关于HashMap 并发时会引起死循环的问题解析
今天研读Java并发容器和框架时,看到为什么要使用ConcurrentHashMap时,其中有一个原因是:线程不安全的HashMap, HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,查找时会陷入死循环。
纠起原因看了其他的博客,都比较抽象,所以这里以图形的方式展示一下,希望支持!
1)当往HashMap中添加元素时,会引起HashMap容器的扩容,原理不再解释,直接附源代码,如下:
/**
*
* 往表中添加元素,如果插入元素之后,表长度不够,便会调用resize方法扩容
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
/**
* resize()方法如下,重要的是transfer方法,把旧表中的元素添加到新表中
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
2)参考上面的代码,便引入到了transfer方法,(引入重点)这就是HashMap并发时,会引起死循环的根本原因所在,下面结合transfer的源代码,说明一下产生死循环的原理,先列transfer代码(这是里JDK7的源偌),如下:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next; ---------------------(1)
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} // while
}
}
3)假设:
Map<Integer> map = new HashMap<Integer>(2); // 只能放置两个元素,其中的threshold为1(表中只填充一个元素时),即插入元素为1时就扩容(由addEntry方法中得知) //放置2个元素 3 和 7,若要再放置元素8(经hash映射后不等于1)时,会引起扩容
假设放置结果图如下:
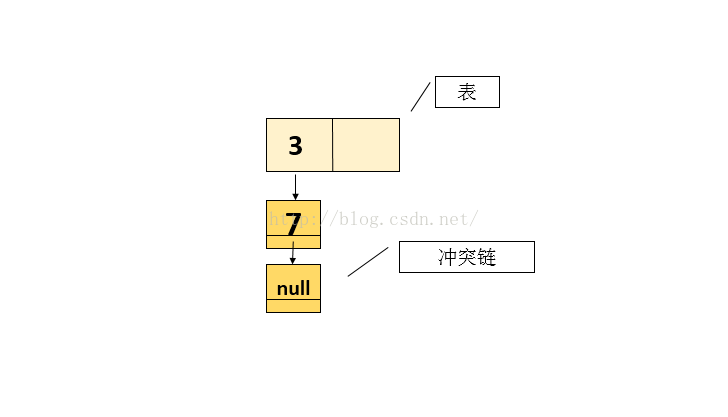
