scrapy爬虫遇到js动态渲染问题
目录
- 一、传统爬虫的问题
- 1.实际案例
- 二、scrapy解决动态网页渲染问题的策略
- 三、安装使用scrapy-splash
- 1.安装Docker
- 2.安装splash镜像
- 3.安装scrapy-splash
- 四、项目实践
- 五、总结与思考
一、传统爬虫的问题
scrapy爬虫与传统爬虫一样,都是通过访问服务器端的网页,获取网页内容,最终都是通过对于网页内容的分析来获取数据,这样的弊端就在于他更适用于静态网页的爬取,而面对js渲染的动态网页就有点力不从心了,因为通过js渲染出来的动态网页的内容与网页文件内容是不一样的。
1.实际案例
腾讯招聘:https://careers.tencent.com/search.html

这个网站第一眼看过去是非常中规中矩的,结构也很鲜明,感觉是很好爬的样子,但是当你查看他的网页文件的时候,就会发现:

网页文件并没有太多的内容,全部是引用了js做的动态渲染,所有数据都在js中间,这就使我们无法对于网页的结构进行分析来进行爬取数据
那我们如何,获取到它实际显示的页面,然后对页面内容进行分析呢?
二、scrapy解决动态网页渲染问题的策略
目前scrapy解决动态网页渲染问题的主要有以下三种的解决方法:
seleium+chrome
就是传统的结合浏览器进行渲染,优点就在于,浏览器能访问什么,他就能够获取到什么,缺点也很明显,因为它需要配合浏览器,所以它的速度很慢。
selenium+phantomjs
与上一种的方式一样,但是不需要开浏览器。
scrapy-splash(推荐)
而scrapy-splash与以上两种方法对比,它更加快速轻量,由于,他是基于twisted和qt开发的轻量浏览器引擎,并提供了http api,速度更快,最重要的是他能够与scrapy非常完美的融合。
三、安装使用scrapy-splash
1.安装Docker
由于ScrapySplash要在docker里使用,我们先安装docker,过程比较复杂痛苦,略。
在安装的过程中有一个非常严峻的问题,那就是docker,需要开启win10 hyper虚拟服务,这与你在电脑上安装的VM是相冲突的,所以在使用docker,的时候无法使用VM虚拟机,而且每次切换时都需要重启电脑,目前这个问题暂时无法解决。
2.安装splash镜像
docker run -p 8050:8050 scrapinghub/splash
这个过程异常异常的慢,而且必须是国内的镜像,才能够下载下来。
所以我配置了两个国内的下载IP,一个网易的,一个阿里云的。
{
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
],
"insecure-registries": [],
"debug": true,
"experimental": false
}
下载完成过后,打开浏览器访问:http://localhost:8050/
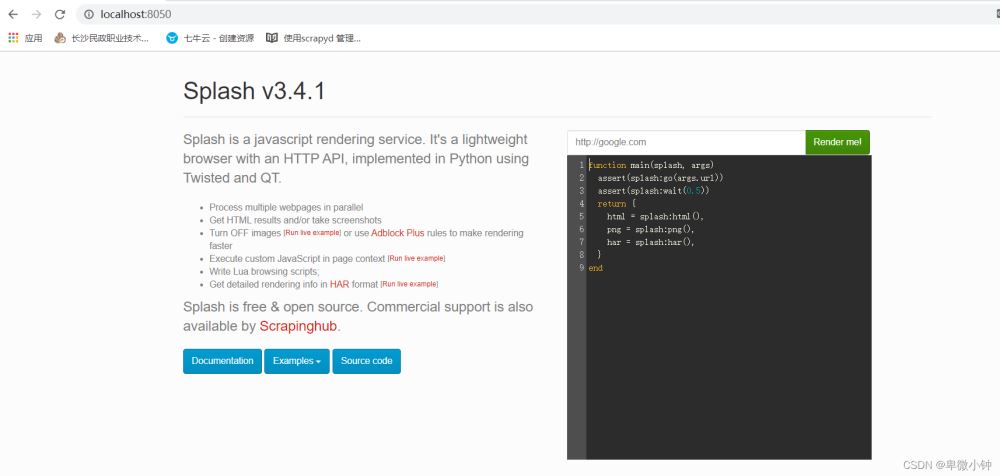
这就表示已经安装完成了,命令行不能关闭哦
3.安装scrapy-splash
pip install scrapy-splash
python没有花里胡哨的安装过程。
四、项目实践
1.项目的创建和配置过程略
2.settings.py的配置
PIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # 不配置查不到信息
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://localhost:8050/" # 自己安装的docker里的splash位置
# DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter"
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
3.爬虫的设计
def start_requests(self):
splah_args = {
"lua_source": """
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(0.5))
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end
"""
}
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.109 Safari/537.36',
}
yield SplashRequest(url=self.start_url, callback=self.parse, args=splah_args,
headers=headers)
这里我们编写一个初始化的start_requests方法,这个方法是继承父类的。
注意我们最后的请求方式SplashRequest,我们不再使用Request,而是使用scrapy-splash的请求方式,这里也体现了它与scope框架的完美融合。
至于里面的参数,就没有必要介绍了,其中要注意两个参数args和callback。
- args是配置信息可以参照http://localhost:8050/中的
- callback下一级处理方法的函数名,最后的方法一定要指向self.parse,这是scrapy迭代爬取的灵魂。
4.解析打印数据
def parse(self, response):
print(response.text)
job_boxs = response.xpath('.//div[@class="recruit-list"]')
for job_box in job_boxs:
title = job_box.xpath('.//a/h4/text()').get()
print(title)
这是通过渲染以后的网页数据

