python读取一个大于10G的txt文件的方法
前言
用python 读取一个大于10G 的文件,自己电脑只有8G内存,一运行就报内存溢出:MemoryError
python 如何用open函数读取大文件呢?
读取大文件
首先可以自己先制作一个大于10G的txt文件
a = '''
2021-02-02 21:33:31,678 [django.request:93] [base:get_response] [WARNING]- Not Found: /http:/123.125.114.144/
2021-02-02 21:33:31,679 [django.server:124] [basehttp:log_message] [WARNING]- "HEAD http://123.125.114.144/ HTTP/1.1" 404 1678
2021-02-02 22:14:04,121 [django.server:124] [basehttp:log_message] [INFO]- code 400, message Bad request version ('HTTP')
2021-02-02 22:14:04,122 [django.server:124] [basehttp:log_message] [WARNING]- "GET ../../mnt/custom/ProductDefinition HTTP" 400 -
2021-02-02 22:16:21,052 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/login HTTP/1.1" 301 0
2021-02-02 22:16:21,123 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/login/ HTTP/1.1" 200 3876
2021-02-02 22:16:21,192 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/img/main_bg.png HTTP/1.1" 200 2801
2021-02-02 22:16:21,196 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/iconfont/style.css HTTP/1.1" 200 1638
2021-02-02 22:16:21,229 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/img/bg.jpg HTTP/1.1" 200 135990
2021-02-02 22:16:21,307 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/iconfont/fonts/icomoon.ttf?u4m6fy HTTP/1.1" 200 6900
2021-02-02 22:16:23,525 [django.server:124] [basehttp:log_message] [INFO]- "POST /api/login/ HTTP/1.1" 302 0
2021-02-02 22:16:23,618 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/index/ HTTP/1.1" 200 18447
2021-02-02 22:16:23,709 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/js/commons.js HTTP/1.1" 200 13209
2021-02-02 22:16:23,712 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/css/admin.css HTTP/1.1" 200 19660
2021-02-02 22:16:23,712 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/css/common.css HTTP/1.1" 200 1004
2021-02-02 22:16:23,714 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/js/app.js HTTP/1.1" 200 20844
2021-02-02 22:16:26,509 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/report_list/1/ HTTP/1.1" 200 14649
2021-02-02 22:16:51,496 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/test_list/1/ HTTP/1.1" 200 24874
2021-02-02 22:16:51,721 [django.server:124] [basehttp:log_message] [INFO]- "POST /api/add_case/ HTTP/1.1" 200 0
2021-02-02 22:16:59,707 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/test_list/1/ HTTP/1.1" 200 24874
2021-02-03 22:16:59,909 [django.server:124] [basehttp:log_message] [INFO]- "POST /api/add_case/ HTTP/1.1" 200 0
2021-02-03 22:17:01,306 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/edit_case/1/ HTTP/1.1" 200 36504
2021-02-03 22:17:06,265 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/add_project/ HTTP/1.1" 200 17737
2021-02-03 22:17:07,825 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/project_list/1/ HTTP/1.1" 200 29789
2021-02-03 22:17:13,116 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/add_config/ HTTP/1.1" 200 24816
2021-02-03 22:17:19,671 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/config_list/1/ HTTP/1.1" 200 19532
'''
while True:
with open("xxx.log", "a", encoding="utf-8") as fp:
fp.write(a)
循环写入到 xxx.log 文件,运行 3-5 分钟,pycharm 打开查看文件大小大于 10G
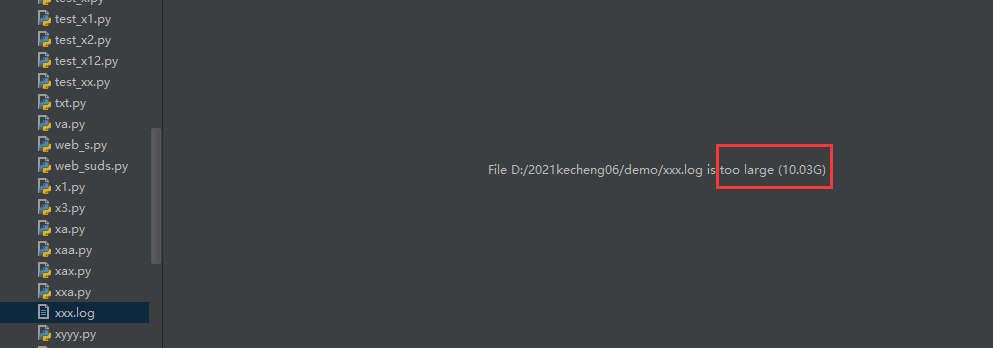
于是我用open函数 直接读取
f = open("xxx.log", 'r')
print(f.read())
f.close()
抛出内存溢出异常:MemoryError
Traceback (most recent call last):
File "D:/2021kecheng06/demo/txt.py", line 35, in <module>
print(f.read())
MemoryError
运行的时候可以看下自己电脑的内存已经占了100%, cpu高达91% ,不挂掉才怪了!
