python笔记之使用fillna()填充缺失值
目录
- 使用fillna()填充缺失值
- 关于fillna()函数详解
- 一、不指定任何参数
- 二、指定inplace参数
- 三、指定method参数
- 四、指定limit参数
- 五、指定axis参数
使用fillna()填充缺失值
df = pd.read_csv('ccf_offline_stage1_train.csv')
print(df['Distance'])
df['distance'] = df['Distance'].fillna(-1).astype(int)
print(df['distance'])
结果太长不展示了,经过操作后成功将dataframe中distance列的缺失值都变成了-1
关于fillna()函数详解
inplace参数的取值:True、False
True:直接修改原对象False:创建一个副本,修改副本,原对象不变(缺省默认)
method参数的取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
pad/ffill:用前一个非缺失值去填充该缺失值backfill/bfill:用下一个非缺失值填充该缺失值None:指定一个值去替换缺失值(缺省默认这种方式)
limit参数:限制填充个数
axis参数:修改填充方向
#导包 import pandas as pd import numpy as np from numpy import nan as NaN
df1=pd.DataFrame([[1,2,3],[NaN,NaN,2],[NaN,NaN,NaN],[8,8,NaN]]) df1
代码结果:
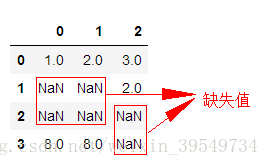
一、不指定任何参数
1. 用常数填充
#一、不指定method参数
#1.用常数填充
print (df1.fillna(100))
print ("-----------------------")
print (df1)
运行结果:

2. 用字典填充
#2.用字典填充
df1.fillna({0:10,1:20,2:30})
运行结果:

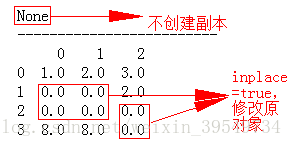
二、指定inplace参数
#二、指定inplace参数
print (df1.fillna(0,inplace=True))
print ("-------------------------")
print (df1)
运行结果:
三、指定method参数
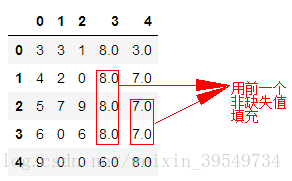
1.method = 'ffill'/'pad':用前一个非缺失值去填充该缺失值
#三、指定method参数 df2 = pd.DataFrame(np.random.randint(0,10,(5,5))) df2.iloc[1:4,3] = NaN df2.iloc[2:4,4] = NaN df2
运行结果:

