哔哩哔哩Android项目编译优化
目录
- 背景
- 编译优化
- 工作流程
- 快编插件
- 获取工程树结构
- version版本
- 源码orAAR
- 主动Skip模块
- Configuration策略
- 远端upload
- R8 class check
- Faster
- 云编译
- 独立的编译单元
- 展望
- 结语
背景
哔哩哔哩的安卓项目的工程结构是Monorepo(单仓)变种,也就是所有的代码都在一个工程结构下编译。我们认为Monorepo(单仓)是一个非常适合我们的开发模式,主要是因为其提供的原子提交,可见性,参与度,切片的稳定性等等优点,这些都是我们选择Monorepo的原因。但是因为权限管控,ijkplayer等双端通用工程的原因,还是拆开了多个git仓库。通过git权限的方式来拆分了工程结构,然后通过Gradle Plugin的形式进行了多工程的组合,在CI打包环境上让工程具备Monorepo的能力。
点击可了解多仓和单仓的差别
随着代码长时间迭代,业务模块数量增多,当前工程有500+的模块以及19个复合构建。如果所有的模块都用源代码编译,打一个包本地可能需要大概30分钟的时间才能完成编译。而且哔哩哔哩的安卓工程是一个上百人同时开发的项目,如果一小个改动都需要30分钟的时间投入编译中,对于开发同学来说可能心态都要崩了。
