Python数据分析之彩票的历史数据
一、需求介绍
该需求主要是分析彩票的历史数据
客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票
对于1、,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5;
对于2、,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10。

然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖的次数以及分别所对应的时间,对于这个案例,我们下面详细分析。
二、数据分析
(在这里,我们先利用 Jupyter Notebook 来进行分析,然后,在得到成果以后,利用 Pycharm 来进行完整的程序设计。)
2.1 获取一天的数据
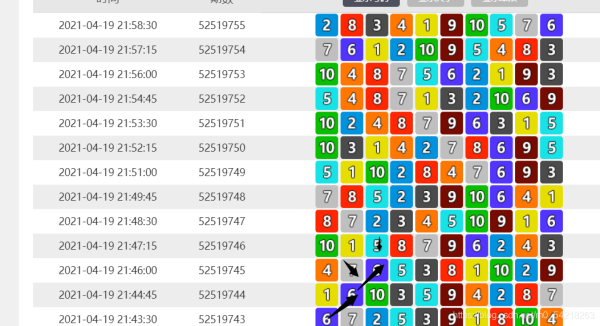
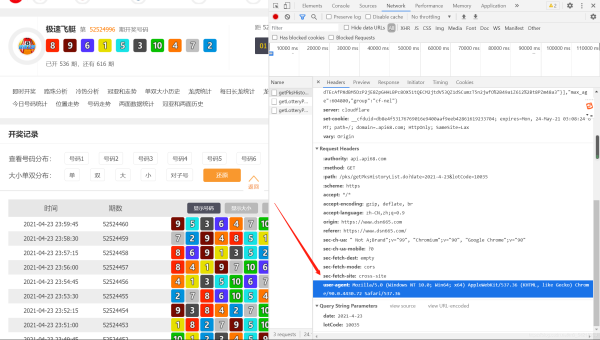
打开如下图所示的界面可以获取到网址以及请求头:
网址(历史数据的网址)

请求头
然后我们在程序中进行代码书写获取数据:

然后进行一定的预处理:

2.2 开始一天的数据的分析
这里我们直接展示代码:
def reverse_list(lst):
"""
准换列表的先后顺序
:param lst: 原始列表
:return: 新的列表
"""
return [ele for ele in reversed(lst)]
low_list = ["01", "02", "03", "04", "05"]
# 设置比较小的数字的列表
high_list = ["06", "07", "08", "09", "10"]
# 设置比较大的数字的列表
N = 0
# 设置一个数字N来记录一共有多少期可以购买
n = 0
# 设置一个数字n来记录命中了多少期彩票
record_number = 1
# 设置记录数据的一个判断值
list_data_number = []
# 设置一个空的列表来存储一天之中的连续挂掉的期数
dict_time_record = {}
# 设置一个空的字典来存储连挂掉的期数满足所列条件的时间节点
for k in range(1152):
# 循环遍历所有的数据点
if k < 1150:
new_result1 = reverse_list(new_response["result"]["data"])[k]
# 第一期数据
new_result2 = reverse_list(new_response["result"]["data"])[k + 1]
# 第二期数据
new_result3 = reverse_list(new_response["result"]["data"])[k + 2]
# 第三期数据
data1 = new_result1['preDrawCode'].split(',')
# 第一期数据
data2 = new_result2['preDrawCode'].split(',')
# 第二期数据
data3 = new_result3['preDrawCode'].split(',')
# 第三期数据
for m in range(10):
# 通过循环来判断是否满足购买的条件,并且实现一定的功能
if m == 0:
if data2[0] == data1[1]:
# 如果相等就要结束循环
N += 1
# 可以购买的期数应该要自加一
if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list):
n += 1
# 命中的期数应该要自加一
# 如果命中了的话,本轮结束,开启下一轮
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
# 如果已经有了这个键,那么值添加时间点
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
# 如果没有这个键,那么添加一个键值对,值为一个列表,而且初始化为当前的时间
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
record_number = 1
# 初始化下一轮的开始
else:
record_number += 1
# 如果没有命中的话,次数就应该要自加一
break
# 如果满足相等的条件就要结束循环
elif m == 9:
# 与上面差不多的算法
if data2[9] == data1[8]:
# 如果相等
N += 1
if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
record_number = 1
else:
record_number += 1
break
else:
# 与上面差不多的算法
if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:
# 如果相等
N += 1