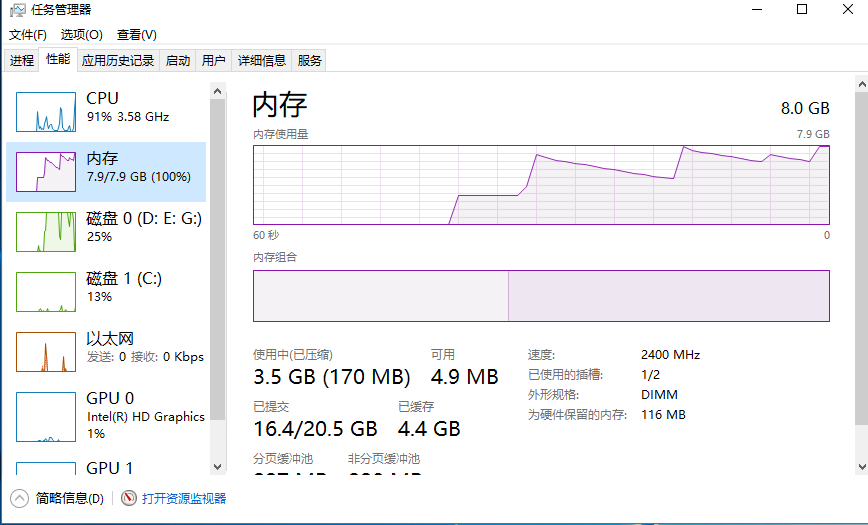
这种错误的原因在于,read()方法执行操作是一次性的都读入内存中,显然文件大于内存就会报错。
read() 的几种方法
1.read() 方法可以带参数 n, n 是每次读取的大小长度,也就是可以每次读一部分,这样就不会导致内存溢出
f = open("xxx.log", 'r')
print(f.read(2048))
f.close()
运行结果
2019-10-24 21:33:31,678 [django.request:93] [base:get_response] [WARNING]- Not Found: /http:/123.125.114.144/
2019-10-24 21:33:31,679 [django.server:124] [basehttp:log_message] [WARNING]- "HEAD http://123.125.114.144/ HTTP/1.1" 404 1678
2019-10-24 22:14:04,121 [django.server:124] [basehttp:log_message] [INFO]- code 400, message Bad request version ('HTTP')
2019-10-24 22:14:04,122 [django.server:124] [basehttp:log_message] [WARNING]- "GET ../../mnt/custom/ProductDefinition HTTP" 400 -
2019-10-24 22:16:21,052 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/login HTTP/1.1" 301 0
2019-10-24 22:16:21,123 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/login/ HTTP/1.1" 200 3876
2019-10-24 22:16:21,192 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/img/main_bg.png HTTP/1.1" 200 2801
2019-10-24 22:16:21,196 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/iconfont/style.css HTTP/1.1" 200 1638
2019-10-24 22:16:21,229 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/img/bg.jpg HTTP/1.1" 200 135990
2019-10-24 22:16:21,307 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/iconfont/fonts/icomoon.ttf?u4m6fy HTTP/1.1" 200 6900
2019-10-24 22:16:23,525 [django.server:124] [basehttp:log_message] [INFO]- "POST /api/login/ HTTP/1.1" 302 0
2019-10-24 22:16:23,618 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/index/ HTTP/1.1" 200 18447
2019-10-24 22:16:23,709 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/js/commons.js HTTP/1.1" 200 13209
2019-10-24 22:16:23,712 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/css/admin.css HTTP/1.1" 200 19660
2019-10-24 22:16:23,712 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/css/common.css HTTP/1.1" 200 1004
2019-10-24 22:16:23,714 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/js/app.js HTTP/1.1" 200 20844
2019-10-24 22:16:26,509 [django.server:124] [basehttp:log_message] [I
这样就只读取了2048个字符,全部读取的话,循环读就行
f = open("xxx.log", 'r')
while True:
block = f.read(2048)
print(block)
if not block:
break
f.close()
2.readline():每次读取一行,这个方法也不会报错
f = open("xxx.log", 'r')
while True:
line = f.readline()
print(line, end="")
if not line:
break
