Python实现线性判别分析(LDA)的MATLAB方式
线性判别分析(linear discriminant analysis),LDA。也称为Fisher线性判别(FLD)是模式识别的经典算法。
(1)中心思想:将高维的样本投影到最佳鉴别矢量空间,来达到抽取分类信息和压缩特种空间维数的效果,投影后保证样本在新的子空间有最大的类间距离和最小的类内距离。也就是说在该空间中有最佳的可分离性。
(2)与PCA的不同点:PCA主要是从特征的协方差出发,来找到比较好的投影方式,最后需要保留的特征维数可以自己选择。但是LDA更多的是考虑了类别信息,即希望投影后不同类别之间数据点的距离更大,同一类别的数据点更紧凑。
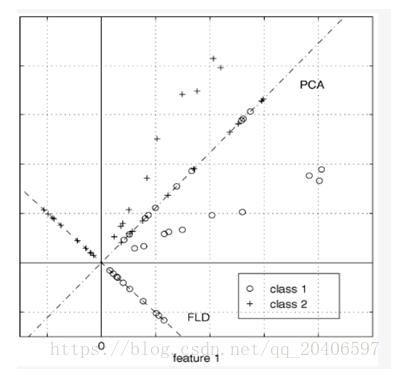
从图中也可以看出,LDA的投影后就已经将不同的类别分开了。
所以说,LDA是以分类为基准的,考虑的是如何选择投影方向使得分类更好,是有监督的。但是PCA是一种无监督的降维方式,它只是单纯的降维,只考虑如何选择投影面才能使得降维以后的样本信息保留的最大。
(3)LDA的维度:LDA降维后是与类别个数直接相关的,而与数据本身的维度没有关系。如果有C个类别,LDA降维后一般会选择1-C-1维。对于很多二分类问题,LDA之后就剩下一维,然后再找到一个分类效果最好的阈值就可以进行分类了。
(4)投影的坐标系是否正交:
PCA的投影坐标系都是正交的,而LDA是根据类别的标注,主要关注的是分类能力,因此可以不去关注石否正交,而且一般都不正交。
(5)LDA步骤:
(a)计算各个类的样本均值:

这个地方需要注意的是,分别求出每个类别样本的Sbi或者Swi后,在计算总体的Sb和Sw时需要做加权平均,因为每个类别中的样本数目可能是不一样的。
(d)LDA作为一个分类的算法,我们希望类内的聚合度高,即类内散度矩阵小,而类间散度矩阵大。这样的分类效果才好。因此引入Fisher鉴别准则表达式:

(inv(Sw)Sb)的特征向量。且最优投影轴的个数d<=C-1;
(e)所以,只要计算出矩阵inv(Sw)Sb的最大特征值对应的特征向量,该特征向量就是投影方向W。
(6)计算各点在投影后的方向上的投影点:

MATLAB实现代码:
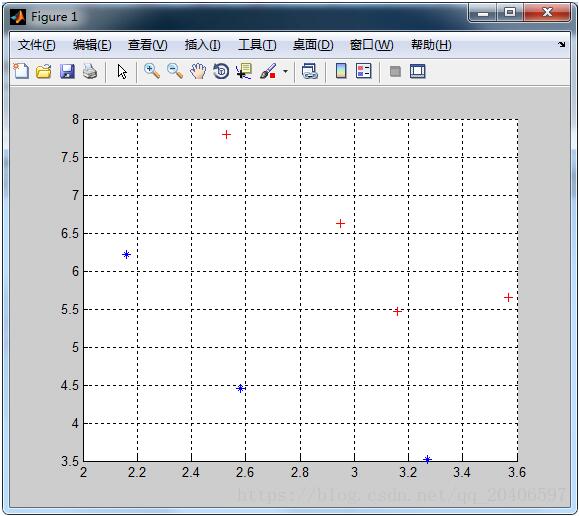
%这是训练数据集
%2.9500 6.6300 0
%2.5300 7.7900 0
%3.5700 5.6500 0
%3.1600 5.4700 0
%2.5800 4.4600 1
%2.1600 6.2200 1
%3.2700 3.5200 1
X=load('22.txt');
pos0=find(X(:,3)==0);
pos1=find(X(:,3)==1);
X1=X(pos0,1:2);
X2=X(pos1,1:2);
hold on
plot(X1(:,1),X1(:,2),'r+','markerfacecolor', [ 1, 0, 0 ]);
plot(X2(:,1),X2(:,2),'b*','markerfacecolor', [ 0, 0, 1 ]);
grid on
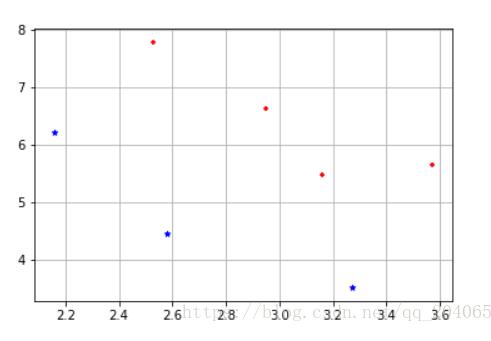
%输出样本的二维分布
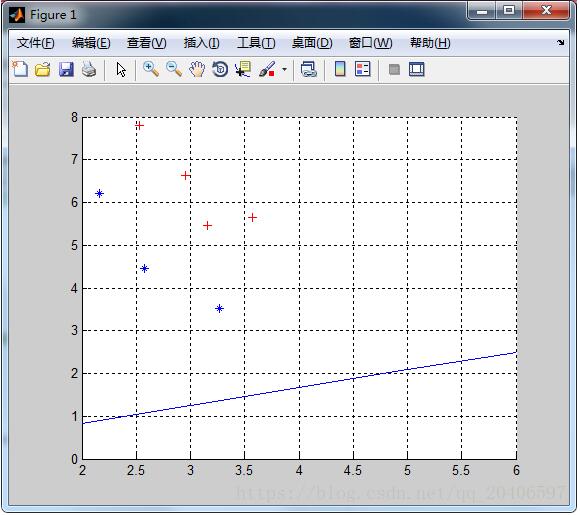
M1 = mean(X1); M2 = mean(X2); M = mean([X1;X2]); %第二步:求类内散度矩阵 p = size(X1,1); q = size(X2,1); a=repmat(M1,4,1); S1=(X1-a)'*(X1-a); b=repmat(M2,3,1); S2=(X2-b)'*(X2-b); Sw=(p*S1+q*S2)/(p+q); %第三步:求类间散度矩阵 sb1=(M1-M)'*(M1-M); sb2=(M2-M)'*(M2-M); Sb=(p*sb1+q*sb2)/(p+q); bb=det(Sw); %第四步:求最大特征值和特征向量 [V,L]=eig(inv(Sw)*Sb); [a,b]=max(max(L)); W = V(:,b);%最大特征值所对应的特征向量 %第五步:画出投影线 k=W(2)/W(1); b=0; x=2:6; yy=k*x+b; plot(x,yy);%画出投影线