现在有两个线程A和B,都要执行put操作,即向表中添加元素,即线程A和线程B都会看到上面图的状态快照
执行顺序如下:
执行一: 线程A执行到transfer函数中(1)处挂起(transfer函数代码中有标注)。此时在线程A的栈中
e = 3 next = 7
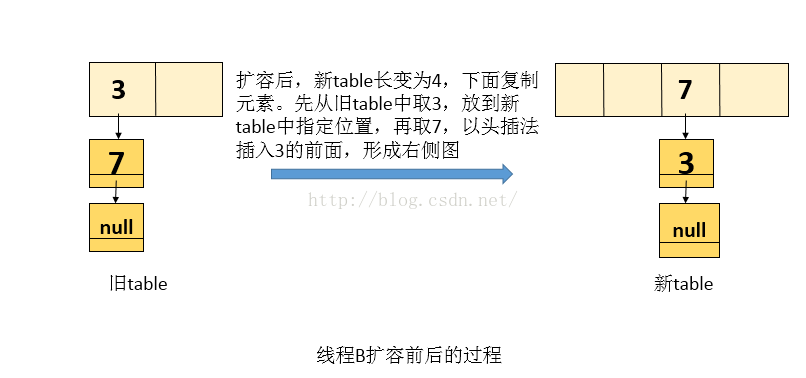
执行二:线程B执行 transfer函数中的while循环,即会把原来的table变成新一table(线程B自己的栈中),再写入到内存中。如下图(假设两个元素在新的hash函数下也会映射到同一个位置)
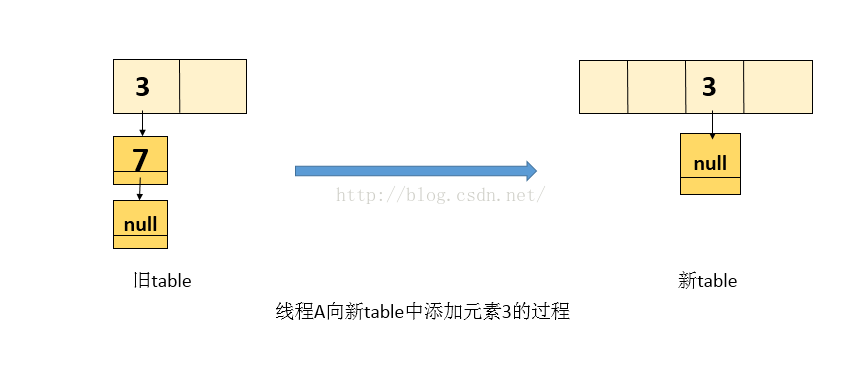
执行三:线程A解挂,接着执行(看到的仍是旧表),即从transfer代码 1)处接着执行,当前的 e = 3, next = 7, 上面已经描述。
1.处理元素 3 , 将 3 放入 线程A自己栈的新table中(新table是处于线程A自己栈中,是线程私有的,不肥线程2的影响),处理3后的图如下:
2.线程A再复制元素 7 ,当前 e = 7 ,而next值由于线程 B 修改了它的引用,所以next 为 3 ,处理后的新表如下图
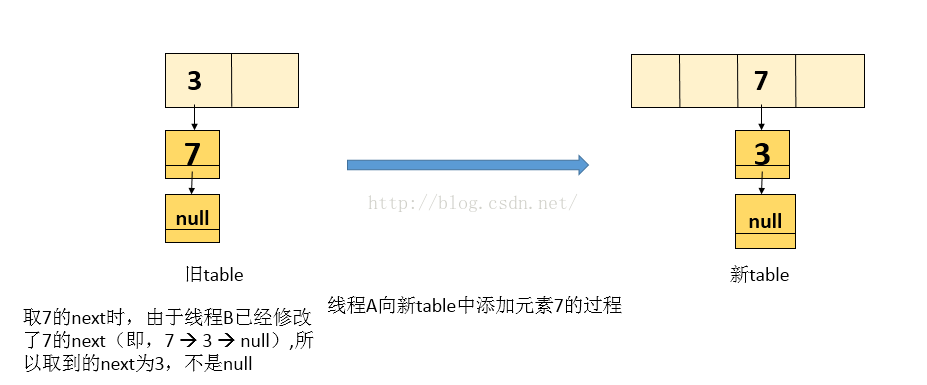
3.由于上面取到的next = 3, 接着while循环,即当前处理的结点为3, next就为null ,退出while循环,执行完while循环后,新表中的内容如下图:
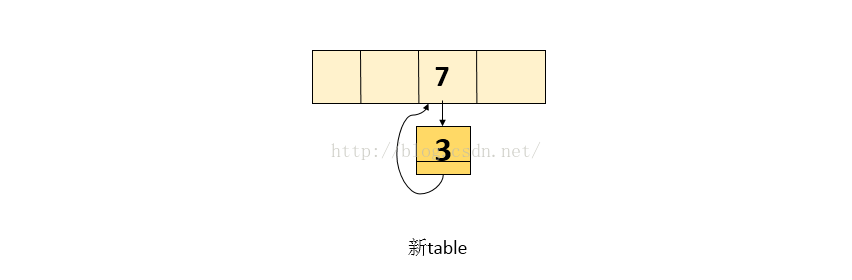
4.当操作完成,执行查找时,会陷入死循环!
原文链接:https://blog.csdn.net/zhuqiuhui/article/details/51849692
版权声明:本文为CSDN博主「bboyzqh」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
以上就是关于HashMap 并发时会引起死循环的问题解析的详细内容,更多关于HashMap 并发死循环的资料请关注我们其它相关文章!
