MySQL中Like模糊查询速度太慢该如何进行优化
目录
- 一、前言:
- 二、第一个思路建索引
- 三、INSTR
- 附:Like是否使用索引?
- 总结
一、前言:
我建了一个《学生管理系统》,其中有一张学生表和四张表(小组表,班级表,标签表,城市表)进行联合的模糊查询,效率非常的低,就想了一下如何提高like模糊查询效率问题
注:看本篇博客之前请查看:Mysql中如何查看Sql语句的执行时间
二、第一个思路建索引
1、like %keyword 索引失效,使用全表扫描。
2、like keyword% 索引有效。
3、like %keyword% 索引失效,使用全表扫描。
使用explain测试了一下:
原始表(注:案例以学生表进行举例)
-- 用户表
create table t_users(
id int primary key auto_increment,
-- 用户名
username varchar(20),
-- 密码
password varchar(20),
-- 真实姓名
real_name varchar(50),
-- 性别 1表示男 0表示女
sex int,
-- 出生年月日
birth date,
-- 手机号
mobile varchar(11),
-- 上传后的头像路径
head_pic varchar(200)
);
建立索引
#create index 索引名 on 表名(列名); create index username on t_users(username);
like %keyword% 索引失效,使用全表扫描
explain select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like '%h%';

like keyword% 索引有效。
explain select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like 'wh%';

like %keyword 索引失效,使用全表扫描。

三、INSTR
这个我最开始都没听说过,今天查阅了一下资料,才知道有这个宝贝东西,
instr(str,substr):返回字符串str串中substr子串第一个出现的位置,没有找到字符串返回0,否则返回位置(从1开始)
#instr(str,substr)方法
select id,username,password,real_name,sex,birth,mobile,head_pic
from t_users
where instr(username,'wh')>0 #0.00081900
#模糊查询
select id,username,password,real_name,sex,birth,mobile,head_pic
from t_users
where username like 'whj'; # 0.00094650
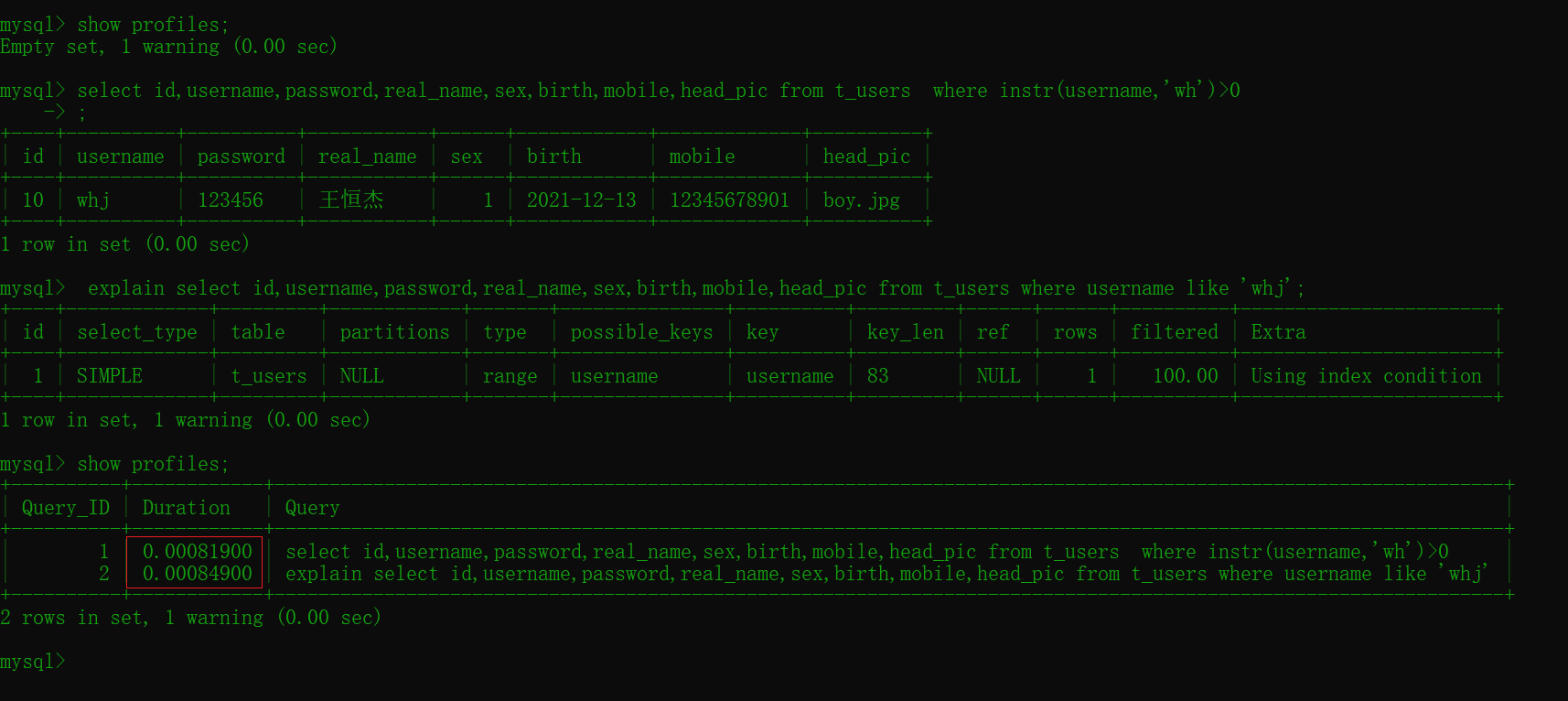
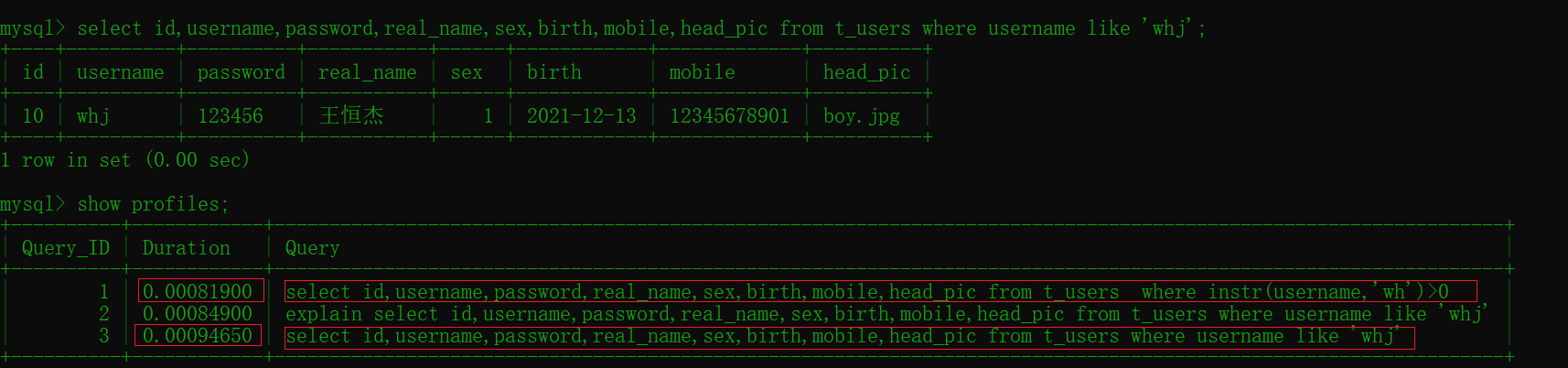
比较两个效率差距不大主要原因是数据较少,最好多准备点原始数据进行测试效果最佳
附:Like是否使用索引?
1、like %keyword 索引失效,使用全表扫描。但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。
2、like keyword% 索引有效。
3、like %keyword% 索引失效,也无法使用反向索引。
总结