f.close()
3.readlines():读取全部的行,生成一个list,通过list来对文件进行处理,显然这种方式依然会造成:MemoyError
真正 Pythonic 的方法
真正 Pythonci 的方法,使用 with 结构打开文件,fp 是一个可迭代对象,可以用 for 遍历读取每行的文件内容
with open("xxx.log", 'r') as fp:
for line in fp:
print(line, end="")
yield 生成器读取大文件
前面一篇讲yield 生成器的时候提到读取大文件,函数返回一个可迭代对象,用next()方法读取文件内容
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
if __name__ == '__main__':
a = read_file("xxx.log")
print(a) # generator objec
print(next(a)) # bytes类型
print(next(a).decode("utf-8")) # str
运行结果
<generator object read_file at 0x00000226B3005258>
b'\r\n2019-10-24 21:33:31,678 [django.request:93] [base:get_response] [WARNING]- Not Found: /http:/123.125.114.144/\r\n2019-10-24 21:33:31,679 [django.server:124] [basehttp:log_message] [WARNING]- "HEAD http://123.125.114.144/ HTTP/1.1" 404 1678\r\n2019-10-24 22:14:04,121 [django.server:124] [basehttp:log_message] [INFO]- code 400, message Bad request version (\'HTTP\')\r\n2019-10-24 22:14:04,122 [django.server:124] [basehttp:log_message] [WARNING]- "GET ../../mnt/custom/ProductDefinition HTTP" 400 -\r\n2019-10-24 22:16:21,052 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/login HTTP/1.1" 301 0\r\n2019-10-24 22:16:21,123 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/login/ HTTP/1.1" 200 3876\r\n2019-10-24 22:16:21,192 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/img/main_bg.png HTTP/1.1" 200 2801\r\n2019-10-24 22:16:21,196 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/iconfont/style.css HTTP/1.1" 200 1638\r\n2019-10-24 22:16:21,229 [django.server:124] '
[basehttp:log_message] [INFO]- "GET /static/assets/img/bg.jpg HTTP/1.1" 200 135990
2019-10-24 22:16:21,307 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/iconfont/fonts/icomoon.ttf?u4m6fy HTTP/1.1" 200 6900
2019-10-24 22:16:23,525 [django.server:124] [basehttp:log_message] [INFO]- "POST /api/login/ HTTP/1.1" 302 0
2019-10-24 22:16:23,618 [django.server:124] [basehttp:log_message] [INFO]- "GET /api/index/ HTTP/1.1" 200 18447
2019-10-24 22:16:23,709 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/js/commons.js HTTP/1.1" 200 13209
2019-10-24 22:16:23,712 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/css/admin.css HTTP/1.1" 200 19660
2019-10-24 22:16:23,712 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/css/common.css HTTP/1.1" 200 1004
