mysql ON DUPLICATE KEY UPDATE重复插入时更新方式
目录
- mysql当插入重复时更新的方法
- 第一种方法
- 第二种方法
- 第三种方法
- Mysql on duplicate key update
- 解决插入重复数据时更新值的问题以及其存在的问题
- 一、使用
- 二、存在问题
mysql当插入重复时更新的方法
第一种方法
示例一:插入多条记录
假设有一个主键为 client_id 的 clients 表,可以使用下面的语句:
INSERT INTO clients (client_id,client_name,client_type) SELECT supplier_id,supplier_name,'advertising' FROM suppliers WHERE not exists(select * from clients where clients.client_id=suppliers.supplier_id);
示例一:插入单条记录
INSERT INTO clients (client_id,client_name,client_type) SELECT 10345,'IBM','advertising' FROM dual WHERE not exists (select * from clients where clients.client_id=10345);
使用 dual 做表名可以让你在 select 语句后面直接跟上要插入字段的值,即使这些值还不存在当前表中。
第二种方法
INSERT 中ON DUPLICATE KEY UPDATE的使用(本文重点)
如果您指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE。例如,如果列a被定义为UNIQUE,并且包含值1,则以下两个语句具有相同的效果:
mysql>INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; mysql>UPDATE table SET c=c+1 WHERE a=1;
如果行作为新记录被插入,则受影响行的值为1;如果原有的记录被更新,则受影响行的值为2。
注释:如果列b也是唯一列,则INSERT与此UPDATE语句相当:
mysql>UPDATE table SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
如果a=1 OR b=2与多个行向匹配,则只有一个行被更新。通常,您应该尽量避免对带有多个唯一关键字的表使用ON DUPLICATE KEY子句。
您可以在UPDATE子句中使用VALUES(col_name)函数从INSERT...UPDATE语句的INSERT部分引用列值。
换句话说,如果没有发生重复关键字冲突,则UPDATE子句中的VALUES(col_name)可以引用被插入的col_name的值。
本函数特别适用于多行插入。VALUES()函数只在INSERT...UPDATE语句中有意义,其它时候会返回NULL。
示例:
mysql>INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6) ->ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);
本语句与以下两个语句作用相同:
mysql>INSERT INTO table (a,b,c) VALUES (1,2,3) ->ON DUPLICATE KEY UPDATE c=3; mysql>INSERT INTO table (a,b,c) VALUES (4,5,6) ->ON DUPLICATE KEY UPDATE c=9;
当您使用ON DUPLICATE KEY UPDATE时,DELAYED选项被忽略。
第三种方法
REPLACE语句
我们在使用数据库时可能会经常遇到这种情况。如果一个表在一个字段上建立了唯一索引,当我们再向这个表中使用已经存在的键值插入一条记录,那将会抛出一个主键冲突的错误。
当然,我们可能想用新记录的值来覆盖原来的记录值。如果使用传统的做法,必须先使用DELETE语句删除原先的记录,然后再使用INSERT插入新的记录。
而在MySQL中为我们提供了一种新的解决方案,这就是REPLACE语句。
使用REPLACE插入一条记录时,如果不重复,REPLACE就和INSERT的功能一样,如果有重复记录,REPLACE就使用新记录的值来替换原来的记录值。
使用REPLACE的最大好处就是可以将DELETE和INSERT合二为一,形成一个原子操作。这样就可以不必考虑在同时使用DELETE和INSERT时添加事务等复杂操作了。
在使用REPLACE时,表中必须有唯一索引,而且这个索引所在的字段不能允许空值,否则REPLACE就和INSERT完全一样的。
在执行REPLACE后,系统返回了所影响的行数,如果返回1,说明在表中并没有重复的记录,如果返回2,说明有一条重复记录,系统自动先调用了DELETE删除这条记录,然后再记录用INSERT来插入这条记录。如果返回的值大于2,那说明有多个唯一索引,有多条记录被删除和插入。
REPLACE的语法和INSERT非常的相似,如下面的REPLACE语句是插入或更新一条记录。
REPLACE INTO users (id,name,age) VALUES(123, '赵本山', 50);
插入多条记录:
REPLACE INTO users(id, name, age) VALUES(123, '赵本山', 50), (134,'Mary',15);
REPLACE也可以使用SET语句
REPLACE INTO users SET id = 123, name = '赵本山', age = 50;