相关推荐
-
JDK1.8中ConcurrentHashMap中computeIfAbsent死循环bug问题
死循环问题的提出:https://bugs.openjdk.java.net/browse/JDK-8062841 map.computeIfAbsent("AaAa",key->map.computeIfAbsent("BBBB",key2->42)); computeIfAbsent在1.8中才有的方法 computeIfAbsent意思是:key不存在时候,调用mappingFunction函数结果作为value值 debug 两个key的hash
-
Java并发系列之ConcurrentHashMap源码分析
我们知道哈希表是一种非常高效的数据结构,设计优良的哈希函数可以使其上的增删改查操作达到O(1)级别.Java为我们提供了一个现成的哈希结构,那就是HashMap类,在前面的文章中我曾经介绍过HashMap类,知道它的所有方法都未进行同步,因此在多线程环境中是不安全的.为此,Java为我们提供了另外一个HashTable类,它对于多线程同步的处理非常简单粗暴,那就是在HashMap的基础上对其所有方法都使用synchronized关键字进行加锁.这种方法虽然简单,但导致了一个问题,那就是在同一时间
-
为什么JDK8中HashMap依然会死循环
JDK8中HashMap依然会死循环! 是否你听说过JDK8之后HashMap已经解决的扩容死循环的问题,虽然HashMap依然说线程不安全,但是不会造成服务器load飙升的问题. 然而事实并非如此.少年可曾了解一种红黑树成环的场景,=v= 今日在查看监控时候发现,某一台机器load飙升 感觉问题不对劲,ssh大法登陆机器,top,top -Hp,jstack,jmap四连击保存下来堆栈,cpu使用最高的线程,内存信息准备分析. 首先查看使用最耗费cpu的线程堆栈信息 cat stack | g
-

最新idea2020注册码永久激活(激活到2100年)
首先有图有真相: 资源链接: 链接: https://pan.baidu.com/s/1mvU2qDxJPCXbCuVaCVCjGA 提取码: k3e2 第一步:将bin目录下的三个文件拷贝到IDEA安装之后的bin目录下,替换文件. 第二步:编辑idea.exe.vmoptions和idea64.exe.vmoptions文件,这两个文件的修改方式完全相同,都是修改文件的最后一行:"-javaagent:".确保"-javaagent:将jar文件的全路径拷贝到这里&quo
-
深入学习java并发包ConcurrentHashMap源码
正文 以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的. JDK1.7的实现 整个 ConcurrentHashMap 由一个个 Segment 组成,Seg
-
IntelliJ IDEA 2020最新激活码(亲测有效,可激活至 2089 年)
一.前言 本文分享IntelliJ IDEA 2020最新激活码,可激活至 2089 年,亲测有效~ 笔者在网上找了一圈,各种方法都试过了,之前那种在网上随便找个注册码,就能激活成功的方式已经一去不返了~ 本文记录下个人 IntelliJ IDEA 2019.3激活破解教程~ 说实话,IDEA 更新是真滴快,还以为 IDEA 2019.2.4 后面会更新 IDEA 2019.2.5 版本,谁知道 11 月份刚结束,官方直接就上了 2019.3 版本 ... 据官方说 IDEA 2019.3 版本
-
基于Java HashMap的死循环的启示详解
一.单线程改造为多线程也是个技术活 正如我们看到耗子叔叔博客里写的那样,原来是单线程的应用程序,"后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU". 考虑到是淘宝的工程师曝出来的问题,他们的技术基础一般都很扎实,连他们都用错了,所以把单线程改造为多线程并不是想象中的那么简单,我认为. 你可能很不服气地反问,淘宝的工程师又怎么了,单线程改为多线程有什么难的?无非就是应用现有的多线程技术嘛,你看,我有非常强烈的线程安全意识,我
-
基于Java并发容器ConcurrentHashMap#put方法解析
jdk1.7.0_79 HashMap可以说是每个Java程序员用的最多的数据结构之一了,无处不见它的身影.关于HashMap,通常也能说出它不是线程安全的.这篇文章要提到的是在多线程并发环境下的HashMap--ConcurrentHashMap,显然它必然是线程安全的,同样我们不可避免的要讨论散列表,以及它是如何实现线程安全的,它的效率又是怎样的,因为对于映射容器还有一个Hashtable也是线程安全的但它似乎只出现在笔试.面试题里,在现实编码中它已经基本被遗弃. 关于HashMap的线程不
-
关于HashMap 并发时会引起死循环的问题解析
今天研读Java并发容器和框架时,看到为什么要使用ConcurrentHashMap时,其中有一个原因是:线程不安全的HashMap, HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,查找时会陷入死循环. 纠起原因看了其他的博客,都比较抽象,所以这里以图形的方式展示一下,希望支持! 1)当往HashMap中添加元素时,会引起HashMap容器的扩容,原理不再解释,直接附源代码,如下: /** * * 往表中添加元素,如果插入元素
-
Java中的HashMap为什么会产生死循环
