Python之进行URL编码案例讲解
为什么要对URL进行encode
在写网络爬虫时,发现提交表单中的中文字符都变成了TextBox1=%B8%C5%C2%CA%C2%DB这种样子,观察这是中文对应的GB2312编码,实际上是进行了GB2312编码和urlencode。
那么为什么要对URL进行encode?
因为在标准的url规范中中文和很多的字符是不允许出现在url中的。为了字符编码(gbk、utf-8)和特殊字符不出现在url中,url转义是为了符合url的规范。
具体代码
urlencode编码:urllib中的quote方法
import urllib.parse
chinese_str = '中文'
# 先进行gb2312编码
chinese_str = chinese_str.encode('gb2312')
# 输出 b'\xd6\xd0\xce\xc4'
# 再进行urlencode编码
chinese_str_url = urllib.parse.quote(chinese_str)
# 输出 %D6%D0%CE%C4
urldecode解码:urllib中的unquote方法
# 由于编码问题会报错,还未解决
urllib.parse.unquote('%D6%D0%CE%C4')
# :的url编码为%3A,可输出 http://www.baidu.com
urllib.parse.unquote('http%3A//www.baidu.com')
其它应用
URL中%u开头的字符
在网页的表单参数中,还遇到过%u开头的字符,得知是中文对应的Unicode编码值
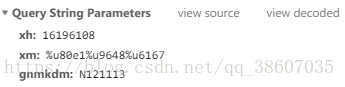
以下代码可以实现字符与unicode编码值的转换
str = '姓名'
# 获得urlencode编码
str = str.encode('unicode_escape')
print(str)
# 输出 b'\\u59d3\\u540d'
str=str.decode('utf-8')
print(str)
# 输出 \u59d3\u540d
str=str.encode('utf-8')
print(str)
# 输出 b'\\u59d3\\u540d'
str=str.decode('unicode_escape')
print(str)
# 输出 姓名
hidden隐藏域对象作为表单参数
在爬取ASP.NET平台的网站信息时,有VIEWSTATE、EVENTVALIDATION这样的hidden隐藏域对象,作为表单参数发送post请求,所以需要从网页源代码中获取。
但post请求中的参数值是URL编码值,而网页源码中获取到的是URL解码值,所以需要进行urlencode编码。
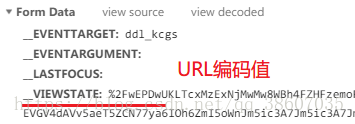
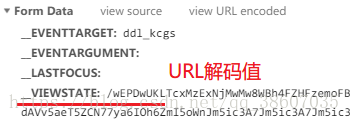

相关代码
# 网页源码上得到之后,需要urlencode编码 hid['VIEWSTATE'] = urllib.parse.quote(soup.find(id="__VIEWSTATE")['value'])
相关工具
谷歌浏览器的开发者工具中可以查看参数的urlencode和decode值
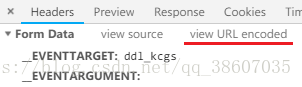
可选择编码格式为UTF-8或GB2312
可查汉字的GB2312等中文编码和Unicode编码
参考链接
python中的urlencode和urldecode(代码)
到此这篇关于Python之进行URL编码案例讲解的文章就介绍到这了,更多相关Python之进行URL编码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python源文件的字符编码知识点详解
默认情况下,Python 源码文件以 UTF-8 编码方式处理.在这种编码方式中,世界上大多数语言的字符都可以同时用于字符串字面值.变量或函数名称以及注释中--尽管标准库中只用常规的 ASCII 字符作为变量或函数名,而且任何可移植的代码都应该遵守此约定.要正确显示这些字符,你的编辑器必须能识别 UTF-8 编码,而且必须使用能支持打开的文件中所有字符的字体. 1.如果不使用默认编码,要声明文件所使用的编码,文件的第一行要写成特殊的注释. 语法如下所示: # -*- coding: encodi
-

Python新建项目自动添加介绍和utf-8编码的方法
你是不是觉得每次新建项目都要写一次# coding:utf-8,感觉特烦人 呐!懒(fu)人(li)教程来啦,先看效果图吧 中文版 如图进入设置 然后将下列内容粘贴进去就行了,是不是很简单 """ -*- coding:utf-8 -*- Author:${USER} Age:24 Call:199**9**9*9 Email:nsq88@vip.qq.com Time: ${DATE} ${TIHE} Software: ${PRODUCT_NAME} "&quo