下图是工程在CI上全量编译的情况下,编译耗时大概是16.6分钟,打包机的性能是优于本地电脑的,所以速度会更快一点。
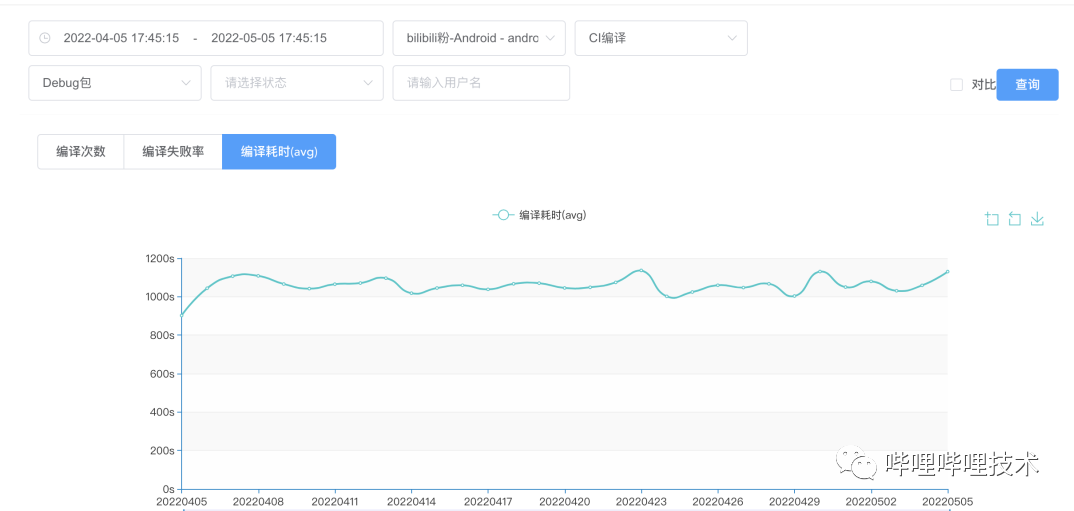
让编译速度变得更快也就迫在眉睫,而且这个模式是针对开发同学,让他们可以快速对模块变更的代码负责。同时也希望这个模式是在不影响当前的工程结构,让他们的打包速度能变得更快。
编译优化
我们通过添加--scan参数,观察了全源码情况下的编译流程。在没有编译缓存的情况下,每个模块都是源代码,所以都需要执行将源代码编译成字节码的过程。同时还需要完成所有工程的依赖配置等等展开,这些过程都是比较耗时的。而工程编译的大部分耗时都集中在将源码编译字节码产物的过程中,也就是Gradle Task阶段。下图就是我从buildScan中找出来耗时相对较长的Task任务,可以看出来有的编译任务的耗时在2min以上。
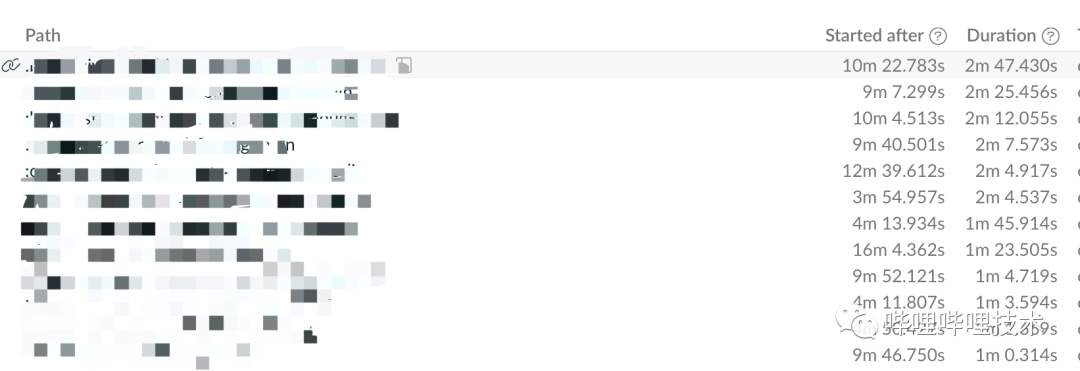
如果能将模块直接变更成aar产物,那么就可以跳过这些模块的编译任务,直接使用他们的二进制产物。但是直接使用aar产物是有风险的,会牺牲一部分代码的正确性,同时代码可能会有滞后性。另外编译阶段会进行很多语法校验的操作,而直接更换成aar产物了就会跳过这部分检查。