这里我们直接获取职位的标题
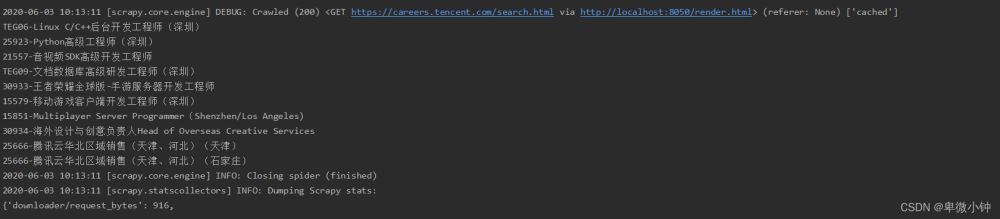
这就表明scrapy爬虫应对动态网页渲染问题已经解决,也就意味着scrapy能够处理大部分的网页,并可以应对一些图形验证问题
五、总结与思考
之后遇到的问题,当我们获取到了,职位列表过后,当我们需要访问详情页的时候,我们就必须获取详情页的链接,但是腾讯非常的聪明,并没有采用超链接的方式进行跳转,而是通过用户点击事件,然后通过js跳转,这就造成了我们无法获取详情页的链接。
当我沮丧的时候,我认真的检查了浏览器与服务器的数据交换中,其实它的数据也是通过js进行后台请求得到的,所以通过对大量的数据进行采集,最终找到了他的数据接口(贼开心!!!)

这时候我们就要做取舍了,我们想要的是所有数据,并不是渲染出来的网页,与解析网页内容相比,直接通过它的接口获取json数据,更加快捷方便,速度更快,所以我们就要做出取舍,在这里直接获取接口数据将更好,错误率会更低,速度也会更快。
其实大部分的动态网页的渲染,都存在与数据端进行请求交互数据,当然也存在一些,直接把数据存在js中间,然后再通过js渲染到网页上,这时候scrapy-splash就可以发挥价值了,尤其是在一些验证码,图形验证方面更加突出。随着前端技术的不断发展,前端对数据的控制更加灵活多样,这也要求爬虫的逻辑也需要不断的跟进,也要求使用新的工具,新的技术,在不断的探索实践中跟上时代的步伐。
到此这篇关于scrapy爬虫遇到js动态渲染问题的文章就介绍到这了,更多相关scrapy爬虫js动态渲染内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

