教你快速上手Selenium爬虫,万物皆可爬
目录
- 一、基本使用
- 二、查找节点
- 2.1 查找单个节点
- 2.2 查找多个节点
- 三、节点交互
- 四、动作链
- 五、执行 JavaScript 代码
- 六、获取节点信息
- 七、管理 Cookies
- 八、改变节点属性的值
一、基本使用
selenium 的基本使用步骤:
- 打开浏览器;
- 获取浏览器页面的特定内容;
- 控制浏览器页面上的控件,如向一个文本框中输入一个字符串;
- 关闭浏览器。
示例:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
browser = webdriver.Chrome()
try:
browser.get('https://www.jd.com')
input_t = browser.find_element_by_id('key')
input_t.send_keys('python爬虫')
input_t.send_keys(Keys.ENTER) # 模拟按下Enter键位
wait = WebDriverWait(browser, 4) # 设置最长等待时间4秒
wait.until(ec.presence_of_all_elements_located((By.ID, 'J_goodsList')))
print(browser.title) # 显示搜索页面的标题
print(browser.current_url)
print(browser.page_source)
browser.close()
except Exception as e:
print(e)
browser.close()
二、查找节点
2.1 查找单个节点
html 源码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>表单</title>
</head>
<body>
<script>
function onclick_form(){
alert(document.getElementById('name').value +
document.getElementById('age').value +
document.getElementsByName('country')[0].value+
document.getElementsByClassName('myclass')[0].value)
}
</script>
姓名:<input id="name"><p></p>
年龄:<input id="age"><p></p>
国家:<input name="country"><p></p>
收入:<input class="myclass"><p></p>
<button onclick="onclick_form()">提交</button>
</body>
</html>
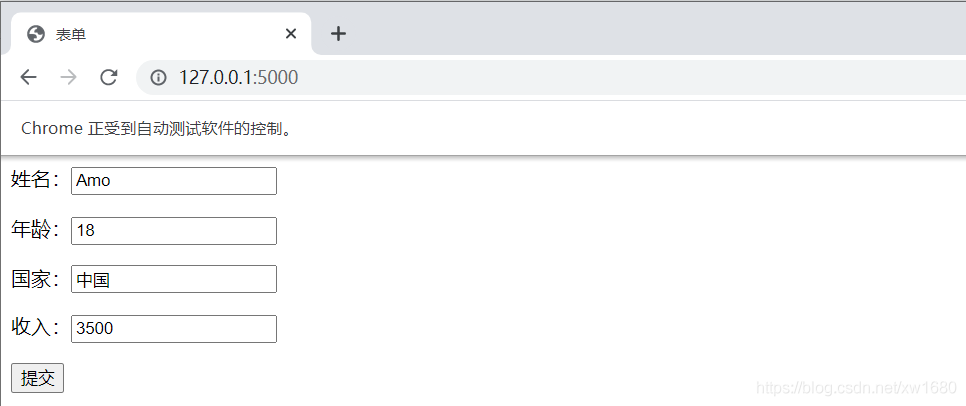
样式如下图所示:

python 代码自动填充上图中的表单:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 不支持本地网页
browser = webdriver.Chrome()
try:
# 这里我是用flask自己搭建的一个服务 访问该页面即可打开demo.html
browser.get('http://127.0.0.1:5000/')
input_t = browser.find_element_by_id('name') # 通过id属性查找姓名input节点
input_t.send_keys('Amo') # 自动输入
input_t = browser.find_element_by_id('age')
input_t.send_keys('18')
input_t = browser.find_element_by_name('country') # 通过name属性查找国家input节点
input_t.send_keys('中国')
# 通过class属性查找收入input节点
input_t = browser.find_element_by_class_name('myclass')
input_t.send_keys('1850')
# 或下面的代码
input_t = browser.find_element(By.CLASS_NAME, 'myclass')
# 要想覆盖前面的输入,需要清空input节点,否则会在input节点原来的内容后面追加新内容
input_t.clear()
input_t.send_keys('3500')
except Exception as e:
print(e)
browser.close()
效果如下图所示:
2.2 查找多个节点
示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 不支持本地网页
browser = webdriver.Chrome()
try:
browser.get('https://www.jd.com') # 打开京东
# 根据节点名查找所有名为li的节点
li_list = browser.find_elements_by_tag_name('li')
# 输出节点本身
print(li_list)
print(len(li_list))
print(li_list[0].text)
ul = browser.find_elements(By.TAG_NAME, 'ul')
print(ul)
print(ul[0].text)
browser.close()
except Exception as e:
print(e)
browser.close()
三、节点交互