而我们快编的做法就是牺牲一部分代码正确性,将没有变更的源代码变成aar产物,在编译阶段直接采用aar产物进行编译,这样就可以跳过部分源代码编译环节。但是因为跳过了源代码编译阶段,所以有一部分编译时的常量优化,方法签名变更或者其他问题就可能会出现。
在快编模式下编译的平均耗时优化到了6min左右。因为ci的特性,每次都需要清空文件夹之后重新clone工程,这样会有额外的工程准备时间。另外在变更的模块比较少的情况下,编译速度则会更快一点。
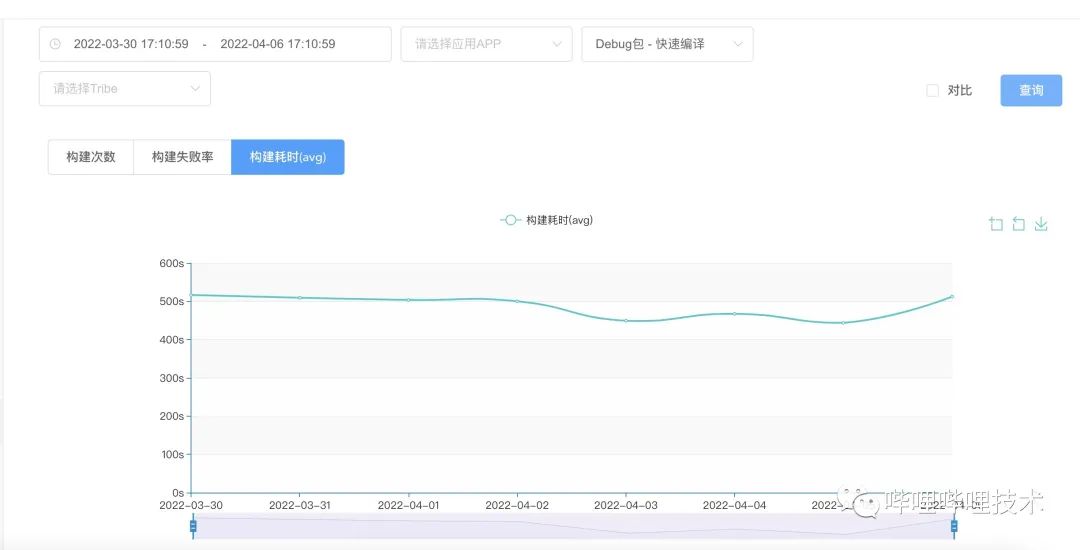
另外这些问题使用快编的人是否可以接受?我们目的主要是优化下开发编译速度,能让他们可以更快的出包,更快的调试代码,所以我们认为这种取舍还是合理的。
如何可以及时的发现这些方法签名变更的问题呢?下面让我们慢慢展开我们的编译优化方案。
工作流程
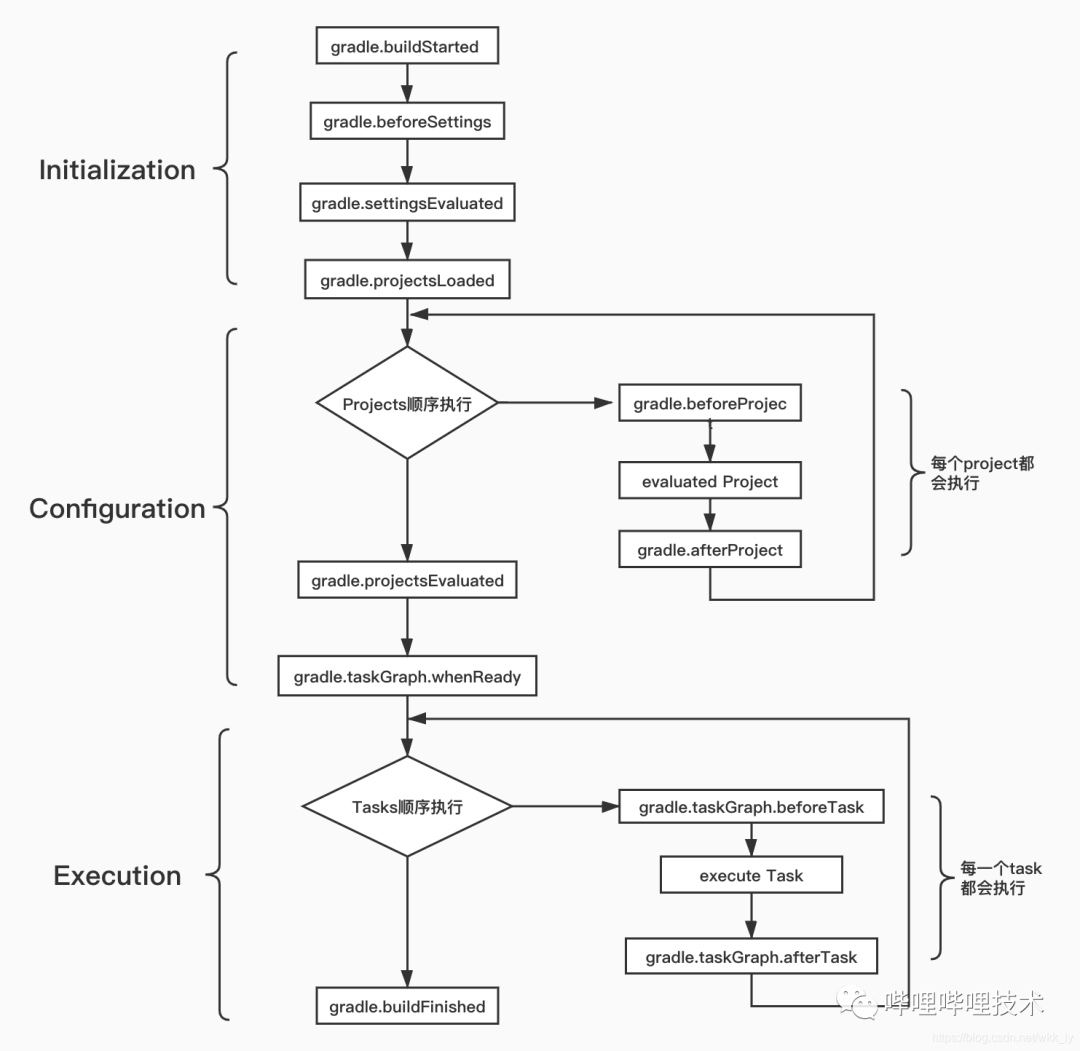
我们要先从gradle build的生命周期开始展开了,可以分为三个大流程,一个是初始化阶段,一个是配置阶段,另外一个是task执行阶段。一般配置阶段会加载完成工程的依赖关系以及配置信息等工作。
