Python lxml库的简单介绍及基本使用讲解
1.lxml库介绍
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息
HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观
XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容
2.安装lxml方法
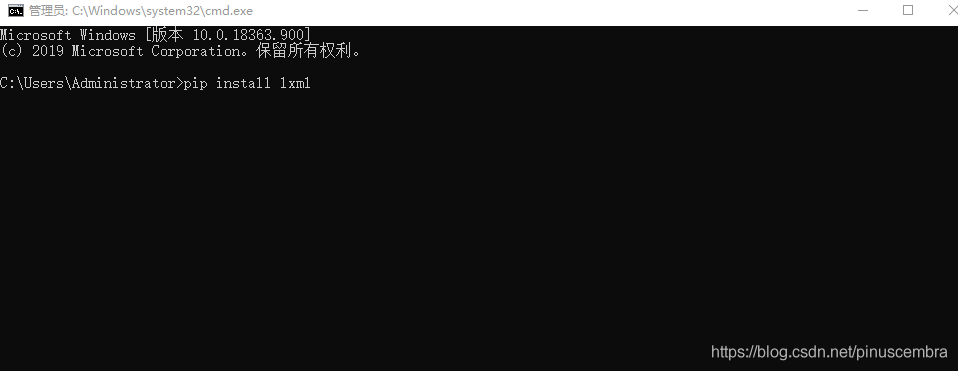
方法1:
在cmd运行窗口中输入:pip install lxml
方法2:
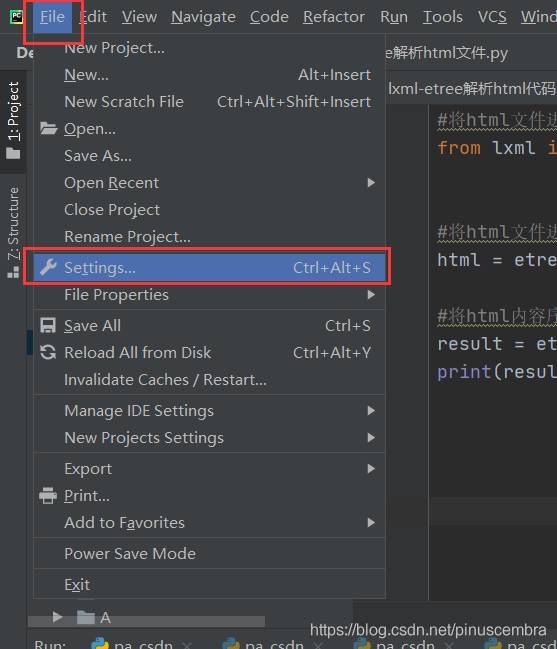
在Pycharm中下载
File–Setting–Project–Project Interpreter–点击右上角的“+”—
第1步
第2步
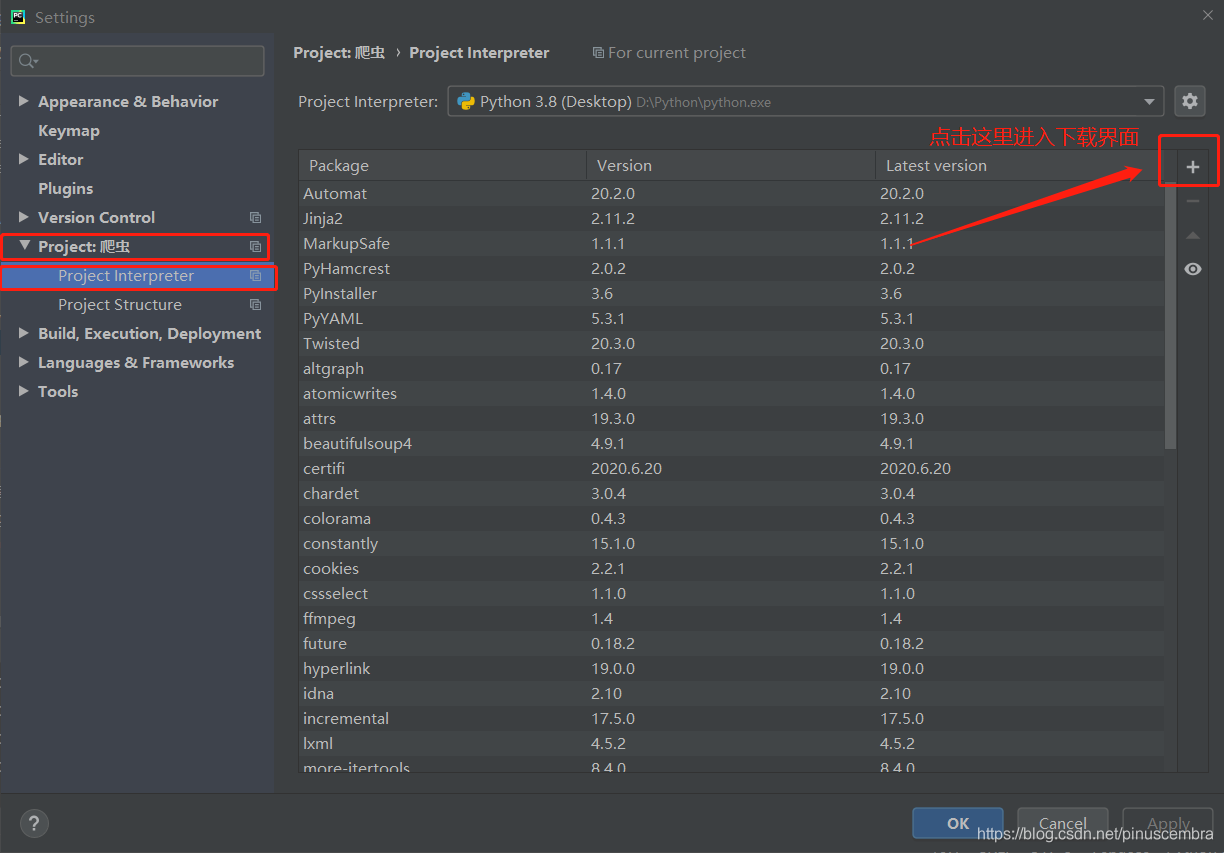
第3步

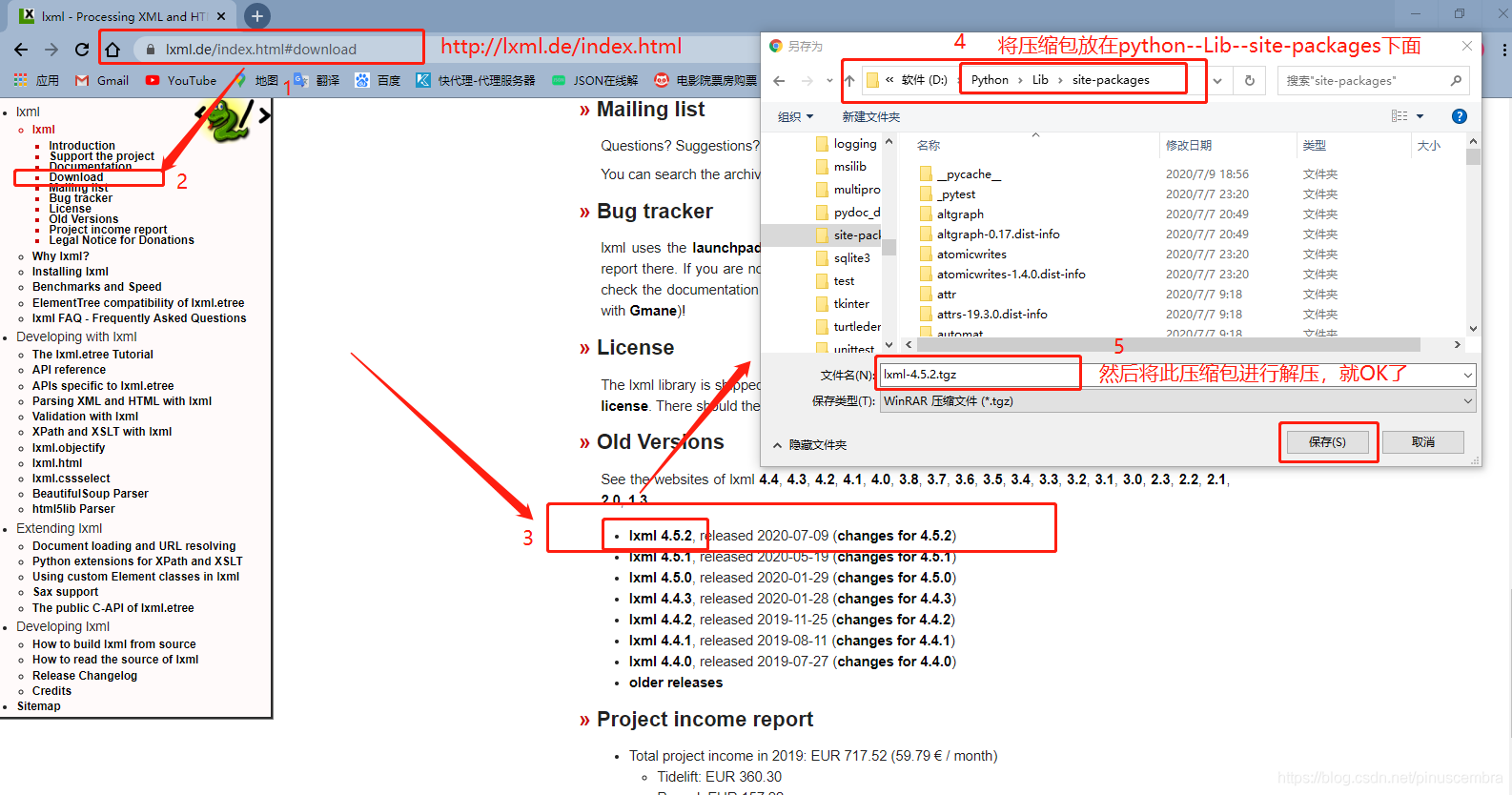
方法3:
进入这个网站进行下载:https://lxml.de/index.html
3.基本使用
我们可以利用他解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范或者不完整,lxml解析器会自动修复或补全代码,从而提高效率
实例1:
解析HTML代码块
#提取html中的数据
from lxml import etree
text = '''
<html>
<div class="clearfix">