到此这篇关于MySQL中Like模糊查询速度太慢该如何进行优化的文章就介绍到这了,更多相关MySQL Like模糊查询慢优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySql like模糊查询通配符使用详细介绍
一.SQL模式 SQL的模式匹配允许你使用"_"匹配任何单个字符,而"%"匹配任意数目字符(包括零个字符).在 MySQL中,SQL的模式缺省是忽略大小写的.下面显示一些例子.注意在你使用SQL模式时,你不能使用=或!=:而使用LIKE或NOT LIKE比较操作符. SELECT 字段 FROM 表 WHERE 某字段 Like 条件 其中关于条件,SQL提供了四种匹配模式: 1,%:表示任意个或多个字符.可匹配任意类型和长度的字符. 比如 SELECT * FRO
-
MySQL Like模糊查询速度太慢如何解决
问题:明明建立了索引,为何Like模糊查询速度还是特别慢? Like是否使用索引? 1.like %keyword 索引失效,使用全表扫描.但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描. 2.like keyword% 索引有效. 3.like %keyword% 索引失效,也无法使用反向索引. 使用mysql的explain简单测试如下: explain select * from company_info where cname like '%小%'
-
mysql中like % %模糊查询的实现
1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] WHERE u_name LIKE '%三%' 将会把u_name为"张三","张猫三"."三脚猫","唐三藏"等等有"三"的记录全找出来. 另外,如果需要找出u_name中既有"三"又有"猫"的记录,请使用a
-
mysql对于模糊查询like的一些汇总
1.常见用法: (1)搭配%使用 %代表一个或多个字符的通配符,譬如查询字段name中以大开头的数据: (2)搭配_使用 _代表仅仅一个字符的通配符,把上面那条查询语句中的%改为_,会发现只能查询出下面一条数据: 2.使用like模糊查询会导致索引失效,在数据量大的时候会有性能问题 (1)尽量少以%或者_开头进行模糊查询 通过explain执行计划,我们发现,使用like模糊查询时,如果不以%和_开头查询的话,索引还是有效的 以%或者_开头查询,索引失效 (2)使用覆盖索引 当查询的的条件和查询
-

MySQL中Like模糊查询速度太慢该如何进行优化
目录 一.前言: 二.第一个思路建索引 三.INSTR 附:Like是否使用索引? 总结 一.前言: 我建了一个<学生管理系统>,其中有一张学生表和四张表(小组表,班级表,标签表,城市表)进行联合的模糊查询,效率非常的低,就想了一下如何提高like模糊查询效率问题 注:看本篇博客之前请查看:Mysql中如何查看Sql语句的执行时间 二.第一个思路建索引 1.like %keyword 索引失效,使用全表扫描. 2.like keyword% 索引有效. 3.like %keyword% 索引失
-
深入了解MySQL中的慢查询
目录 一.什么是慢查询 二.慢查询的危害 三.慢查询常见场景 总结 一.什么是慢查询 什么是MySQL慢查询呢?其实就是查询的SQL语句耗费较长的时间. 具体耗费多久算慢查询呢?这其实因人而异,有些公司慢查询的阈值是100ms,有些的阈值可能是500ms,即查询的时间超过这个阈值即视为慢查询. 正常情况下,MySQL是不会自动开启慢查询的,且如果开启的话默认阈值是10秒 # slow_query_log 表示是否开启 mysql> show global variables like '%slo