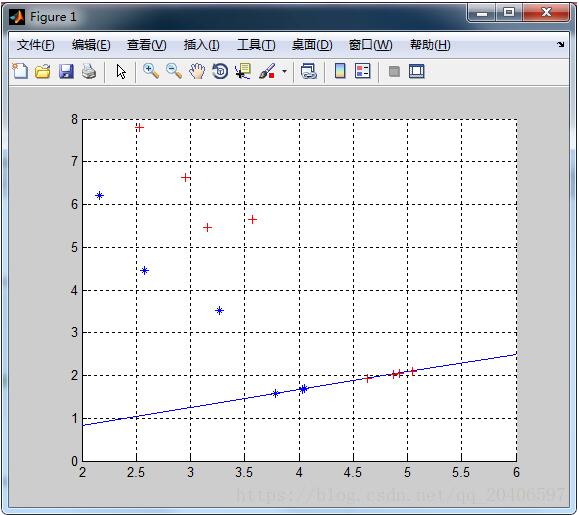
%计算第一类样本在直线上的投影点 xi=[]; for i=1:p y0=X1(i,2); x0=X1(i,1); x1=(k*(y0-b)+x0)/(k^2+1); xi=[xi;x1]; end yi=k*xi+b; XX1=[xi yi]; %计算第二类样本在直线上的投影点 xj=[]; for i=1:q y0=X2(i,2); x0=X2(i,1); x1=(k*(y0-b)+x0)/(k^2+1); xj=[xj;x1]; end yj=k*xj+b; XX2=[xj yj]; % y=W'*[X1;X2]'; plot(XX1(:,1),XX1(:,2),'r+','markerfacecolor', [ 1, 0, 0 ]); plot(XX2(:,1),XX2(:,2),'b*','markerfacecolor', [ 0, 0, 1 ]);
python 实现:
import numpy as np
import matplotlib.pyplot as plt
X=np.loadtxt("22.txt")
pos0=np.where(X[:,2]==0)
print(pos0)
pos1=np.where(X[:,2]==1)
print(pos1)
X1=X[pos0,0:2]
X1=X1[0,:,:]
print(X1,X1.shape)
X2=X[pos1,0:2]
X2=X2[0,:,:]
print(X2,X2.shape)
#第一步,求各个类别的均值 M1=np.mean(X1,0) M1=np.array([M1]) print(M1,M1.shape) M2=np.mean(X2,0) M2=np.array([M2]) print(M2) M=np.mean(X[:,0:2],0) M=np.array([M]) print(M) p=np.size(X1,0) print(p) q=np.size(X2,0) print(q) #第二步,求类内散度矩阵 S1=np.dot((X1-M1).transpose(),(X1-M1)) print(S1) S2=np.dot((X2-M2).transpose(),(X2-M2)) print(S2) Sw=(p*S1+q*S2)/(p+q) print(Sw) #第三步,求类间散度矩阵 Sb1=np.dot((M1-M).transpose(),(M1-M)) print(Sb1) Sb2=np.dot((M2-M).transpose(),(M2-M)) print(Sb2) Sb=(p*Sb1+q*Sb2)/(p+q) print(Sb) #判断Sw是否可逆 bb=np.linalg.det(Sw) print(bb) #第四步,求最大特征值和特征向量 [V,L]=np.linalg.eig(np.dot(np.linalg.inv(Sw),Sb)) print(V,L.shape) list1=[] a=V list1.extend(a) print(list1) b=list1.index(max(list1)) print(a[b]) W=L[:,b] print(W,W.shape) #根据求得的投影向量W画出投影线 k=W[1]/W[0] b=0; x=np.arange(2,10) yy=k*x+b plt.plot(x,yy) plt.scatter(X1[:,0],X1[:,1],marker='+',color='r',s=20) plt.scatter(X2[:,0],X2[:,1],marker='*',color='b',s=20) plt.grid() plt.show()
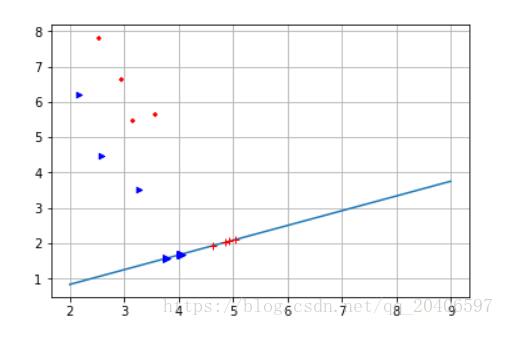
