pandas去除重复值的实战
目录
- 加载数据
- sample抽样函数
- 指定需要更新的值
- append直接添加
- append函数用法
- 根据某一列key值进行去重(key唯一)
加载数据
首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的。
import pandas as pd
#这里说明一下,clean_beer.csv数据有两千多行数据
#所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习
data = pd.read_csv('clean_beer.csv')
data_sam = data.sample(frac=0.1,weights=data['ounces'].values)
data_sam1 = data_sam
data_sam
我们采用data[‘ounces']列为权重对数据进行采样,并将结果赋值给data_sam1,其中data_sam和data_sam1是后续我们需要用到的两个数据(因为需要将两个数据合并,并去除重复)
此时,data_sam和data_sam1的数据是一样的。
data_sam数据
data_sam

data_sam1数据
data_sam1
sample抽样函数
简要介绍一下sample函数
df.sample()就是抽样函数,参数如下:
df.sample(n=None,frac=None,replace=Flase,weights=None,random_state=None,axis=None)
参数说明:
**n:**就是样本量,如果不写,就是抽一条数据
**frac:**抽样比,就是样本量占全样本的比例,如frac=0.3 ,注意n和frac不能共存
replace:是否放回,默认是不放回,如果有放回(replace=True)可以选择比df长度更多的元素回来
weights:样本权重,自动归一化,可以以某一列为权重
random_state:随机状态。就是为了保证程序每次运行得到的结果都一样
axis:抽样维度,0是行,1是列,默认为0
指定需要更新的值
接下来,我们对data_sam1的值进行更新,主要是将data_sam1的ounces属性列值加上后缀'.0 oz',具体代码如下:
data_sam1['ounces'] = data_sam1['ounces'].astype('str') + '.0 oz'
data_sam1
对data_sam1的值进行显示,其中我们可以看到,ounces的值已经全部加上了我们所指定的后缀:

现在,我们已经得到的新的值,接下来的目标就是如何将我们已经得到的新值,更新到data_sam中
append直接添加
从标题可以看到,我们使用的是append方法进行直接添加。
data_sam = data_sam.append(data_sam1,ignore_index=True) data_sam
我们将data_sam1使用append方法添加到data_sam最后一行的后面。下面展示其结果,并详细介绍append的用法。
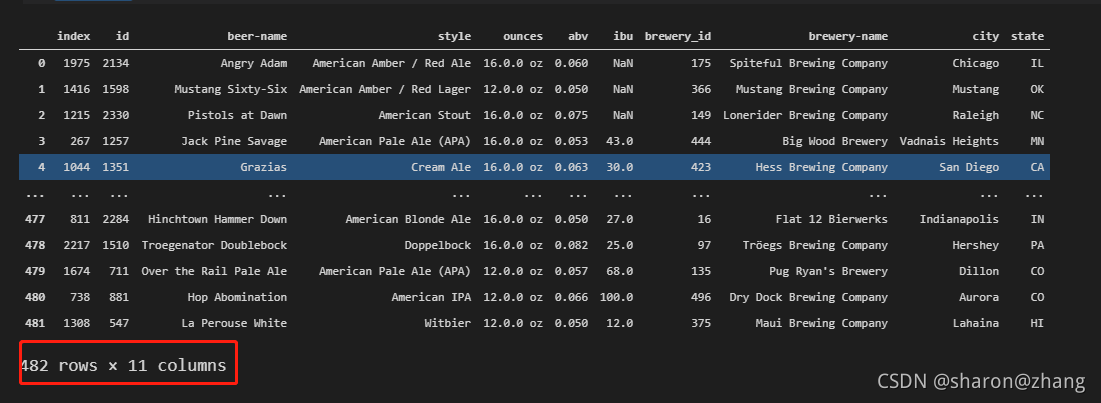
可以看到,行数已经有原来的241改为现在的482rows,显然我们此时已经成功使用append添加数据成功。不过我们想要的不止是简简单单的添加数据在最后一行,而是想要把我们增加后缀的那一列更新到原来的数据中,所以最后一步就是去重。
append函数用法
append()函数的语法为:
DataFrame.append(other,ignore_index=False,verify_integrity=False,sort=None)
参数说明:
- other: DataFrame,Series或Dict式对象,其行将添加到调用方DataFrame中。
- ignore_index: 如果为True,则将忽略源DataFrame对象中的索引。
- verify_integrity:如果为True,则在创建具有重复项的索引时引发ValueError 。