<div class="nav_com">
<ul>
<li class="active"><a href="/" rel="external nofollow" >推荐</a></li>
<li class=""><a href="/nav/python" rel="external nofollow" >Python</a></li>
<li class=""><a href="/nav/java" rel="external nofollow" >Java</a></li>
<li class=""><a href="/nav/web" rel="external nofollow" >前端</a></li>
<li class=""><a href="/nav/arch" rel="external nofollow" >架构</a></li>
<li class=""><a href="/nav/db" rel="external nofollow" >数据库</a></li>
<li class=""><a href="/nav/5g" rel="external nofollow" >5G</a></li>
<li class=""><a href="/nav/game" rel="external nofollow" >游戏开发</a></li>
<li class=""><a href="/nav/mobile" rel="external nofollow" >移动开发</a></li>
<li class=""><a href="/nav/ops" rel="external nofollow" >运维</a></li>
</ul>
</div>
</div>
</html>>
</html>>
'''
#将字符串解析为html文档
html = etree.HTML(text)
#print(html)
#将字符串序列化为html
result = etree.tostring(html).decode('utf-8')
print(result)
实例2:
读取并解析html文件
#将html文件进行解析
from lxml import etree
#将html文件进行读取
html = etree.parse('data.html')
#将html内容序列化
result = etree.tostring(html).decode('utf-8')
print(result)
到此这篇关于Python lxml库的简单介绍及基本使用讲解的文章就介绍到这了,更多相关Python lxml库使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫新手入门之初学lxml库
1.爬虫是什么 所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本.万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息. 2.爬虫三要素 抓取 分析 存储 3.爬虫的过程分析 当人类去访问一个网页时,是如何进行的? ①打开浏览器,输入要访问的网址,发起请求. ②等待服务器返回数据,通过浏览器加载网页. ③从网页中找到自己需要的数据(文本.图片.文件等等). ④保存自己需要的数据. 对于爬虫,也是类似的.它模仿人类请求网页的过程,但是又稍有不同.