使用 selenium 通过模拟浏览器单击动作循环单击页面上的6个按钮,单击每个按钮后,按钮下方的 div 就会按照按钮的背景颜色设置 div 的背景色。
demo1.html 静态页面代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>彩色按钮</title>
</head>
<body>
<script>
function onclick_color(e) {
document.getElementById("bgcolor").style.background = e.style.background
}
</script>
<button class="mybutton" style="background: red" onclick="onclick_color(this)">按钮1</button>
<button class="mybutton" style="background: blue" onclick="onclick_color(this)">按钮2</button>
<button class="mybutton" style="background: yellow" onclick="onclick_color(this)">按钮3</button>
<br>
<button class="mybutton" style="background: green" onclick="onclick_color(this)">按钮4</button>
<button class="mybutton" style="background: blueviolet" onclick="onclick_color(this)">按钮5</button>
<button class="mybutton" style="background: gold" onclick="onclick_color(this)">按钮6</button>
<p></p>
<div id="bgcolor" style="width: 200px; height: 200px">
</div>
</body>
</html>
然后使用 Python 代码模拟浏览器的单击动作自动单击页面上的 6 个按钮。P
ython 代码如下所示:
from selenium import webdriver
import time
browser = webdriver.Chrome()
try:
browser.get('http://127.0.0.1:5000/')
buttons = browser.find_elements_by_class_name('mybutton')
i = 0
while True:
buttons[i].click()
time.sleep(1)
i += 1
if i == len(buttons):
i = 0
except Exception as e:
print(e)
browser.close()
四、动作链
使用 selenium 动作链的 move_to_element 方法模拟鼠标移动的动作,自动显示京东商城首页左侧的每个二级导航菜单。
示例代码如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
try:
browser.get('https://www.jd.com')
actions = ActionChains(browser)
li_list = browser.find_elements_by_css_selector(".cate_menu_item")
for li in li_list:
actions.move_to_element(li).perform()
time.sleep(1)
except Exception as e:
print(e)
browser.close()
使用 selenium 动作链的 drag_and_drop 方法将一个节点拖动到另外一个节点上。
示例代码如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
try:
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
except Exception as e:
print(e)
browser.close()
五、执行 JavaScript 代码
使用 selenium 的 execute_script 方法让京东商城首页滚动到最低端,然后弹出一个对话框。示
例代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_async_script('alert("已经到达页面底端")')
六、获取节点信息
使用 selenium 的 API 获取京东商城首页 HTML 代码中 id 为 navitems-group1 的 ul 节点的相关信息以及 ul 节点中 li 子节点的相关信息。
示例代码如下:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome(chrome_options=options)
# browser = webdriver.PhantomJS('./webdriver/phantomjs')
browser.get('https://www.jd.com')
ul = browser.find_element_by_id("navitems-group1")
print(ul.text)
print('id', '=', ul.id) # 内部id,不是节点id属性值
print('location', '=', ul.location)
print('tag_name', '=', ul.tag_name)