2019-10-24 22:16:23,714 [django.server:124] [basehttp:log_message] [INFO]- "GET /static/assets/js/app.js HTTP/1.1" 200 20844
2019-10-24 22:16:26,509 [django.server:124] [basehtt
到此这篇关于python读取一个大于10G的txt文件的方法的文章就介绍到这了,更多相关python读取大于10G文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
使用Python读取大文件的方法
背景 最近处理文本文档时(文件约2GB大小),出现memoryError错误和文件读取太慢的问题,后来找到了两种比较快Large File Reading 的方法,本文将介绍这两种读取方法. 准备工作 我们谈到"文本处理"时,我们通常是指处理的内容.Python 将文本文件的内容读入可以操作的字符串变量非常容易.文件对象提供了三个"读"方法: .read()..readline() 和 .readlines().每种方法可以接受一个变量以限制每次读取的数据量,但它们
-
强悍的Python读取大文件的解决方案
Python 环境下文件的读取问题,请参见拙文 Python基础之文件读取的讲解 这是一道著名的 Python 面试题,考察的问题是,Python 读取大文件和一般规模的文件时的区别,也即哪些接口不适合读取大文件. 1. read() 接口的问题 f = open(filename, 'rb') f.read() 我们来读取 1 个 nginx 的日至文件,规模为 3Gb 大小.read() 方法执行的操作,是一次性全部读入内存,显然会造成: MemoryError ... 也即会发生内存溢出.
-
简单了解Python读取大文件代码实例
这篇文章主要介绍了简单了解Python读取大文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 通常对于大文件读取及处理,不可能直接加载到内存中,因此进行分批次小量读取及处理 I.第一种读取方式 一行一行的读取,速度较慢 def read_line(path): with open(path, 'r', encoding='utf-8') as fout: line = fout.readline() while line: line
-
Python多进程分块读取超大文件的方法
本文实例讲述了Python多进程分块读取超大文件的方法.分享给大家供大家参考,具体如下: 读取超大的文本文件,使用多进程分块读取,将每一块单独输出成文件 # -*- coding: GBK -*- import urlparse import datetime import os from multiprocessing import Process,Queue,Array,RLock """ 多进程分块读取文件 """ WORKERS = 4
-

解决python 读取npy文件太大不能完全显示的问题
python读取npy文件时,太大不能完全显示,其解决方法 当用python读取npy文件时,会遇到npy文件太大,用print函数打印时不能完全显示,如以下情况: 解决办法 添加一行代码:np.set_printoptions(threshold = 1e6),其中threshold表示输出数组的元素数目 其结果如下: 补充:PyCharm打开大文件时提示文件过大,只显示前一小部分 使用pycharm打开一些大文件时,会出现上述提示,表明文件过大,只能以只读的方式显示前一小部分内容,这种情况显
-
python简单读取大文件的方法
本文实例讲述了python简单读取大文件的方法.分享给大家供大家参考,具体如下: Python读取大文件(GB级别)采用的办法很简单: with open(...) as f: for line in f: <do something with line> 例如: with open(filepath,'r') as infile: for line in infile: print line 一切都交给python解释器处理,读取效率很高,且占用资源少. stackoverflow参考链接:
-
python实现读取大文件并逐行写入另外一个文件
<pre name="code" class="python">creazy.txt文件有4G,逐行读取其内容并写入monday.txt文件里. def creazyRead(): ''''' with open("e:creazy.txt","r") as cr: for line in cr: print line ''' ms = open("e:creazy.txt") for line
-
python读取一个大于10G的txt文件的方法
前言 用python 读取一个大于10G 的文件,自己电脑只有8G内存,一运行就报内存溢出:MemoryError python 如何用open函数读取大文件呢? 读取大文件 首先可以自己先制作一个大于10G的txt文件 a = ''' 2021-02-02 21:33:31,678 [django.request:93] [base:get_response] [WARNING]- Not Found: /http:/123.125.114.144/ 2021-02-02 21:33:31,6
-
python读取一个目录下所有txt里面的内容方法