我们会在生命周期的不同阶段,执行一些的代码,然后篡改一些编译相关的属性,从而做到源代码和aar产物之间的替换操作。下面是我列出来我们的项目的快编的工作流程。
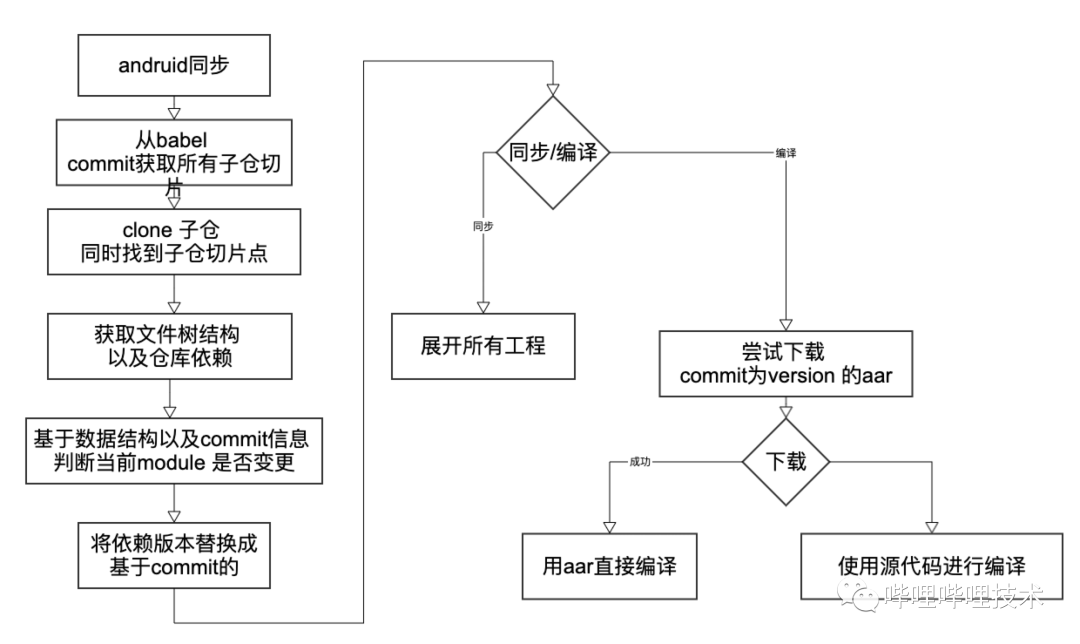
andruid是当前的工程名,因为要做多个业务之间的代码隔离,所以我们还是把单个仓库拆分成了多个工程结构,如果一个有所有仓库权限的人或者CI机器可以获取到所有代码仓库的权限,并全源码打包。
babel commit 是负责来存放这些仓库的稳定切片信息,会在当前分支push到远端之后pipeline完成之后生成,然后以git commit的形式存放在andruid工程下。当没有对应仓库代码权限则会使用babel commit内存放的version版本信息。
- Gradle 配置阶段之前先根据缓存信息获取所有子仓切片
- 同步多个业务仓库配置
- 通过遍历展开文件树,生成工程对应的数据结构
- 基于当前模块的commit来生成version,尝试下载aar
- 基于下载结果选择使用源码还是aar进行编译
快编插件
上面我们讲完了大体的流程是如何的,下面我会抛出一些问题,就以下几个问题来看我们是如何解决的:
- 如何确保代码相对来说的准确性呢?以什么来作为唯一标识符?