print('size', '=', ul.size)
li_list = ul.find_elements_by_tag_name("li")
for li in li_list:
print(type(li))
# 属性没找到,返回None
print('<', li.text, '>', 'class=', li.get_attribute('class'))
a = li.find_element_by_tag_name('a')
print('href', '=', a.get_attribute('href'))
browser.close()
执行结果如下:
秒杀
优惠券
PLUS会员
品牌闪购
id = 6bb622fb-df60-4619-a373-b55e44dc27af
location = {'x': 203, 'y': 131}
tag_name = ul
size = {'height': 40, 'width': 294}
<class 'selenium.webdriver.remote.webelement.WebElement'>
< 秒杀 > class= fore1
href = https://miaosha.jd.com/
<class 'selenium.webdriver.remote.webelement.WebElement'>
< 优惠券 > class= fore2
href = https://a.jd.com/
<class 'selenium.webdriver.remote.webelement.WebElement'>
< PLUS会员 > class= fore3
href = https://plus.jd.com/index?flow_system=appicon&flow_entrance=appicon11&flow_channel=pc
<class 'selenium.webdriver.remote.webelement.WebElement'>
< 品牌闪购 > class= fore4
href = https://red.jd.com/
七、管理 Cookies
使用 selenium API 获取 cookie 列表,并添加新的 cookie,以及删除所有的 cookie。
示例代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
print(browser.get_cookies())
browser.add_cookie({'name': 'name',
'value': 'jd', 'domain': 'www.jd.com'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies()) # 大部分删除了,可能还剩下一些
八、改变节点属性的值
通过 javascript 代码改变百度搜索按钮的位置,让这个按钮在多个位置之间移动,时间间隔是2秒。
示例代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
search_button = driver.find_element_by_id("su") # 百度搜索按钮
# arguments[0]对应的是第一个参数,可以理解为python里的%s传参,与之类似
x_positions = [50, 90, 130, 170]
y_positions = [100, 120, 160, 90]
for i in range(len(x_positions)):
js = '''
arguments[0].style.position = "absolute";
arguments[0].style.left="{}px";
arguments[0].style.top="{}px";
'''.format(x_positions[i], y_positions[i])
driver.execute_script(js, search_button)
time.sleep(2)
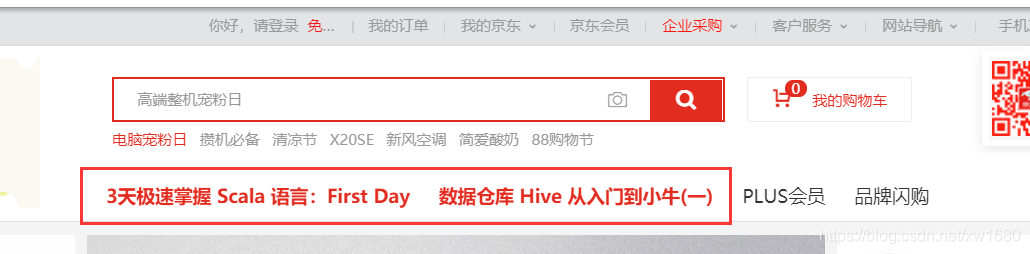
使用 javascript 代码修改京东商城首页顶端的前两个导航菜单的文本和链接,分别改成 ‘3天极速掌握 Scala 语言:First Day' 和 ‘数据仓库 Hive 从入门到小牛(一)',导航链接也会发生改变。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.jd.com")
ul = driver.find_element_by_id('navitems-group1')
li_list = ul.find_elements_by_tag_name('li')
a1 = li_list[0].find_element_by_tag_name('a')
a2 = li_list[1].find_element_by_tag_name('a')
js = '''
arguments[0].text = '3天极速掌握 Scala 语言:First Day'
arguments[0].href = 'https://blog.csdn.net/xw1680/article/details/118743183'
arguments[1].text = '数据仓库 Hive 从入门到小牛(一)'
arguments[1].href = 'https://blog.csdn.net/xw1680/article/details/118675528'
'''
driver.execute_script(js, a1, a2)
效果如下图所示:
