LeCun在1989年提出的(并以其命名),目的是识别手写数字.当时,LeNet取得了与支持向量机性能相媲美的成果,成为监督学习的主流方法.LeNet被广泛用于自动取款机中,帮助识别处理支票的数字. LeNet 总体来看,LeNet(LeNet-5)由两个部分组成: 卷积编码器: 由两个卷积层组成 全连接层密集快: 由三个全连接层组成 每个卷积块中的基本单元
-
使用pytorch提取卷积神经网络的特征图可视化
目录 前言 1. 效果图 2. 完整代码 3. 代码说明 4. 可视化梯度,feature 总结 前言 文章中的代码是参考基于Pytorch的特征图提取编写的代码本身很简单这里只做简单的描述. 1. 效果图 先看效果图(第一张是原图,后面的都是相应的特征图,这里使用的网络是resnet50,需要注意的是下面图片显示的特征图是经过放大后的图,原图是比较小的图,因为太小不利于我们观察): 2. 完整代码 import os import torch import torchvision as tv
-
Python编程pytorch深度卷积神经网络AlexNet详解
目录 容量控制和预处理 读取数据集 2012年,AlexNet横空出世.它首次证明了学习到的特征可以超越手工设计的特征.它一举打破了计算机视觉研究的现状.AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年的ImageNet图像识别挑战赛. 下图展示了从LeNet(左)到AlexNet(right)的架构. AlexNet和LeNet的设计理念非常相似,但也有如下区别: AlexNet比相对较小的LeNet5要深得多. AlexNet使用ReLU而不是sigmoid作为其激活函数
-
pytorch实现CNN卷积神经网络
本文为大家讲解了pytorch实现CNN卷积神经网络,供大家参考,具体内容如下 我对卷积神经网络的一些认识 卷积神经网络是时下最为流行的一种深度学习网络,由于其具有局部感受野等特性,让其与人眼识别图像具有相似性,因此被广泛应用于图像识别中,本人是研究机械故障诊断方面的,一般利用旋转机械的振动信号作为数据. 对一维信号,通常采取的方法有两种,第一,直接对其做一维卷积,第二,反映到时频图像上,这就变成了图像识别,此前一直都在利用keras搭建网络,最近学了pytroch搭建cnn的方法,进行一下代码
-
PyTorch上实现卷积神经网络CNN的方法
一.卷积神经网络 卷积神经网络(ConvolutionalNeuralNetwork,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此CNN在
-
Pytorch卷积神经网络迁移学习的目标及好处
目录 前言 一.经典的卷积神经网络 二.迁移学习的目标 三.好处 四.步骤 五.代码 前言 在深度学习训练的过程中,随着网络层数的提升,我们训练的次数,参数都会提高,训练时间相应就会增加,我们今天来了解迁移学习 一.经典的卷积神经网络 在pytorch官网中,我们可以看到许多经典的卷积神经网络. 附官网链接:https://pytorch.org/ 这里简单介绍一下经典的卷积神经发展历程 1.首先可以说是卷积神经网络的开山之作Alexnet(12年的夺冠之作)这里简单说一下缺点 卷积核大,步长大
-
Pytorch卷积神经网络resent网络实践
目录 前言 一.技术介绍 二.实现途径 三.总结 前言 上篇文章,讲了经典卷积神经网络-resnet,这篇文章通过resnet网络,做一些具体的事情. 一.技术介绍 总的来说,第一步首先要加载数据集,对数据进行一些处理,第二步,调整学习率一些参数,训练好resnet网络模型,第三步输入图片或者视频通过训练好的模型,得到结果. 二.实现途径 1.加载数据集,对数据进行处理,加载的图片是(N,C,H,W )对图片进行处理成(C,H,W),通过图片名称获取标签,进行分类. train_paper=r'
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
tensorflow学习笔记之mnist的卷积神经网络实例
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=Tru
-
Pytorch模型迁移和迁移学习,导入部分模型参数的操作
1. 利用resnet18做迁移学习 import torch from torchvision import models if __name__ == "__main__": # device = torch.device("cuda" if torch.cuda.is_available() else "cpu") device = 'cpu' print("-----device:{}".format(device))