- 如何在gradle的配置阶段就完成源码到aar的替换呢?
- 当前的aar产物出现了方法签名变更的情况,我们有没有办法快速的刷新所有的缓存呢?
- 有没有办法让同步流程也变得更快?
- 在什么情况下谁来生成上传这个aar产物?
获取工程树结构
我们要在settings.gradle执行的阶段就先获取到当前目录下有多少个工程,然后我们才能基于这个工程数据结构,先去尝试下载每个模块的远端aar产物,如果无法下载到该模块,则意味着模块已经出现了变更。然后在gradle配置阶段之前进行替换操作替换掉能下载到aar的模块。
这里我们需要先定义出一个数据结构来负责存放我们所需要收集的模块编译信息。先盘点下我们所要收集的数据结构Project,Project 数据结构如下表格所示。后面我们会多次使用到这个数据结构,通过改变其中的值属性来变更我们的编译流程。
|
字段名 |
含义 |
|
dir |
文件路径 |
|
group |
组名 |
|
name |
模块名 |
|
version |
版本号 |
|
change |
是否变更 |
|
a8Change |
方法签名是否变更 |
maven.yaml负责存放当前工程的group+name 信息
数据结构的生成规则如下,我们会以当前文件夹作为根节点,之后遍历展开当前的文件树形结构,每当检测到一个文件夹下面同时含有build.gralde和一个maven.yaml的文件的情况下,我们就会生成一个Project的数据结构,之后加入列表中。
当这次文件夹遍历操作完成之后,我们就会得到当前工程下有多少个模块,然后他们的group+name是什么,另外通过计算出缓存的version版本是多少。通过这些信息来帮助我们去完成我们的快编逻辑。但是当前这个操作需要耗费大概1分钟的时间。
version版本
我们没有按照Gradle标准的1.0.0这种版本方式来定义模块版本,这种方式很难和当前的代码变更结合到一起,而且需要一套全局version来进行版本管理。另外也很难达到准确表达当前分支下的真实缓存情况。
为什么要用commit的sha这个作为版本号呢?因为大仓是基于一个稳定切片的编程模式。既然切片是稳定的情况下,那么也就是当前的每个Project的commit提交也都是稳定的。
我们通过git指令去获取到当前的Project数据结构对应的文件夹下的commit的sha值,一定是每一个Project下面的最接近的commit。然后根据上面的加盐规则来生成这个版本号,之后作为数据结构的一部分。
static def getGitSha(String file) {
def text = "git rev-parse --show-toplevel".execute(null, new File(file)).text.trim()
if (text.length() == 0) {
return ""
}
def releaPath = file.replace(text + "/", "")
def cmd = 'git log --max-count=1 --pretty=%H '
if (releaPath.length() > 0) {
cmd = cmd + " " + releaPath
}
def sha = cmd.execute(null, new File(text)).text.trim()
if (sha.startsWith("HEAD")) {
return ""
}
if (sha.startsWith("fatal:")) {
return ""
}
return sha
}
当前的aar产物出现了方法签名变更的情况下,我们有没有办法快速的刷新所有的缓存呢?