#计算第一类样本在直线上的投影点 xi=[] yi=[] for i in range(0,p): y0=X1[i,1] x0=X1[i,0] x1=(k*(y0-b)+x0)/(k**2+1) y1=k*x1+b xi.append(x1) yi.append(y1) print(xi) print(yi) #计算第二类样本在直线上的投影点 xj=[] yj=[] for i in range(0,q): y0=X2[i,1] x0=X2[i,0] x1=(k*(y0-b)+x0)/(k**2+1) y1=k*x1+b xj.append(x1) yj.append(y1) print(xj) print(yj) #画出投影后的点 plt.plot(x,yy) plt.scatter(X1[:,0],X1[:,1],marker='+',color='r',s=20) plt.scatter(X2[:,0],X2[:,1],marker='>',color='b',s=20) plt.grid() plt.plot(xi,yi,'r+') plt.plot(xj,yj,'b>') plt.show()
以上这篇Python实现线性判别分析(LDA)的MATLAB方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现高斯判别分析算法的例子
高斯判别分析算法(Gaussian discriminat analysis) 高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客).在这个算法中,我们假设p(x|y)p(x|y)服从多元正态分布. 注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所以对于XX的条件概率建模时要取多维正态分布. 多元正态分布 多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn
-
Python实现线性判别分析(LDA)的MATLAB方式
线性判别分析(linear discriminant analysis),LDA.也称为Fisher线性判别(FLD)是模式识别的经典算法. (1)中心思想:将高维的样本投影到最佳鉴别矢量空间,来达到抽取分类信息和压缩特种空间维数的效果,投影后保证样本在新的子空间有最大的类间距离和最小的类内距离.也就是说在该空间中有最佳的可分离性. (2)与PCA的不同点:PCA主要是从特征的协方差出发,来找到比较好的投影方式,最后需要保留的特征维数可以自己选择.但是LDA更多的是考虑了类别信息,即希望投影后不
-
matlab、python中矩阵的互相导入导出方式
还有一种最流行的h5py.. 过几天更新 ------------在python中导出矩阵至matlab------------ 如果矩阵是mxn维的. 那么可以用 : np.savetxt('dev_ivector.csv', dev_ivector, delimiter = ',') 对应matlab读取为: dev_ivec = csvread('dev_ivector.csv') ###csv格式其实就内定了结构体 如果矩阵是(n,)这种格式.['aagj' 'aagy' 'aann'
-
详解python里使用正则表达式的分组命名方式
详解python里使用正则表达式的分组命名方式 分组匹配的模式,可以通过groups()来全部访问匹配的元组,也可以通过group()函数来按分组方式来访问,但是这里只能通过数字索引来访问,如果某一天产品经理需要修改需求,让你在它们之中添加一个分组,这样一来,就会导致匹配的数组的索引的变化,作为开发人员的你,必须得一行一行代码地修改.因此聪明的开发人员又想到一个好方法,把这些分组进行命名,只需要对名称进行访问分组,不通过索引来访问了,就可以避免这个问题.那么怎么样来命名呢?可以采用(?P<nam
-

Python读取文件内容的三种常用方式及效率比较