目录 前置知识 死循环执行步骤1 死循环执行步骤2 死循环执行步骤3 解决方案 总结 前言: HashMap 死循环是一个比较常见.比较经典的问题,在日常的面试中出现的频率比较高,所以接下来咱们通过图解的方式,带大家彻底理解死循环的原因. 前置知识 死循环问题发生在 JDK 1.7 版本中,造成这个问题主要是由于 HashMap 自身的运行机制,加上并发操作,从而导致了死循环. 在 JDK 1.7 中 HashMap 的底层数据实现是数组 + 链表的方式, 如下图所示: 而 HashMap
-
Java并发编程之CountDownLatch源码解析
一.前言 CountDownLatch维护了一个计数器(还是是state字段),调用countDown方法会将计数器减1,调用await方法会阻塞线程直到计数器变为0.可以用于实现一个线程等待所有子线程任务完成之后再继续执行的逻辑,也可以实现类似简易CyclicBarrier的功能,达到让多个线程等待同时开始执行某一段逻辑目的. 二.使用 一个线程等待其它线程执行完再继续执行 ...... CountDownLatch cdl = new CountDownLatch(10); Executor
-
Java并发编程:volatile关键字详细解析
volatile这个关键字可能很多朋友都听说过,或许也都用过.在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果.在Java 5之后,volatile关键字才得以重获生机. volatile关键字虽然从字面上理解起来比较简单,但是要用好不是一件容易的事情.由于volatile关键字是与Java的内存模型有关的,因此在讲述volatile关键之前,我们先来了解一下与内存模型相关的概念和知识,然后分析了volatile关键字的实现原理,最后给出了几个使用vola
-
python并发编程多进程 互斥锁原理解析
运行多进程 每个子进程的内存空间是互相隔离的 进程之间数据不能共享的 互斥锁 但是进程之间都是运行在一个操作系统上,进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端, 是可以的,而共享带来的是竞争,竞争带来的结果就是错乱 #并发运行,效率高,但竞争同一打印终端,带来了打印错乱 from multiprocessing import Process import time def task(name): print("%s 1" % name) time.
-
python并发爬虫实用工具tomorrow实用解析
tomorrow是我最近在用的一个爬虫利器,该模块属于第三方的一个模块,使用起来非常的方便,只需要用其中的threads方法作为装饰器去修饰一个普通的函数,既可以达到并发的效果,本篇将用实例来展示tomorrow的强大之处.后面将对tomorrow的实现原理做进一步的分析. 1.安装第三方包 pip install requests_html #网络请求包 pip install fake-useragent #获取useragent包 pip install tomorrow 2.普通下载方式
-
Java并发 synchronized锁住的内容解析
synchronized用在方法上锁住的是什么? 锁住的是当前对象的当前方法,会使得其他线程访问该对象的synchronized方法或者代码块阻塞,但并不会阻塞非synchronized方法. 脏读 一个常见的概念.在多线程中,难免会出现在多个线程中对同一个对象的实例变量或者全局静态变量进行并发访问的情况,如果不做正确的同步处理,那么产生的后果就是"脏读",也就是取到的数据其实是被更改过的.注意这里 局部变量是不存在脏读的情况 public class ThreadDomain13 {
-
Java并发工具类LongAdder原理实例解析
LongAdder实现原理图 高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性.既然AtomicLong性能问题是由于过多线程同时去竞争同一个变量的更新而降低的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源. LongAdder则是内部维护一个Cells数组,每个Cell里面有一个初始值为0的long型变量,在同等并发量的情况下,争夺单个变量的线程会减少,这是变相的减少了争夺共享资源的并发量,另外多个线程在争夺同
-
python 并发编程 阻塞IO模型原理解析
阻塞IO(blocking IO) 在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样: 当用户进程调用了recvfrom这个系统调用,kernel内核就开始了IO的第一个阶段:准备数据.对于network io( 网络io )来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel( 内核 )就要等待足够的数据到来. 等着对方把数据放到自己操作系统内存 而在用户进程这边,整个进程会被阻塞.当kernel一直等
-
Java京东面试题之为什么HashMap线程不安全
目录 01.多线程下扩容会死循环 02.多线程下 put 会导致元素丢失 03.put 和 get 并发时会导致 get 到 null 01.多线程下扩容会死循环 众所周知,HashMap 是通过拉链法来解决哈希冲突的,也就是当哈希冲突时,会将相同哈希值的键值对通过链表的形式存放起来. JDK 7 时,采用的是头部插入的方式来存放链表的,也就是下一个冲突的键值对会放在上一个键值对的前面(同一位置上的新元素被放在链表的头部).扩容的时候就有可能导致出现环形链表,造成死循环. resize 方法的源