- sort: 如果源DataFrame列未对齐,则对列进行排序。 不建议使用此功能。 因此,我们必须传递sort=True来排序和静音警告消息。 如果传递了sort=False ,则不会对列进行排序,并且会忽略警告。
根据某一列key值进行去重(key唯一)
接下来,就是最后一个步骤,也就是根据ounces列对数据进行去重。
通过duplicated()函数可以看到数据还是有很多重复的。
data_sam.duplicated(['id'],keep='first')
DataFrame.drop_duplicated(self,subset = None,keep ='first')
subset : 列标签或标签序列,可选仅考虑某些列来标识重复项,默认情况下使用所有列
keep : {'first','last',False},默认为'first'
first:将重复项标记True为第一次出现的除外。
last:将重复项标记True为最后一次除外。
False:将所有重复项标记为True。
既然知道数据中是有重复项的,通过对数据的观察可以看到,数据的id是唯一的,所以我们以id这一列为契机,来进行我们的去重操作。具体代码如下:
data_sam = data_sam.drop_duplicates(subset = 'id') data_sam
最后来看一看,我们最后的结果是不是已经成功去重,或者说是不是我们想要的最终结果呢???
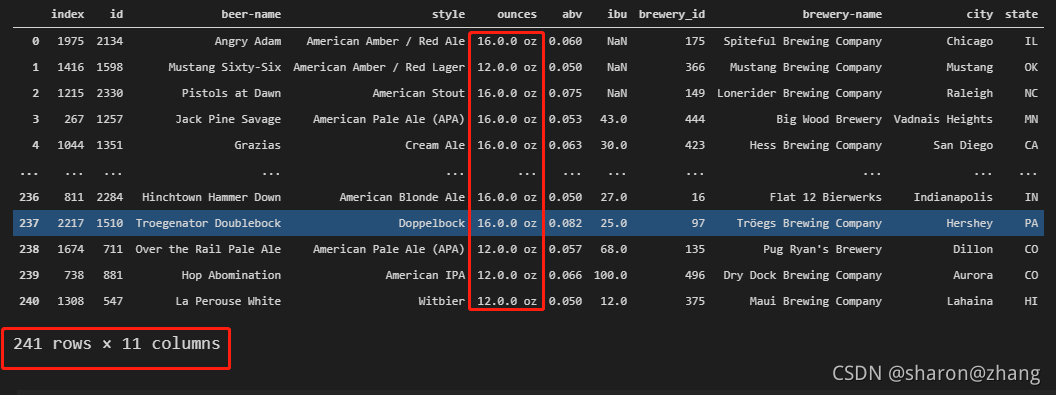
根据上面的图片结果,可以看到我们已经执行成功,得到的确实是我们起初想要的一个数据结果。有兴趣的也可以去试一下merge和update联合的操作进行更新数据,看看是不是也能成功。
到此这篇关于pandas去除重复值的实战的文章就介绍到这了,更多相关pandas去除重复值内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pandas中DataFrame检测重复值的实现
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重 DataFrame.duplicated(subset=None, keep='first') subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面.默认是所有字段重复为重复数据. keep: 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True. 如果为'last',也就是如果有重复数据,则最后一条出现的定义为Fa
-
pandas统计重复值次数的方法实现
本文主要介绍了pandas统计重复值次数的方法实现,分享给大家,具体如下: from pandas import DataFrame df = DataFrame({'key1':['a','a','b','b','a','a'], 'key2':['one','two','one','two','one','one'], 'data1':[1,2,3,2,1,1], # 'data2':np.random.randn(5) }) # 打印数据框 print(df) # data1 key1 k
-
pandas去除重复值的实战
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
字符串聚合函数(去除重复值)
--功能:提供字符串的替代聚合函数 --说明:例如,将下列数据 --test_id test_value -------------------- 'a' '01,03,04' 'a' '02,04' 'b' '03,04,08' 'b' '06,08,09' 'c' '09' 'c' '10' --转换成test_vlaue列聚合后的函数,且聚合后的字符串中的值不重复 --test_id test_value -------------------- 'a' '01,03,04,02' 'b'
-
hashset去除重复值原理实例解析