-
Python大数据之使用lxml库解析html网页文件示例
本文实例讲述了Python大数据之使用lxml库解析html网页文件.分享给大家供大家参考,具体如下: lxml是Python的一个html/xml解析并建立dom的库,lxml的特点是功能强大,性能也不错,xml包含了ElementTree ,html5lib ,beautfulsoup 等库. 使用lxml前注意事项:先确保html经过了utf-8解码,即code =html.decode('utf-8', 'ignore'),否则会出现解析出错情况.因为中文被编码成utf-8之后变成 '/
-
Python爬虫基础之XPath语法与lxml库的用法详解
前言 本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法 XPath 即为 XML 路径语言,它是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言. XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力. XPath 同样也支持HTML. XPath 是一门小型的查询语言. python 中 lxml库 使用的是 Xpath 语法,是
-
Python lxml库的简单介绍及基本使用讲解
1.lxml库介绍 lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据:lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML.XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息 HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观 XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容 2.安装lxml方法 方法1: 在cmd运行窗口中输入:pip install lxml 方法2: 在Pychar
-
Python爬虫库BeautifulSoup的介绍与简单使用实例
一.介绍 BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器.利用它不用编写正则表达式即可方便地实现网页信息的提取. Python常用解析库 解析器 使用方法 优势 劣势 Python标准库 BeautifulSoup(markup, "html.parser") Python的内置标准库.执行速度适中 .文档容错能力强 Python 2.7.3 or 3.2.2)前的版本中文容错能力差 lxml HTML 解析器 BeautifulSoup(markup,
-
python sklearn库实现简单逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Reduction).分类(Classfication).聚类(Clustering)等方法.当我们面临机器学习问题时,便可根据下图来选择相应的方法. Sklearn具有以下特点: 简单高效的数据挖掘和数据分析工具 让每个人能够在复杂环境中重复使用 建立NumPy.Scipy.MatPlotLib之上 代
-
python 高阶函数简单介绍
把函数作为参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现.函数式编程就是指这种高度抽象的编程范式. 1.体验高阶函数 在Python中,abs()函数可以完成对数字求绝对值计算. abs(-10) # 10 round()函数可以完成对数字的四舍五入计算. round(1.2) # 1 round(1.9) # 2 需求:任意两个数字,按照指定要求整理数字后再进行求和计算. 方法1 def add_num(a, b): return abs(a) + abs(b) result =
-
python EasyOCR库实例用法介绍
说明 1.EasyOCR是一个用python编写的OCR三方库.可以在python中调用,用来识别图像中的文字,并输出为文本. 2.支持80多种语言的识别,识别精度高,甚至要超过PaddleOCR. 安装命令 pip install easyocr 代码实现 import easyocr #设置识别中英文两种语言 reader = easyocr.Reader(['ch_sim','en'], gpu = False) # need to run only once to load model
-
Python运算符的使用简单介绍
目录 1.算术运算符 2.赋值运算符 3.比较运算符 4.逻辑运算符 5.位运算符 6.运算符优先级和结合性 1.算术运算符 Python 中常用运算符: 运算符 说明 实例 结果 + 加 22.4 + 15 37.4 - 减 4.56 - 0.56 4 * 乘 5 * 3 15 / 除法(和数学中的规则一样) 8 / 2 4 // 整除(只保留商的整数部分) 7 // 2 3 % 取模,即返回除法的余数 7 % 2 1 ** 次方运算,即返回 x 的 y 次方 2 ** 4 16,即 2^4
-
Python 网络爬虫--关于简单的模拟登录实例讲解
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号.密码等等. 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存) 2.将信息进行提交 3.获取登录后的信息 先给上源码 <span style="font-size: 14px;"># -*- coding: utf-8 -*- import requests def login(): sessi
-
python爬虫库scrapy简单使用实例详解
最近因为项目需求,需要写个爬虫爬取一些题库.在这之前爬虫我都是用node或者php写的.一直听说python写爬虫有一手,便入手了python的爬虫框架scrapy. 下面简单的介绍一下scrapy的目录结构与使用: 首先我们得安装scrapy框架 pip install scrapy 接着使用scrapy命令创建一个爬虫项目: scrapy startproject questions 相关文件简介: scrapy.cfg: 项目的配置文件 questions/: 该项目的python模块.之
-
python密码学库pynacl功能介绍
目录 python库-密码学库pynacl 什么是pynacl 数字签名使用example python库-密码学库pynacl 什么是pynacl 官方: https://pynacl.readthedocs.io/en/latest/ PyNaCl is a Python binding to libsodium, which is a fork of the Networking and Cryptography library. These libraries have a stated
-
使用python PIL库实现简单验证码的去噪方法步骤
字符型图片验证码识别完整过程及Python实现的博主,我的大部分知识点都是从他那里学来的. 想要识别验证码,收集足够多的样本后,首先要做的就是对验证码原始图片进行处理,对验证码识别分类之前,一般包括:将彩色图片转换成灰度图.将灰度图二值化和去除噪点三个基本过程.这里仅以比较简单的验证码为例,介绍一下如何通过python的PIL库对图片去噪. 首先看一下未经处理的验证码图片: 对图片处理主要使用了PIL库的Image类. 1.彩色图片转换成灰度图 首先使用Image的open方法打开上面的图片,可