所以我们引入了一个盐值,然后将这个盐值和sha结合到一起作为当前仓库的真实的version。当我们的盐值发生变化就会导致当前所有的缓存失效,然后就会触发重新生成新的version版本了。所以只要修改盐值的值就可以将所有aar的版本进行统一的升级。
还需要对variant也加入version版本生成的逻辑中。不同的变种的代码也都是不同的,需要区分变种来选择下载不同的aar版本。
源码orAAR
等完成上述步骤之后,我们的工程的快编的前置工作就准备的差不多了,接下来就是尝试性去下载这个version版本的aar。如果这个版本存在,意味着当前仓库并没有发生实际的变更,可以用该产物直接替换掉当前的源代码。
如果当前的version的版本无法下载,可以认为这个commit在远端aar并不存在,之后我们就可以将Project标记为已经发生变更,然后它将直接使用源码编译。
这里还有些边界条件,如果当前的变更没有提交的情况下,我们需要获取当前的git项目的变更内容,然后基于文件路径匹配到对应的Project,将它切换到源码编译的情况下,获取变更文件路径代码如下:
static List<String> getAllChangeFile(File file) {
def text = "git status -u -s".execute(null, file).text
String[] txts = text.split("\n")
List<String> result = new ArrayList<>()
txts.each { String item ->
if (item.length() > 3) {
result.add(item.substring(3))
}
}
return result
}
主动Skip模块
完成上述几步之后,工程结构就已经是一个很清晰的状态了,我们已经知道当前工程有多少个模块,哪些模块发生了变更哪些模块没有变更,另外没有变更模块的aar version版本,同时也拿到了下载的产物。
接下来我们需要做的操作是快编里面非常重要的,将当前的没有变更的源代码移除。这样工程所剩下来的就是发生了变更的模块,通过这种方式就可以编译最少的变更模块了,从而缩短打包流程和避免无变更的模块配置时间。
工程内含有10+的复合构建(Composing builds),所以这里我们需要支持两个不同的场景,一个是当前当前工程下的settings.gradle下的include模块进行移除,还有一个就是移除没有变更的includebuilding工程。
摘自 Gradle 文档:复合构建只是包含其他构建的构建。在许多方面,复合构建类似于 Gradle 多项目构建,不同之处在于,它包括完整的 builds ,而不是包含单个 projects。
组合通常独立开发的构建,例如,在应用程序使用的库中尝试错误修复时,将大型的多项目构建分解为更小,更孤立的块,可以根据需要独立或一起工作。
复合构建的属性都是存放在Gradle Settings内的IncludedBuildSpec属性。通过groovy语言的动态属性,获取到DefaultSettings下的getIncludedBuilds方法的返回值,从而获取到当前所有的复合构建,然后根据IncludedBuildSpec的rootDir路径来决定哪些复合构建是不需要参与当前编译的。
还有就是Settings下的模块通过调用settings.rootProject.children.clear(),include对应的是Gradle Settings下的ProjectDescriptor,我们将所有的原始模块数据的清空,然后基于Project数据结构将变更的Project的文件路径来插入列表,重新生成新的ProjectDescriptor。
Configuration策略
配置阶段最后就是要将项目内的依赖版本更换到我们当前Project数据结构内的version版本上去了。我们项目内的依赖版本只是起到一个占位的作用,全量编译的时候源代码,快速编译的情况下就需要替换成对应版本的aar产物。
gradle在配置阶段后期,Configuration提供一个ResolutionStrategy策略,让我们主动的来筛选更改所需要的远端依赖库的版本。
我们可以基于Project中的group,moduleName,version,然后通过ResolutionStrategy来进行版本替换,简单的说就是当group+name的组合符合的情况下替换成我们计算出来的version,之后再重新指向这个新版本就可以了。
eachDependency { DependencyResolveDetails details ->
Logger.debug("requested " + requested.group + ":" + requested.name + ":" + requested.version)
Logger.debug("target " + details.getTarget())
def targetInfo = details.getTarget().toString().split(":")
String sVersion = compare.select(targetInfo[0], targetInfo[1], targetInfo[2])
if (sVersion != targetInfo[2]) {
def tar = targetInfo[0] + ":" + targetInfo[1] + ":" + sVersion
Logger.debug("git select " + tar)
details.useTarget(tar)
details.because(" git flow ")
}
Logger.debug("target new " + details.getTarget())
}
远端upload
那么是由谁来执行这个aar版本的发布任务的呢?