-
解决python3 中的np.load编码问题
由于在Python2 中的默认编码为ASCII,但是在Python3中的默认编码为UTF-8. 问题: 所以在使用np.load(det.npy)的时候会出现错误提示: you may need to pass the encoding= option to numpy.load 解决方法: 当遇到这种情况的时候,用np.load(det.npy,encoding="latin1")就可以了. 补充:python解决numpy导入乱码问题------已解决 使用numpy的loadtx
-
详解python中文编码问题
目录 1. 在Python中使用中文 1.1 Windows控制台 1.2 Windows IDLE(在Shell上运行) 1.3 在IDLE上运行代码 1.4 Windows Eclipse 1.5 从文件读取中文 1.6 在数据库中使用中文 1.7 在XML中使用中文 1. 在Python中使用中文 在Python中有两种默认的字符串:str和unicode.在Python中一定要注意区分"Unicode字符
-
python中字符串的编码与解码详析
1. 常用的编码 ASCII:只能表示一些字母,数字和特殊的字符,占一个字节 GBK:国家简体中文字符集和繁体字符集,兼容ASCII,占两个字节 Unicode:能够表示全世界上所有的字符,Unicode有人说占4个字节也有人说占2个字节,但中文占2个字节 UTF-8:Unicode的压缩版,占1~3个字节,其中中文占三个字节 2.补充:计算机表示的单位: bit: 位,计算机最小的表示单位 bytes:字节,最小的存储单位,1bytes=8bit,1bytes简写成1B 1KB = 1024B
-
python 编码中为什么要写类型注解?
1.背景 我们先谈谈为什么在Python编码过程中强烈推荐使用类型注解 ? Python对于初学者来说是非常好上手,原因是在于对计算机底层原理的高度封装和动态语言的特性使得Python用起来非常的舒适.但这种"舒适"是有代价的,我们可能听说过一句形容动态语言的话,动态一时爽,一直动态一直爽.为什么会这么说?动态的确会赋予我们在编码时更多的灵活性与能力,但是动态带来的是更多的不确定性及混乱,导致了后来的维护者甚至作者自己都会产生很大的维护压力(可以想象一个经过几年迭代的复杂系统,如果大部
-
Python3 json模块之编码解码方法讲解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它基于ECMAScript的一个子集. JSON采用完全独立于语言的文本格式,这些特性使JSON成为理想的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成,在接口数据开发和传输中非常常用. Python3中我们利用内置模块json解码和编码JSON对象.json模块提供了四个功能: dumps.dump.loads.load dumps 把数据类型转换成字符串 dump 把数据类型转换成字符串
-
python基础之编码规范总结
一.PEP 8规范 官方文档:https://legacy.python.org/dev/peps/pep-0008/ 中文翻译: https://www.jb51.net/article/103944.htm 二.缩进 每一级缩进4个空格. 续行应该与包裹元素对齐,要么使用圆括号,方括号,花括号内的隐式行连接来垂直对齐,要么使用挂行缩进对齐.当使用挂行缩进对齐时,应该考虑到第一行不应该有参数,以及使用缩进以区分自己是续行. 对齐缩进(左右括号对齐) def long_function_name
-
Python之进行URL编码案例讲解
为什么要对URL进行encode 在写网络爬虫时,发现提交表单中的中文字符都变成了TextBox1=%B8%C5%C2%CA%C2%DB这种样子,观察这是中文对应的GB2312编码,实际上是进行了GB2312编码和urlencode. 那么为什么要对URL进行encode? 因为在标准的url规范中中文和很多的字符是不允许出现在url中的.为了字符编码(gbk.utf-8)和特殊字符不出现在url中,url转义是为了符合url的规范. 具体代码 urlencode编码:urllib中的quote
-
Python之urlencode和urldecode案例讲解
python中的urlencode和urldecode python将字符串转化成urlencode ,或者将url编码字符串decode的方法: 方法1: urlencode:urllib中的quote方法 >>> from urllib import quote >>> quote(':') '%3A' >>> quote('http://www.baidu.com') 'http%3A//www.baidu.com' urldecode:urll