if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
record_number = 1
else:
record_number += 1
break
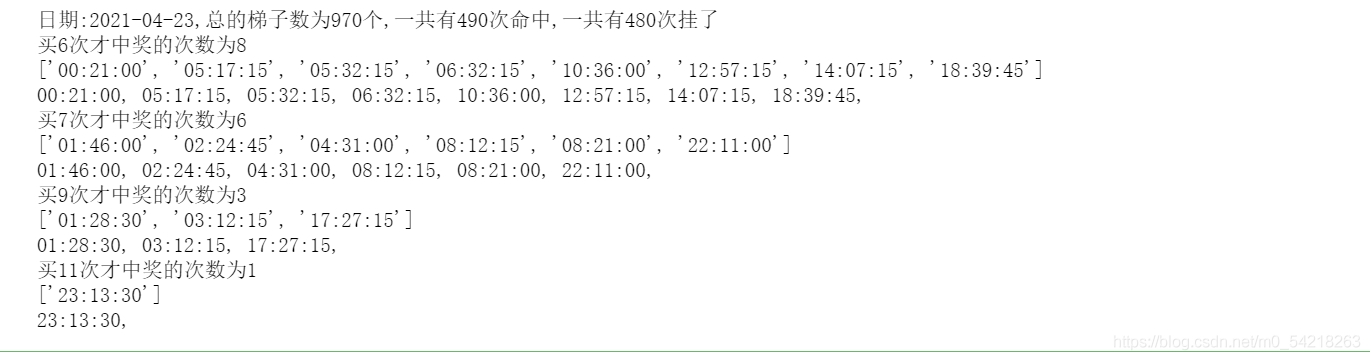
print(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")
# 打印时间,以及,可以购买的期数,命中的期数,没有命中的期数
list_data_number.sort()
# 按照大小顺序来进行排序
dict_record = {}
# 设置空字典进行记录
for i in list_data_number:
if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字?
dict_record[f"{i}"] += 1
# 如果有的话,那么就会自加一
else: # 如果没有的话,那么就会创建并且赋值等于 1
dict_record[f"{i}"] = 1
# 创建一个新的字典元素,然后进行赋值为 1
for j in dict_record.keys():
if (int(j) >= 6) and (int(j) < 15):
# 实际的结果表明,我们需要的是大于等于6期的数据,而没有出现大于15的数据,因此有这样的一个关系式
print(f"买{j}次才中奖的次数为{dict_record[j]}")
# 打印相关信息
print(dict_time_record[j])
str0 = ""
for letter in dict_time_record[j]:
str0 += letter
str0 += ", "
print(str0)
# 打印相关信息
运行结果的展示如下图所示:
2.3 循环日期进行多天的数据分析:
首先设置一个事件列表来记录需要统计哪些天的数据:
代码:
data_list = []
for h in range(31):
data_list.append(f'1-{h + 1}')
for h in range(28):
data_list.append(f'2-{h + 1}')
for h in range(31):
data_list.append(f'3-{h + 1}')
for h in range(20):
data_list.append(f'4-{h + 1}')
通过上述的代码,我们即实现了时间列表的设置,然后我们循环遍历这个列表访问不同日期的彩票数据即就是得到了不同时间的数据,然后再利用上述的分析方法来进行数据分析,即就是可以得到了多天的彩票数据分析的结果了。
2.4 将数据写入Excel表格中
这里我们可以采用xlwt 模块来进行excel表格的写入操作啦,具体的写入就不必过多赘述了。
三、完整代码
以下是完整的代码:
import requests
import chardet
import json
import xlwt # excel 表格数据处理的对应模块
def reverse_list(lst):
"""
准换列表的先后顺序
:param lst: 原始列表
:return: 新的列表
"""
return [ele for ele in reversed(lst)]
data_list = []
for h in range(31):
data_list.append(f'1-{h + 1}')
for h in range(28):
data_list.append(f'2-{h + 1}')
for h in range(31):
data_list.append(f'3-{h + 1}')
for h in range(20):
data_list.append(f'4-{h + 1}')
wb = xlwt.Workbook() # 创建 excel 表格
sh = wb.add_sheet('彩票分析数据处理') # 创建一个 表单
sh.write(0, 0, "日期")
sh.write(0, 1, "梯子数目")
sh.write(0, 2, "命中数目")
sh.write(0, 3, "挂的数目")
sh.write(0, 4, "6次中的数目")
sh.write(0, 5, "6次中的时间")
sh.write(0, 6, "7次中的数目")
sh.write(0, 7, "7次中的时间")
sh.write(0, 8, "8次中的数目")
sh.write(0, 9, "8次中的时间")
sh.write(0, 10, "9次中的数目")
sh.write(0, 11, "9次中的时间")
sh.write(0, 12, "10次中的数目")
sh.write(0, 13, "10次中的时间")
sh.write(0, 14, "11次中的数目")
sh.write(0, 15, "11次中的时间")
sh.write(0, 16, "12次中的数目")
sh.write(0, 17, "12次中的时间")
sh.write(0, 18, "13次中的数目")