到此这篇关于教你快速上手Selenium爬虫,万物皆可爬的文章就介绍到这了,更多相关Selenium爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python利用selenium进行浏览器爬虫
前言 相信大家刚开始在做爬虫的时候,是不是requests和sound这两个库来使用,这样确实有助于我们学习爬虫的知识点,下面来介绍一个算事较复杂的爬虫案例selenium进形打开浏览器爬取网站的信息 导入第三方库 自执行函数 解析信息 保存文件信息 打开浏览器 获取链接信息 执行函数 运行结果 总结 以上所述是小编给大家介绍的python利用selenium进行浏览器爬虫,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持! 如果你觉得本
-

python实现selenium网络爬虫的方法小结
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器. 1.selenium初始化 方法一:会打开网页 # 该方法会打开goole网页 from selenium import webdriver url = '网址' driver = webdriver.Chrom
-
Python3爬虫中Selenium的用法详解
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击.下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬.对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效.本节中,就让我们来感受一下它的强大之处吧. 1. 准备工作 本节以Chrome为例来讲解Selenium的用法.在开始之前,请确保已经正确安装好了Chrome浏览器并配置好了ChromeDriver.另外,还需要正确安装好Python的Selenium库,详细的安装和配置过程
-
利用selenium爬虫抓取数据的基础教程
写在前面 本来这篇文章该几个月前写的,后来忙着忙着就给忘记了. ps:事多有时候反倒会耽误事. 几个月前,记得群里一朋友说想用selenium去爬数据,关于爬数据,一般是模拟访问某些固定网站,将自己关注的信息进行爬取,然后再将爬出的数据进行处理. 他的需求是将文章直接导入到富文本编辑器去发布,其实这也是爬虫中的一种. 其实这也并不难,就是UI自动化的过程,下面让我们开始吧. 准备工具/原料 1.java语言 2.IDEA开发工具 3.jdk1.8 4.selenium-server-standa
-
python 爬虫之selenium可视化爬虫的实现
之所以把selenium爬虫称之为可视化爬虫 主要是相较于前面所提到的几种网页解析的爬虫方式 selenium爬虫主要是模拟人的点击操作 selenium驱动浏览器并进行操作的过程是可以观察到的 就类似于你在看着别人在帮你操纵你的电脑,类似于别人远程使用你的电脑 当然了,selenium也有无界面模式 快速入门 selenium基本介绍: selenium 是一套完整的web应用程序测试系统, 包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Contro
-
教你快速上手Selenium爬虫,万物皆可爬
目录 一.基本使用 二.查找节点 2.1 查找单个节点 2.2 查找多个节点 三.节点交互 四.动作链 五.执行 JavaScript 代码 六.获取节点信息 七.管理 Cookies 八.改变节点属性的值 一.基本使用 selenium 的基本使用步骤: 打开浏览器: 获取浏览器页面的特定内容: 控制浏览器页面上的控件,如向一个文本框中输入一个字符串: 关闭浏览器. 示例: from selenium import webdriver from selenium.webdriver.commo
-
快速搭建python爬虫管理平台
爬虫有多重要 对搜索引擎来说,爬虫不可或缺:对舆情公司来说,爬虫是基础:对 NLP来说,爬虫可以获取语料:对初创公司来说,爬虫可以获取初始内容.但是爬虫技术纷繁复杂,不同类型的抓取场景会运用到不同的技术.例如,简单的静态页面可以用 HTTP 请求+HTML 解析器直接搞定:一个动态页面需要用 Puppeteer 或 Selenium等自动化测试工具:有反爬的网站需要用到代理.打码等技术:等等.那么此时就需要一个成熟的爬虫管理平台,帮助企业或个人处理大量的爬虫类别. 理解什么是爬虫管理平台 定义
-
Playwright快速上手指南(入门教程)
目录 1. 为什么选择Playwright 1.1 Playwright的优势 1.2 已知局限性 2. Playwright使用 2.1 安装 2.2 自动录制 2.3 定制化编写 2.4 网络拦截(Mock接口),示例如下: 2.6 异步执行,示例如下: 2.7 Pytest结合,示例如下: 2.8 移动端操作,示例如下: 3. 总结 Playwright是由微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium.Fi
-
手把手教你搭建python+selenium自动化环境(图文)
目录 第一步:安装python解释器 第二步:安装pycharm编译器. 第三步:安装selenium库 第四步:下载浏览器的驱动 第五步:打开pycharm写第一个自动化demo验证环境是否有问题 快速+简单搭建环境.如果有问题,欢迎进群讨论留言. 第一步:安装python解释器 官网地址:https://www.python.org/ 自动化测试最好下载3.7的. 下载完成后打开这个文件,然后傻瓜式安装. 安装好后,win+r打开命令行窗口,输入python.如果显示下图,就说明安装成功.