-
python字符串与url编码的转换实例
主要应用的场景 爬虫生成带搜索词语的网址 1.字符串转为url编码 import urllib poet_name = "李白" url_code_name = urllib.quote(poet_name) print url_code_name #输出 #%E6%9D%8E%E7%99%BD 2.url编码转为字符串 import urllib url_code_name = "%E6%9D%8E%E7%99%BD" name = urllib.unquote(
-
Python进行区间取值案例讲解
需求背景: 进行分值计算.如下图,如果只是一两个还好说,写写判断,但是如果有几十个,几百个,会不会惨不忍睹.而且,下面的还是三种情况. 例如: 解决: # 根据值.比较list, 值list,返回区间值, other_value 即不在的情况 def get_value_by_between(self, compare_value, compare_list, value_list, other_value, type="compare", left=False, right=True
-
python实现中文转换url编码的方法
本文实例讲述了python实现中文转换url编码的方法.分享给大家供大家参考,具体如下: 今天要处理百度贴吧的东西.想要做一个关键词的list,每次需要时,直接添加 到list里面就可以了.但是添加到list里面是中文的情况(比如'丽江'),url的地址编码却是'%E4%B8%BD%E6%B1%9F',因此需 要做一个转换.这里我们就用到了模块urllib. >>> import urllib >>> data = '丽江' >>> print dat
-
python中判断文件编码的chardet(实例讲解)
1.实测,这个版本在32位window7和python3.2环境下正常使用. 2.使用方法:把解压后所得的chardet和docs两个文件夹拷贝到python3.2目录下的Lib\site-packages目录下就可以正常使用了. 3.判断文件编码的参考代码如下: file = open(fileName, "rb")#要有"rb",如果没有这个的话,默认使用gbk读文件. buf = file.read() result = chardet.detect(buf)
-
python代码实现备忘录案例讲解
文件操作 TXT文件 读取txt文件 读取txt文件全部内容: def read_all(txt): ...: with open(txt,'r') as f: ...: return f.read() ...: read_all('test.txt') Out[23]: 'a,b,c,d\ne,f,g,h\ni,j,k,l\n' 按行读取txt文件内容 def read_line(txt): ...: line_list = [] ...: with open(txt,'r') as f: .
-
Python之根据输入参数计算结果案例讲解
一.问题描述 define function,calculate the input parameters and return the result. 数据存放在 txt 里,为 10 行 10 列的矩阵. 编写一个函数,传入参数:文件路径.第一个数据行列索引.第二个数据行列索引和运算符. 返回计算结果 如果没有传入文件路径,随机生成 10*10 的值的范围在 [6, 66] 之间的随机整数数组存入 txt 以供后续读取数据和测试. 二.Python程序 导入需要的依赖库和日志输出配置 # -
-
python之json文件转xml文件案例讲解
json文件格式 这是yolov4模型跑出来的检测结果result.json 下面是截取的一张图的检测结果 { "frame_id":1, #图片的序号 "filename":"/media/wuzhou/Gap/rgb-piglet/test/00000000.jpg", #图片的路径 "objects": [ #该图中所有的目标:目标类别.目标名称.归一化的框的坐标(xywh格式).置信度 {"class_id&
-
python实现CTC以及案例讲解
在大多数语音识别任务中,我们都缺少文本和音频特征的alignment,Connectionist Temporal Classification作为一个损失函数,用于在序列数据上进行监督式学习,可以不需要对齐输入数据及标签. 对于输入序列 X = [ x 1 , x 2 , . . , x T ] X=[x_1, x_2, .., x_T] X=[x1,x2,..,xT] 和 输出序列 Y = [ y 1 , y 2 , . . . , y U ] Y = [y_1, y_2, ...,