#1.method = 'ffill'/'pad':用前一个非缺失值去填充该缺失值 df2.fillna(method='ffill')
运行结果:
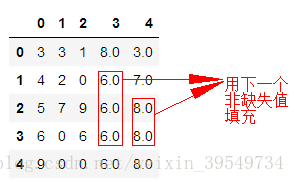
2.method = 'bflii'/'backfill':用下一个非缺失值填充该缺失值
#2.method = 'bflii'/'backfill':用下一个非缺失值填充该缺失值 df2.fillna(method='bfill')
运行结果:
四、指定limit参数
#四、指定limit参数 #用下一个非缺失值填充该缺失值 #只填充2个 df2.fillna(method='bfill', limit=2)
运行结果:
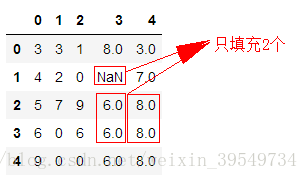
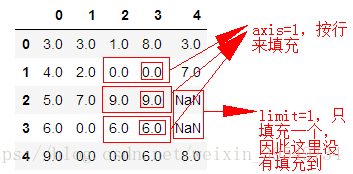
五、指定axis参数
#五、指定axis参数 df2.fillna(method="ffill", limit=1, axis=1)
运行结果:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python缺失值处理方法
前言: 前面python重复值处理得方法我们讲了重复值是怎么处理的,今天就来说说缺失值.缺失值主要分为机械原因和人为原因.机械原因就是存储器坏了,机器故障等等原因导致某段时间未能收集到数据.人为原因的情况种类就更多了,如刻意隐瞒等等. 先构建一个含有缺失值的DataFrame,如下: import pandas as pd import numpy as np data = pd.DataFrame([[1,np.nan,3],[np.nan,5,np.nan]],columns = ['a',
-
Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
Pandas之Fillna填充缺失数据的方法
约定: import pandas as pd import numpy as np from numpy import nan as NaN 填充缺失数据 fillna()是最主要的处理方式了. df1=pd.DataFrame([[1,2,3],[NaN,NaN,2],[NaN,NaN,NaN],[8,8,NaN]]) df1 代码结果: 0 1 2 0 1.0 2.0 3.0 1 NaN NaN 2.0 2 NaN NaN NaN 3 8.0 8.0 NaN 用常数填充: df1.fill
-
Python数据分析之缺失值检测与处理详解
目录 检测缺失值 缺失值处理 删除缺失值 填补缺失值 检测缺失值 我们先创建一个带有缺失值的数据框(DataFrame). import pandas as pd df = pd.DataFrame( {'A': [None, 2, None, 4], 'B': [10, None, None, 40], 'C': [100, 200, None, 400], 'D': [None, 2000, 3000, None]}) df 数值类缺失值在 Pandas 中被显示为 NaN (Not A N
-
python笔记之使用fillna()填充缺失值
目录 使用fillna()填充缺失值 关于fillna()函数详解 一.不指定任何参数 二.指定inplace参数 三.指定method参数 四.指定limit参数 五.指定axis参数 使用fillna()填充缺失值 df = pd.read_csv('ccf_offline_stage1_train.csv') print(df['Distance']) df['distance'] = df['Distance'].fillna(-1).astype(int) print(df['dist
-
python实现数据预处理之填充缺失值的示例
1.给定一个数据集noise-data-1.txt,该数据集中保护大量的缺失值(空格.不完整值等).利用"全局常量"."均值或者中位数"来填充缺失值. noise-data-1.txt: 5.1 3.5 1.4 0.2 4.9 3 1.4 0.2 4.7 3.2 1.3 0.2 4.6 3.1 1.5 0.2 5 3.6 1.4 0.2 5.4 3.9 1.7 0.4 4.6 3.4 1.4 0.3 5 3.4 1.5 0.2 4.4 2.9 1.4 0.2 4.9
-
python 如何通过KNN来填充缺失值
看代码吧~ # 加载库 import numpy as np from fancyimpute import KNN from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_blobs # 创建模拟特征矩阵 features, _ = make_blobs(n_samples = 1000, n_features = 2, random_state = 1) # 标准化特征 scaler
-
python dataframe向下向上填充,fillna和ffill的方法
首先新建一个dataframe: In[8]: df = pd.DataFrame({'name':list('ABCDA'),'house':[1,1,2,3,3],'date':['2010-01-01','2010-06-09','2011-12-03','2011-04-05','2012-03-23']}) In[9]: df Out[9]: date house name 0 2010-01-01 1 A 1 2010-06-09 1 B 2 2011-12-03 2 C 3 201
-
pandas 使用均值填充缺失值列的小技巧分享
pd.DataFrame中通常含有许多特征,有时候需要对每个含有缺失值的列,都用均值进行填充,代码实现可以这样: for column in list(df.columns[df.isnull().sum() > 0]): mean_val = df[column].mean() df[column].fillna(mean_val, inplace=True) # -------代码分解------- # 判断哪些列有缺失值,得到series对象 df.isnull().sum() > 0
-
pandas检查和填充缺失值的N种方法总结
目录 一.构建示例数据 二.检查缺失值的n种方法 2.1 确认是否有缺失值的两种方法 2.2 查看缺失数目和缺失率 2.3 查看非缺失值数目 三.缺失值填充三种示例 一.构建示例数据 import pandas as pd import numpy as np data = {"ID":[202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010], "Chinese"
-
python笔记:mysql、redis操作方法
模块安装: 数据操作用到的模块pymysql,需要通过pip install pymysql进行安装. redis操作用的模块是redis,需要通过pip install redis进行安装. 检验是否安装成功:进入到Python命令行模式,输入import pymysql. import redis ,无报错代表成功: mysql操作方法如下: 查询数据:fetchone.fetchmany(n).fetchall() import pymysql #建立mysql连接,ip.端口.用户名.密
-
python笔记(1) 关于我们应不应该继续学习python
以前面试的时候会被问到,linux熟不熟呀?对于这种问题:我总会尴尬地回答,"额..了解一点". 然而,我大学毕业的时候,连linux的虚拟机都没装过,更别提系统熟不熟悉了.虽然我了解一点这个系统可以完全通过命令来操作.后来工作了,有时候写点代码,svn提交上去,服务器是Linux的,自己也是在windows上跑跑客户端.记得有个项目,要求用shell来启动java程序,你知道那时候我是怎么做的吗?把他们的shell拿来,问哪几个地方要改的,然后改下要启动java类的路径.ok了,完全
-
Python实现螺旋矩阵的填充算法示例
本文实例讲述了Python实现螺旋矩阵的填充算法.分享给大家供大家参考,具体如下: afanty的分析: 关于矩阵(二维数组)填充问题自己动手推推,分析下两个下表的移动规律就很容易咯. 对于螺旋矩阵,不管它是什么鬼,反正就是依次向右.向下.向右.向上移动. 向右移动:横坐标不变,纵坐标加1 向下移动:纵坐标不变,横坐标加1 向右移动:横坐标不变,纵坐标减1 向上移动:纵坐标不变,横坐标减1 代码实现: #coding=utf-8 import numpy ''''' Author: afanty