-
JS中的模糊查询功能
在项目中会用到模糊查询,之前在首页是用的element的tree显示的目录,会有用到搜索,但tree里边会有自带的模糊查询,用filter-node-method方法使用 但上次的项目中 又涉及到不试用插件的模糊搜索,使用原生来搜索,其实网上有很多种,但个人觉得正则还是好用,不区别大小写很方便,之前看网上测评速度,正则的速度也挺快的, <input type="text" v-model="textData" /> data() { return { t
-
浅谈mysql通配符进行模糊查询的实现方法
在mysql数据库中,当我们需要模糊查询的时候 ,我们会使用到通配符. 首先我们来了解一下2个概念,一个是操作符,一个是通配符. 操作符 like就是SQL语句中的操作符,它的作用是指示在SQL语句后面的搜索模式是利用通配符而不是直接相等匹配进行比较. 注意:如果使用like操作符时没有使用通配符,那么效果是和等号是一致的. SELECT id,title FROM table WHERE title like '张三'; 这种写法就只能匹配张三的记录,而不能匹配像张三是个好人这样的记录. 通配
-
MyBatis中的模糊查询语句
其实就只有一条sql语句 <select id = "search" resultType = "material"> select material_id,material_num,material_name,material_type,material_model,id from material where material_name like '%${value}%' or material_num like '%${value}%' </
-
在java List中进行模糊查询的实现方法
比如我有下面这样一个List,里面存放的是多个Employee对象.然后我想对这个List进行按照Employee对象的名字进行模糊查询.有什么好的解决方案么? 比如我输入的查询条件为"wang",那么应该返回只包含employee1的List列表. List list = new ArrayList(); Employee employee1 = new Employee(); employee1.setName("wangqiang"); employee1.s
-
MySql中使用正则表达式查询的方法
正则表达式常用来检索和替换那些符合魔种模式的文本.例如从一个文本文件中提取电话号码,查找一篇文章中重复的单词或者替换用户输入的某些敏感词汇等.Mysql 使用 REGEXP 关键字指定正则表达式的字符匹配模式. 1. 字符 '^' 查询以特定字符或字符串开头的记录 SELECT * FROM user WHERE email REGEXP '^a' 字符 '^' 匹配以特定字符或字符串开头的记录,以上语句查询邮箱以 a 开头的记录 2. 字符 ' 查询以特定字符或字符串结尾的记录 SELECT
-
jq.ajax+php+mysql实现关键字模糊查询(示例讲解)
对于这个功能企业上还算比较实用,推荐给大家: index.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"> </head> <style> *{margin:0;padding:0;} .text{width:200px;height:30px;line-height:30px;font-size:14px;outline:none;} ul{wid