sh.write(0, 19, "13次中的时间")
sh.write(0, 20, "14次中的数目")
sh.write(0, 21, "14次中的时间")
# wb.save('test4.xls')
sheet_seek_position = 1
# 设置表格的初始位置为 1
for data in data_list:
low_list = ["01", "02", "03", "04", "05"]
high_list = ["06", "07", "08", "09", "10"]
N = 0
n = 0
url = f'https://api.api68.com/pks/getPksHistoryList.do?date=2021-{data}&lotCode=10037'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/90.0.4430.72 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
new_response = json.loads(response.text)
sh.write(sheet_seek_position, 0, new_response['result']['data'][0]['preDrawTime'][:10])
# 在表格的第一个位置处写入时间,意即:data
record_number = 1 # 记录数据的一个判断值,设置为第一次,应该是要放在最外面的啦
list_data_number = []
# 设置一个空列表来存储一天之中的连续挂的期数
dict_time_record = {}
for k in range(1152):
# record_number = 1,应该要放外面
# 记录数据的一个判断值,设置为第一次
if k < 1150:
new_result1 = reverse_list(new_response["result"]["data"])[k]
new_result2 = reverse_list(new_response["result"]["data"])[k + 1]
new_result3 = reverse_list(new_response["result"]["data"])[k + 2]
data1 = new_result1['preDrawCode'].split(',')
data2 = new_result2['preDrawCode'].split(',')
data3 = new_result3['preDrawCode'].split(',')
for m in range(10):
if m == 0:
if data2[0] == data1[1]:
N += 1
if (data2[0] in low_list and data3[0] in high_list) or (data2[0] in high_list and data3[0] in low_list):
n += 1
# 如果命中了的话,本轮结束,开启下一轮
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1 # 初始化
else:
record_number += 1 # 没中,次数加一
# 自加一
break
elif m == 9:
if data2[9] == data1[8]:
N += 1
if (data2[9] in low_list and data3[9] in high_list) or (data2[9] in high_list and data3[9] in low_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
else:
if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:
N += 1
if (data2[m] in low_list and data3[m] in high_list) or (data2[m] in high_list and data3[m] in low_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
print(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")
sh.write(sheet_seek_position, 1, N)
sh.write(sheet_seek_position, 2, n)
sh.write(sheet_seek_position, 3, N - n)
# new_list_data_number = list_data_number.sort()
list_data_number.sort()
# 进行排序
dict_record = {}
# 设置空字典
for i in list_data_number:
if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字?