上面曾提到REPLACE可能影响3条以上的记录,这是因为在表中有超过一个的唯一索引。在这种情况下,REPLACE将考虑每一个唯一索引,并对每一个索引对应的重复记录都删除,然后插入这条新记录。假设有一个table1表,有3个字段a, b, c。它们都有一个唯一索引。
CREATE TABLE table1(a INT NOT NULL UNIQUE,b INT NOT NULL UNIQUE,c INT NOT NULL UNIQUE);
假设table1中已经有了3条记录
a b c
1 1 1
2 2 2
3 3 3
下面我们使用REPLACE语句向table1中插入一条记录。
REPLACE INTO table1(a, b, c) VALUES(1,2,3);
返回的结果如下
Query OK, 4 rows affected (0.00 sec)
在table1中的记录如下
a b c
1 2 3
Mysql on duplicate key update
解决插入重复数据时更新值的问题以及其存在的问题
当有需求,在插入新记录时,如果不存在就插入一条新记录,而存在时就更新原记录上的某些数据,这是可以使用on duplicate key update 语法。
一、使用
demo如下:
首先创建表test
drop table if exists test;
create table test(
id int primary key auto_increment,
value1 varchar(45) not null default '',
value2 varchar(45) not null default '',
value3 varchar(45) not null default ''
);
在表上创建一个唯一索引
create unique index unq_value1_value2 on test(value1,value2);
先在数据库中插入一条数据
select * from test;
insert into test
(value1,value2,value3)
value
('123','123','123');
数据如下图:
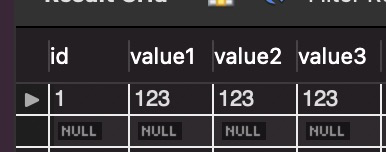
之后可以再对表中插入同样的数据,并使用duplicate key on update语法
当出现重复key时, 将vakue3的值设置为’1234’,语句如下:
insert into test
(value1,value2,value3)
value
('123','123','123')
on duplicate key update
value3 = '1234';
执行完,查询表数据,显示如下:
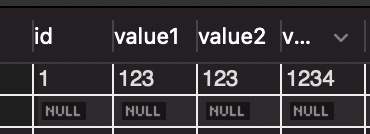
可见,on duplicate key update语句生效
二、存在问题
1、但表中存在多个唯一索引时,如果插入数据对多个唯一索引都产生了冲突,且冲突不在同一条记录上时,因为mysql并不会返回所有的冲突行,仅会返回其中任意一条记录,将产生修改记录不确定都问题冲突不在同一行,例子如下:
假设表中value1,value两个字段都有唯一索引,表中有两条记录如下:
id value1 value2
1 1 2
2 2 1
此时,执行一下语句:
insert into test
(value1,value2)
values
('1','1')
on duplicate key update
value3 = '1234'
此时,产生冲突的数据就为两条了,而mysql只会修改其中一条的记录
2、并发插入同一条数据时,将产生死锁
3、将造成主从不一致问题
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

MySQL建立唯一索引实现插入重复自动更新
前言 在我们往数据库插入数据的时候,需要判断某个字段是否存在,如果存在则执行更新操作,如果不存在则执行插入操作,如果每次首先查询一次判断是否存在,再执行插入或者更新操作,就十分不方便.下面给大家分享个方法,方便大家实现这一功能,下面来一起看看吧. ON DUPLICATE KEY UPDATE 这个时候可以给这个字段(或者几个字段)建立唯一索引,同时使用以下 sql 语句进行插入或更新操作: INSERT INTO table (id, user_id, token) VALUES (NULL,
-
Mysql避免重复插入数据的4种方式
最常见的方式就是为字段设置主键或唯一索引,当插入重复数据时,抛出错误,程序终止,但这会给后续处理带来麻烦,因此需要对插入语句做特殊处理,尽量避开或忽略异常,下面我简单介绍一下,感兴趣的朋友可以尝试一下: 这里为了方便演示,我新建了一个user测试表,主要有id,username,sex,address这4个字段,其中主键为id(自增),同时对username字段设置了唯一索引: 01 insert ignore into 即插入数据时,如果数据存在,则忽略此次插入,前提条件是插入的数据字段设置了
-
深入mysql "ON DUPLICATE KEY UPDATE" 语法的分析
mysql "ON DUPLICATE KEY UPDATE" 语法如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE:如果不会导致唯一值列重复的问题,则插入新行. 例如,如果列 a 为 主键 或 拥有UNIQUE索引,并且包含值1,则以下两个语句具有相同的效果: 复制代码 代码如下: INSERT INTO TABLE (a,c) VALUES
-
mysql ON DUPLICATE KEY UPDATE重复插入时更新方式