爬虫进阶-JS自动渲染之Scrapy_splash组件的使用
目录 1. 什么是scrapy_splash? 2. scrapy_splash的作用 3. scrapy_splash的环境安装 3.1 使用splash的docker镜像 3.2 在python虚拟环境中安装scrapy-splash包 4. 在scrapy中使用splash 4.1 创建项目创建爬虫 4.2 完善settings.py配置文件 4.3 不使用splash 4.4 使用splash 4.5 分别运行俩个爬虫,并观察现象 4.6 结论 5. 了解更多 6. 小结 1. 什么是s
-
scrapy爬虫遇到js动态渲染问题
目录 一.传统爬虫的问题 1.实际案例 二.scrapy解决动态网页渲染问题的策略 三.安装使用scrapy-splash 1.安装Docker 2.安装splash镜像 3.安装scrapy-splash 四.项目实践 五.总结与思考 一.传统爬虫的问题 scrapy爬虫与传统爬虫一样,都是通过访问服务器端的网页,获取网页内容,最终都是通过对于网页内容的分析来获取数据,这样的弊端就在于他更适用于静态网页的爬取,而面对js渲染的动态网页就有点力不从心了,因为通过js渲染出来的动态网页的内容与网页
-
php使用QueryList轻松采集js动态渲染页面方法
QueryList使用jQuery的方式来做采集,拥有丰富的插件.下面来演示QueryList使用PhantomJS插件抓取JS动态创建的页面内容. 一.安装 使用Composer安装: 1.安装QueryList composer require jaeger/querylist GitHub: https://github.com/jae-jae/QueryList 2.安装PhantomJS插件 composer require jaeger/querylist-phantomjs Git
-
JS实现数据动态渲染的竖向步骤条
本文实例为大家分享了JS实现数据动态渲染竖向步骤条的具体代码,供大家参考,具体内容如下 实现以下效果: 运用的知识点主要是html的伪元素.然后步骤条通过js动态渲染.最后一条数据的状态颜色状态为高亮状态. 直接上代码 html部分: <ul class="progress_box"> </ul> css部分: * { margin: 0; padding: 0; } ul { width: 360px; margin:100px auto; } li { po
-
快速解决js动态改变dom元素属性后页面及时渲染的问题
今天实现一个进度条加载过程,dom结构其实就是两个div <div class="pbar"> <div class="ui-widget-header" id="percent_bar" style="width: 23%;"></div> </div> 控制里层div的宽width属性,就能实现进度条往前走的效果. 我的进度条是显示下载文件的进度,简单实现一共100个文件的话
-
基于JS正则表达式实现模板数据动态渲染(实现思路详解)
最近业务上需要动态渲染模板数据,好久没写前端代码了,有点生疏,将思路简单写下来,防老: 一.业务需求: 1.前端后端定义好模板以及变量名,保存数据库 2.订单数据是前端根据支付结果获取的,最终渲染完的数据模板需要调用打印机打印出来 3.模板相对商家来说比较固定,但是每个商家需要的模板都有可能不一样,所以需要每次登录后,查询一次模板缓存前端,后续每次支付后,动态渲染数据即可 二.考点: 1.正则表达式 2.精简代码量,尽量减少前端的工作量 三.实现思路: 1.需要渲染数据的模板,以${变量名}区
-
mustache.js实现首页元件动态渲染的示例代码
前言 在项目开发过程中,特别是OA类软件,会针对邮件/待办/公告等模块在主页面进行快捷查看的元件展示要求,类似效果如下 针对框架层面,我们可以进行后台的可视化配置,使用mustache.js在主页面进行动态渲染,避免了对主页面的繁琐的硬编码工作,同时针对每个信息展示的元件进行内部个性化处理 表结构 包含了元件名称,元件模板路径,元件列表数据路由,查看更多路由,启用/禁用等 可视化配置 模板定义 这里的模板直接使用的html文件,方便css与js的修改,简单的使用了mustache
-
scrapy结合selenium解析动态页面的实现
1. 问题 虽然scrapy能够完美且快速的抓取静态页面,但是在现实中,目前绝大多数网站的页面都是动态页面,动态页面中的部分内容是浏览器运行页面中的JavaScript脚本动态生成的,爬取相对困难: 比如你信心满满的写好了一个爬虫,写好了目标内容的选择器,一跑起来发现根本找不到这个元素,当时肯定一万个黑人问号 于是你在浏览器里打开F12,一顿操作,发现原来这你妹的是ajax加载的,不然就是硬编码在js代码里的,blabla的- 然后你得去调ajax的接口,然后解析json啊,转成python字
-
Scrapy框架介绍之Puppeteer渲染的使用
1.Scrapy框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便. Scrapy 使用了 Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求. Scrapy Engine(引擎): 负责Spider.ItemPipeline.Do
-
浅析JS动态创建元素【两种方法】
前言: 创建元素有两种方法 1)将需要创建的元素,以字符串的形式拼接:找到父级元素,直接对父级元素的innnerHTML进行赋值. 2)使用Document.Element对象自带的一些函数,来实现动态创建元素(创建元素 => 找到父级元素 => 在指定位置插入元素) 一.字符串拼接形式 为了更好的理解,设定一个应用场景. 随机生成一组数字,将这组数据渲染为条形图的形式,放在div[id="container"]中,如下图 <div id="containe