本文实例讲述了Python读取文件内容的三种常用方式.分享给大家供大家参考,具体如下: 本次实验的文件是一个60M的文件,共计392660行内容. 程序一: def one(): start = time.clock() fo = open(file,'r') fc = fo.readlines() num = 0 for l in fc: tup = l.rstrip('\n').rstrip().split('\t') num = num+1 fo.close() end = time.cl
-
Python中几种导入模块的方式总结
模块内部封装了很多实用的功能,有时在模块外部调用就需要将其导入.常见的方式有如下几种: 1 . import >>> import sys >>> sys.path ['', 'C:\\Python34\\Lib\\idlelib', 'C:\\Windows\\system32\\python34.zip', 'C:\\Python34\\DLLs', 'C:\\Python34\\lib', 'C:\\Python34', 'C:\\Python34\\lib\\s
-
详解用Python处理HTML转义字符的5种方式
写爬虫是一个发送请求,提取数据,清洗数据,存储数据的过程.在这个过程中,不同的数据源返回的数据格式各不相同,有 JSON 格式,有 XML 文档,不过大部分还是 HTML 文档,HTML 经常会混杂有转移字符,这些字符我们需要把它转义成真正的字符. 什么是转义字符 在 HTML 中 <.>.& 等字符有特殊含义(<,> 用于标签中,& 用于转义),他们不能在 HTML 代码中直接使用,如果要在网页中显示这些符号,就需要使用 HTML 的转义字符串(Escape Se
-
基于Python中单例模式的几种实现方式及优化详解
单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. 比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息.如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪
-
python使用mysql的两种使用方式
Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymql pymsql是Python中操作MySQL的模块,在windows中的安装: pip install pymysql 入门:我们连接虚拟机中的centos中的mysql,然后查询test数据库中student表的数据 import pymysql #创建连接 conn = pymysql.connect(host='192.168.123.207',port=3306,user='r
-
对python 各种删除文件失败的处理方式分享
调用python提供的各种删除文件的操作均失败 返回值5,拒绝访问,但是多次确认文件没有被打开,文件是从一个zip包中解压出来后,没有任何打开读写等操作 最后调用windows的强制删除命令才搞定 try: #shutil.rmtree(UPDATE_DIR_STR) #this maybe can't delete some files by error 5 os.system("rd/s/q 目录名") except Exception, e: pass print e 以上这篇对
-
对Python _取log的几种方式小结
1. 使用.logfile 方法 #!/usr/bin/env python import pexpect import sys host="146.11.85.xxx" user="inteuser" password="xxxx" command="ls -l" child = pexpect.spawn('ssh -l %s %s %s'%(user, host, command)) child.expect('pass