目录 mysql当插入重复时更新的方法 第一种方法 第二种方法 第三种方法 Mysql on duplicate key update 解决插入重复数据时更新值的问题以及其存在的问题 一.使用 二.存在问题 mysql当插入重复时更新的方法 第一种方法 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句: INSERT INTO clients (client_id,client_name,client_type) SELECT supplie
-
mysql ON DUPLICATE KEY UPDATE语句示例
MySQL 自4.1版以后开始支持INSERT - ON DUPLICATE KEY UPDATE语法,使得原本需要执行3条SQL语句(SELECT,INSERT,UPDATE),缩减为1条语句即可完成.例如ipstats表结构如下: 复制代码 代码如下: CREATE TABLE ipstats (ip VARCHAR(15) NOT NULL UNIQUE,clicks SMALLINT(5) UNSIGNED NOT NULL DEFAULT '0'); 原本需要执行3条SQL语句,如下:
-
mysql insert的几点操作(DELAYED,IGNORE,ON DUPLICATE KEY UPDATE )
INSERT语法 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [(col_name,...)] VALUES ({expr | DEFAULT},...),(...),... [ ON DUPLICATE KEY UPDATE col_name=expr, ... ] 或: INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INT
-
详解MySQL主键唯一键重复插入解决方法
目录 解决方案: 1. IGNORE 2. REPLACE 3. ON DUPLICATE KEY UPDATE 我们插入数据的时候,有可能碰到重复数据插入的问题,但是这些数据又是不被允许有重复值: CREATE TABLE stuInfo ( id INT NOT NULL COMMENT '序号', name VARCHAR(20) NOT NULL DEFAULT '' COMMENT '姓名', age INT NOT NULL DEFAULT 0 COMMENT '年龄', PRIMA
-
MYSQL的REPLACE和ON DUPLICATE KEY UPDATE语句介绍解决问题实例
在对看看的后台进行排序的时候,遇到了一个像这样的需求,在电影表中有ID(主键自增)和orderby(排序字段) ,假设有十条数据id分别从1-10之间,对应的orderby也是从1-10之间,我现在想把id=9的数据移动到第三的位置(id=3)的这个位置,并且保证之前的数据排列顺序(即id=3的orderby=4,id=4的orderby=5-id=8的orderby=9),这样如果用循环的形式是可以解决数据的问题,但是这样操作数据库过程太多,现在就想用一条sql语句来解决这个问题. 下面来看看
-
MySQL的Replace into 与Insert into on duplicate key update真正的不同之处
看下面的例子吧: 1 Replace into ...1.1 录入原始数据mysql> use test;Database changedmysql> mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c;ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ;Query OK, 1 row affected (0.03 sec)Records: 1 Duplic
-
Mysql中Insert into xxx on duplicate key update问题
例如,如果列a被定义为unique,并且值为1,则下列语句有同样的效果,也就是说一旦出入的记录中存在a=1的情况,直接更新c = c + 1,而不执行c = 3的操作. 复制代码 代码如下: insert into table(a, b, c) values (1, 2, 3) on duplicate key update c = c + 1;1 update table set c = c + 1 where a = 1; 另外值得一提的是,这个语句知识mysql中,而标准sql语句中是没有
-
mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点实例分析
本文实例讲述了mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点.分享给大家供大家参考,具体如下: replace into和insert into on duplicate key update都是为了解决我们平时的一个问题 就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录. 我们创建一个测试表test CREATE TABLE `test` ( `id` int(11) unsigned N
-
SQL语句中的ON DUPLICATE KEY UPDATE使用
目录 一:主键索引,唯一索引和普通索引的关系 主键索引 唯一索引: 普通索引: 二:ON DUPLICATE KEY UPDATE使用测试(MYSQL下的Innodb引擎) 1:ON DUPLICATE KEY UPDATE功能介绍: 2:ON DUPLICATE KEY UPDATE测试样例+总结: 总结: 一:主键索引,唯一索引和普通索引的关系 主键索引 主键索引是唯一索引的特殊类型. 数据库表通常有一列或列组合,其值用来唯一标识表中的每一行.该列称为表的主键. 在数据库关系图中为表定义一个