-
Ruby和元编程之万物皆为对象
开篇 空即是色,色即是空. 空空色色,色色空空,在Ruby语言中,万物皆为对象. Ruby是一个面向对象的语言(Object Oriented Language),面向对象的概念比其他语言要贯彻的坚定很多. Ruby中不存在Java中原始类型数据和对象类型数据之分.大部分Ruby中的的东东都是对象. 所以,想要掌握Ruby和Ruby的元编程,对象就是第一门必修功课.本回就着重研究一下Ruby中的对象. Ruby中的对象 如果你从其他面向对象的语言转来,一提到得到一个对象你可能会想到建立一个类,然
-
javascript 面向对象编程 万物皆对象
javascript和java.C#等语言一样也具有面向对象的一些特征,但细比较的时候,会发现这些特征并不是真正的面向对象,很多地方都是利用对象本身来模拟面向对象,所以认为javascript不能算是面向对象编程语言,而是基于对象的语言. 在javascript中真的是万物皆对象,new出来的东西是对象,方法是对象,连类也都是对象.下面分别来看一下对象.方法和类的对象特征. 1.拿内置的Date来看一下吧 复制代码 代码如下: var time = new Date(); var timeStr
-
gulp教程_从入门到项目中快速上手使用方法
gulp是什么? gulp 是基于 node 实现 Web 前端自动化开发的工具,利用它能够极大的提高开发效率.在 Web 前端开发工作中有很多"重复工作",比如压缩CSS/JS文件.而这些工作都是有规律的.找到这些规律,并编写 gulp 配置代码,让 gulp 自动执行这些"重复工作" 一.安装gulp与压缩js文件 命令: npm install gulp -g npm install gulp --save-dev 初始化项目package.json的配置:n
-
smarty半小时快速上手入门教程
本文讲述了smarty快速上手入门的方法,可以让读者在半小时内快速掌握smarty的用法.分享给大家供大家参考.具体实现方法如下: 一.smarty的程序设计部分: 在smarty的模板设计部分我简单的把smarty在模板中的一些常用设置做了简单的介绍,这一节主要来介绍一下如何在smarty中开始我们程序设计.下载Smarty文件放到你们站点中. index.php代码如下: 复制代码 代码如下: <?php /** * * @version $Id: index.php * @package
-
JavaWeb工程中集成YMP框架快速上手(二)
本文将介绍如何在Java Web工程中集成YMP框架,操作过程基于IntelliJ IDEA做为开发环境,工程结构采用Maven构建: IntelliJ IDEA下载地址: https://www.jetbrains.com/idea/download/ Maven下载地址: http://maven.apache.org/ 创建项目 1. 打开IDEA开发环境并点击Create New Project按钮开始创建新项目向导,如下图-1所示: 2. 在New Project窗口中选中左侧Mave
-
Python如何快速上手? 快速掌握一门新语言的方法
那么Python如何快速上手?找来了一篇广受好评的新语言学习方法介绍,供大家参考. 听说,你决定要为你的 "技能树" 再添加一门特定的编程语言.那该怎么办呢? 在这篇文章中,作者提出了 12 项关于学习技术的建议.记住每个人学习的方式都不一样.其中一些可能对你十分有用,而其他的则可能无法满足你的需求.如果你开始担心一个策略,请尝试另一个策略并看看它哪里适合你. 1. 将其与类似的语言进行比较.当你首次观看有关该语言的第一个教程或阅读代码时,请尝试猜测该语言的每个部分将会做什么,并检查你