实例如下所示: import os allFileNum = 0 def printPath(level, path): global allFileNum ''''' 打印一个目录下的所有文件夹和文件 ''' # 所有文件夹,第一个字段是次目录的级别 dirList = [] # 所有文件 fileList = [] # 返回一个列表,其中包含在目录条目的名称 files = os.listdir(path) # 先添加目录级别 dirList.append(str(level)) for f
-
Python之读取TXT文件的方法小结
方法一: <span style="font-size:14px;">#read txt method one f = open("./image/abc.txt") line = f.readline() while line: print line line = f.readline() f.close() </span> 方法二: #read txt method two f = open("./image/abc.txt&q
-
Python读取一个目录下所有目录和文件的方法
本文实例讲述了Python读取一个目录下所有目录和文件的方法.分享给大家供大家参考,具体如下: 这里介绍的是刚学python时的一个读取目录的列子,给大家分享下: #!/usr/bin/python # -*- coding:utf8 -*- import os allFileNum = 0 def printPath(level, path): global allFileNum ''' 打印一个目录下的所有文件夹和文件 ''' # 所有文件夹,第一个字段是次目录的级别 dirList = [
-
Python实现将目录中TXT合并成一个大TXT文件的方法
本文实例讲述了Python实现将目录中TXT合并成一个大TXT文件的方法.分享给大家供大家参考.具体如下: 在网上下了一个dota的英雄攻略,TXT格式,每个英雄一个文件,看得疼,就写了一个小东西,合并一下. #coding=gbk import os import sys import glob def dirTxtToLargeTxt(dir,outputFileName): '''从dir目录下读入所有的TXT文件,将它们写到outputFileName里去''' #如果dir不是目录返回
-
python将pandas datarame保存为txt文件的实例
CSV means Comma Separated Values. It is plain text (ansi). The CSV ("Comma Separated Value") file format is often used to exchange data between disparate applications. The file format, as it is used in Microsoft Excel, has become a pseudo standa
-
Python 读取某个目录下所有的文件实例
在处理数据的时候,因为没有及时的去重,所以需要重新对生成txt进行去重. 可是一个文件夹下有很多txt,总不可能一个一个去操作,这样效率太低了.这里我们需要用到 os 这个包 关键的代码 <span style="font-size:14px;"># coding=utf-8 #出现了中文乱码的问题,于是我无脑utf-8 .希望后期的学习可以能理解 import os import os.path import re import sys import codecs rel
-
Python读取指定目录下指定后缀文件并保存为docx
最近有个奇葩要求 要项目中的N行代码 申请专利啥的 然后作为程序员当然不能复制粘贴 用代码解决.. 使用python-docx读写docx文件 环境使用python3.6.0 首先pip安装python-docx pip install python-docx 然后下面是脚本 修改目录,这里默认取脚本运行目录下的src文件夹 取.cs后缀的所有文件 读取并保存为docx 有一点需要注意,如果文件中有中文,请用vscode或者其他编辑器使用utf-8格式打开,看看有没有乱码 其中每处理一个文件都会
-
Java实现读取键盘输入保存到txt文件,再统计并输出每个单词出现次数的方法
本文实例讲述了Java实现读取键盘输入保存到txt文件,再统计并输出每个单词出现次数的方法.分享给大家供大家参考,具体如下: package javatest; import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.FileReader; import java.io.IOEx
-
Python实现合并同一个文件夹下所有txt文件的方法示例
本文实例讲述了Python实现合并同一个文件夹下所有txt文件的方法.分享给大家供大家参考,具体如下: 一.需求分析 合并一个文件夹下所有txt文件 二.合并效果 三.python实现代码 # -*- coding:utf-8*- import sys reload(sys) sys.setdefaultencoding('utf-8') import os import os.path import time time1=time.time() ########################