Java中的set是一个不包含重复元素的集合,确切地说,是不包含e1.equals(e2)的元素对.Set中允许添加null.Set不能保证集合里元素的顺序. 在往set中添加元素时,如果指定元素不存在,则添加成功.也就是说,如果set中不存在(e==null?e1==null:e.queals(e1))的元素e1,则e1能添加到set中. 下面以set的一个实现类HashSet为例,简单介绍一下set不重复实现的原理: package com.darren.test.overide; publ
-
js数组中去除重复值的几种方法
在日常开发中,我们可能会遇到将一个数组中里面的重复值去除,那么,我就将我自己所学习到的几种方法分享出来 去除数组重复值方法: 1,利用indexOf()方法去除 思路:创建一个新数组,然后循环要去重的数组,然后用新数组去找要去重数组的值,如果找不到则使用.push添加到新数组,最后把新数组返回回去就行了 看不懂没关系,上代码就比较容易懂了 function fun(arr){ let newsArr = []; for (let i = 0; i < arr.length; i++) { if(
-
mysql实现合并结果集并去除重复值
目录 mysql 合并结果集并去除重复值 mysql 合并结果集(union,union all) union 与 union all 执行结果不同 对UNION,UNION ALL的结果继续处理,需要加括号 mysql中,UNION,UNION ALL的性能/效率不同 总结 mysql 合并结果集并去除重复值 SELECT DISTINCT c.parent_id from ( SELECT parent_id FROM tp_goods_category a join tp_goo
-
awk实现Left、join查询、去除重复值以及局部变量讲解例子
最近看到论坛里面有几个不错的小例子,对于学习awk还是有帮助,在这儿详细的说一下 一.类似数据库中的left join查询 复制代码 代码如下: [root@krlcgcms01 mytest]# cat a.txt //a.txt 111 aaa 222 bbb 333 cccc 444 ddd [root@krlcgcms01 mytest]# cat b.txt //b.txt 111 123 456 2 abc cbd 444 rts 786
-
详解JavaScript数组和字符串中去除重复值的方法
原理在代码中表现得非常清晰,我们直接来看代码例子: var ages = array.map(function(obj) { return obj.age; }); ages = ages.filter(function(v,i) { return ages.indexOf(v) == i; }); console.log(ages); //=> [17, 35] function isBigEnough(element) { return element >= 10; } var filte
-
pandas去除重复列的实现方法
数据准备 假设我们目前有两个数据表: ① 一个数据表是关于三个人他们的id以及其他的几列属性信息 import pandas as pd import numpy as np data = pd.DataFrame(np.random.randint(low=1,high=20,size=(3,4))) data['id'] = range(1,4) # 输出:其中,最左边的0 1 2 为其索引 ② 另外一个数据表是3个用户的app操作日志信息,一个人会有多条app操作记录 sample = p
-
js数组中删除重复值的代码小结
js数组中去除重复值 Array.prototype.del = function() { var a = {}, c = [], l = this.length; for (var i = 0; i [Ctrl+A 全选 注:如需引入外部Js需刷新才能执行] 方法二 复制代码 代码如下: //去重复数组 function unique(data){ data = data || []; var a = {}; len = data.length; for (var i=0; i<len;i++