dict_record[f"{i}"] += 1
# 如果有的话,那么就会自加一
else: # 如果没有的话,那么就会创建并且赋值等于 1
dict_record[f"{i}"] = 1
# 创建一个新的字典元素,然后进行赋值为 1
# print(dict_record)
# print(f"买彩票第几次才中奖?")
# print(f"按照我们的规律买彩票的情况:")
for j in dict_record.keys():
if (int(j) >= 6) and (int(j) < 15):
print(f"买{j}次才中奖的次数为{dict_record[j]}")
print(dict_time_record[j])
str0 = ""
for letter in dict_time_record[j]:
str0 += letter
str0 += ", "
print(str0)
sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2, dict_record[j])
# 写入几次
sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2 + 1, str0[:-2])
# 注意这里应该要改为 -2
# 写入几次对应的时间
# print(j)
sheet_seek_position += 1
# 每次写完了以后,要对位置进行换行,换到下一行,从而方便下一行的写入
# 保存
wb.save('极速飞艇彩票分析结果.xls')
四、运行结果
展示1、
展示2、

从而,我们便解决了极速飞艇的彩票的数据分析
然后,我们只需要稍稍改变一点点算法,其他的部分是完全一样的啦,从而即就是可以实现极速赛车的数据分析了啦。
修改的代码在下面列出来了:
for m in range(10):
if m == 0:
if data2[0] == data1[1]:
N += 1
if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list):
n += 1
# 如果命中了的话,本轮结束,开启下一轮
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1 # 初始化
else:
record_number += 1 # 没中,次数加一
# 自加一
break
elif m == 9:
if data2[9] == data1[8]:
N += 1
if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
else:
if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:
N += 1
if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
五、总结
总而言之,这个就是我学习 Python 到现在为止所接的第一单啦,这个需求不得不说确实是比较简单的啦,但是,我在完成这个任务的过程中,的确是学到了以前一些我并不太注意的东西,同时呢,也熟练的掌握了一些编程的技巧,虽然说这种比较简单的活报酬不会太高,但是,我认为在这个过程中我确实学到了不少东西,同时也成长了不少,因此,无论怎么说,其实也都还是挺不错的啦。
到此这篇关于Python数据分析之彩票的历史数据的文章就介绍到这了,更多相关python分析彩票数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现的彩票机选器实例
本文实例讲述了Python实现彩票机选器的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: utf8 -*- from Tkinter import * import tkFont import random class App: def __init__(self, master) : frame = [Frame() for i in range(4)] for i in range(4): frame[i] = Frame(master) frame[i].pac
-
基于Python实现体育彩票选号器功能代码实例
一,概要 需求: 实现一个GUI界面下的 6+1体育彩票选号器. (1) 要求界面可以加载系统时间及开奖时间 (2) 功能区完成人选及机选的功能 人选 --> 手动输入6+1位数字.前6位必须在0-9之间的数字.后1位必须是0-4之间的数字 机选 --> (1) 填写数量(加校验必须为数字且不能为空)点击开始按钮后把选举的数字添加到展示界面中 (2) 允许选举的数字重复及不重复两种选择 (3) 展示区的设置,显示已选的彩票号码 (4) 完成清空展示区内容功能 (5) 完成关闭整个界面窗口功能
-
Python随机生成彩票号码的方法
本文实例讲述了Python随机生成彩票号码的方法.分享给大家供大家参考.具体如下: 前些日子在淘宝上买了一阵子彩票,每次都是使用淘宝的机选,每次一注.后来觉得不如自己写一个机选的程序有意思 1. xuanhao.py文件 import random def getResultStr(totalCount, resultCount): elements = [x + 1 for x in range(totalCount)] retStr = '' for i in range(resultCou
-
使用Python计算玩彩票赢钱概率
工具:Jupyter notebook + Anaconda 游戏规则:时时彩一种玩法是买尾号.2元一个数字,中奖是20元.每个数字出现的概率相等. 目前想到两种买法: 随机购买,人是感性动物,很容易受周围环境干扰.完全随机购买在生活中是不存在的. 分析数字在前面N期出现的概率,选择概率最小的n个数字购买. 导入包 import numpy as np 定义玩法一:完全随机购买 def play_lottery(my_money,play_num,money): ''' 随机选择数的中奖率 re
-
Python分析彩票记录并预测中奖号码过程详解
0 引言 上周被一则新闻震惊到了,<2454万元大奖无人认领!福彩史上第二大弃奖在广东中山产生 >,在2019年5月2日开奖的双色球中,广东中山一位彩民博中2454万元,兑奖时间截至2019年7月1日. 令人遗憾的是,中奖者最终未现身领奖,2454万元大奖成为弃奖.经中山市福彩中心查证,这是中国福彩史上金额第二大的弃奖.根据<彩票管理条例实施细则>的有关规定,这次的2454万元弃奖奖金将被纳入彩票公益金. 一直在为福彩做贡献的我,啥时候能摊上这样的好事啊.于是我用Python生成了
-
python实现彩票系统
本文为大家分享了python实现彩票系统的具体代码,供大家参考,具体内容如下 功能:1.注册 2.登录 3.充钱 4.提现 5.下注 6.开奖 7.退出 简述:彩民需要用身份证号码开户注册一个彩票号码,购买彩票时需要先登录,可以充值以及提现.购买的彩票金额可以自己给定.此系统主要采用面向对象的方法,信息存储方式采用pickle模块来进行存储. 系统主函数: from lotterysystem import lotterySystem import displayview impo
-
python数据分析之公交IC卡刷卡分析
一.背景 交通大数据是由交通运行管理直接产生的数据(包括各类道路交通.公共交通.对外交通的刷卡.线圈.卡口.GPS.视频.图片等数据).交通相关行业和领域导入的数据(气象.环境.人口.规划.移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博.微信.论坛.广播电台等提供的文字.图片.音视频等数据)构成的. 现在给出了一个公交刷卡样例数据集,包含有交易类型.交易时间.交易卡号.刷卡类型.线路号.车辆编号.上车站点.下车站点.驾驶员编号.运营公司编号等.试导入该数据集并做分析. 二
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
Python数据分析之彩票的历史数据
一.需求介绍 该需求主要是分析彩票的历史数据 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5: 对于2.,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10. 然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖
-
深入浅析Python数据分析的过程记录
目录 一.需求介绍 二.以第1.个为例进行数据分析 1.获取一天的数据 2.开始一天的数据的分析 3.循环日期进行多天的数据分析: 4.将数据写入Excel表格中 三.完整的代码展示: 总结 一.需求介绍 该需求主要是分析某一种数据的历史数据. 客户的需求是根据该数据的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票,对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5:对于2.,如果相等的数字是:1-5,那就买1-5,如果
-
Python数据分析之绘制ppi-cpi剪刀差图形
目录 前言 ppi 和 cpi 数据获取 ppi-cpi 图形绘制 总结 前言 ppi-cpi 剪刀差大家可能都听说过,通过这个指标可以了解当前的经济运行状况,小编为了学习 python 的图形绘制,通过爬虫的方式获取到 ppi 和 cpi 的历史数据,然后通过 matplotlib 绘图工具将 ppi 数据和 cpi 数据同框展示,最后通过颜色填充来表示其中的差额部分.对于新手来讲,会学习到 python 的基础知识.爬虫以及图形绘制的知识. ppi 和 cpi 数据获取 既然是数据获取,就需
-
Python数据分析中Groupby用法之通过字典或Series进行分组的实例
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c','d','e'], index=['Joe','Steve','Wes','Jim','Travis'] ) mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'} by_column=people.grou
-
Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法
本文实例讲述了Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法.分享给大家供大家参考,具体如下: 统计两个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator #导入数据 df = pd.read_table('newdata.txt',h
-
Python数据分析之双色球统计单个红和蓝球哪个比例高的方法
本文实例讲述了Python数据分析之双色球统计单个红和蓝球哪个比例高的方法.分享给大家供大家参考,具体如下: 统计单个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator df = pd.read_table('newdata.txt',header=N
-
Python数据分析之获取双色球历史信息的方法示例
本文实例讲述了Python数据分析之获取双色球历史信息的方法.分享给大家供大家参考,具体如下: 每个人都有一颗中双色球大奖的心,对于技术人员来说,通过技术分析,可以增加中奖几率,现使用python语言收集历史双色球中奖信息,之后进行预测分析. 说明:采用2016年5月15日获取的双色球数据为基础进行分析,总抽奖数1940次. 初级代码,有些内容比较繁琐,有更好的代码,大家可以分享. #!/usr/bin/python # -*- coding:UTF-8 -*- #coding:utf-8 #a
-
python数据分析数据标准化及离散化详解
本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0,1]区间.方便数据的处理.消除单位影响及变异大小因素影响. 基本公式为: x'=(x-min)/(max-min) 代码: #!/user/bin/env python #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplo
-
Python数据分析之双色球基于线性回归算法预测下期中奖结果示例
本文实例讲述了Python数据分析之双色球基于线性回归算法预测下期中奖结果.分享给大家供大家参考,具体如下: 前面讲述了关于双色球的各种算法,这里将进行下期双色球号码的预测,想想有些小激动啊. 代码中使用了线性回归算法,这个场景使用这个算法,预测效果一般,各位可以考虑使用其他算法尝试结果. 发现之前有很多代码都是重复的工作,为了让代码看的更优雅,定义了函数,去调用,顿时高大上了 #!/usr/bin/python # -*- coding:UTF-8 -*- #导入需要的包 import pan