当我们的每个commit push提交到远端时,gitlab的ci都会执行一些pipeline任务。这里我们加了一个发布任务,将所有变更的模块发布到远端。
这部分和之前的version计算相同,先计算出工程所有的commit version的aar,然后尝试下载,之后将下载不到的定义为变更模块,最后将这部分发布到远端。upload阶段就是通过maven-publish插件,发布aar到自定义远端地址,当然内部有些小改动这里就不多展开了。
另外我们还进行了一些小小的优化调整,区分当前到底是idea同步还是编译任务,只在编译阶段插入了maven-publish插件。这样略微加快了一点点项目的同步速度。
R8 class check
当把一大部分模块切换到aar产物后,有可能会发生方法签名常量优化等变更不同步的问题。这里我们就需要一种手段来检测当前apk中是否有一些危险的方法调用,然后让这些可能会崩溃的地方在代码合入之前就暴露出来。
我们在Android R8的基础上,开发了一套专门针对于方法签名检查的任务,我们叫做A8检查。我们先来简单的了解下R8的一些小知识。
正常情况下混淆可以拿来压缩代码体积,其中包括删除无效代码等等。代码缩减(也称为“摇树优化”)是指移除 R8 确定在运行时不需要的代码的过程。此过程可以大大减小应用的大小,例如,当您的应用包含许多库依赖项,但只使用它们的一小部分功能时。
也就是在R8进行代码压缩的过程中,其实就已经包含有所有语法树信息了。我们如果用类似的机制,就可以获取到对应的方法签名,然后通过遍历循环之后检测出是不是当前类方法签名存在问题。
public static void run(A8Command command) throws Throwable {
AndroidApp app = command.getInputApp();
InternalOptions options = command.getInternalOptions();
ExecutorService executor = ThreadUtils.getExecutorService(options);
new A8(options, command.forceReflectionError).run(app, executor, false);
}
A8其中AndroidApp和R8内的实现是一样的,会根据当前的Android Sdk版本以及需要检查的文件先去生成AppView,然后我们基于这个AppView内的appView.appInfo().classes(),之后遍历展开,判断当前apk中是否含有一些非法的函数调用。
这种检测方式的可以完全模拟出apk实际安装情况下的一些函数调用情况,包括android源代码内的。一般的字节码访问之后生成的函数调用信息是难以模拟出安卓源代码内的api的,而且一些lambda因为脱糖后置,可能也会产生一系列的问题。
而且R8作为一个apk方法优化工具,他原始提供的功能会比我们自己写的更合理和靠谱,同时R8阶段中已经完成了脱糖,并转化成了dex。所以我们认为可靠性更高,这个也就是我们快编的最后一道屏障。
我们会将这个屏障设置在gitlab ci的pipeline中,如果A8检查没有通过代码是不允许被合入的。
Faster
在快编的基础上,我们还是希望工程能有更快的编译速度。我们当前采用了云端编译,独立的编译单元以及后续打算在编译单元的基础上构造独立的application壳工程来优化我们的编译速度。
在内部碰撞的过程中,有过一些对于编译优化的设想,可以将选择权交还给开发同学,让他们主动来选择当前的开发模式,是只对自己当前的模块负责,还是一些全局性的改动。在不同的模式下他们可以选择打开不同的工作路径,更快速的切换开发模式。
当前工程有大量的复合构建逻辑,而复合构建就是将多个本来完全独立的工程结构进行组合编译。每个业务都是一个独立的Gradle Project,都具有一个settings.gradle文件,所以他们天生就具有独立打开以及编译的条件,但是因为内部依赖是源代码,还是需要组合多个复合构建。在这个前提的基础上,也就诞生了在当前模式下更独立的编译单元。
云编译
云编译的工作就是将本地的所有变更内容和上一个babel commit进行计算,之后将变更的内容传输到远端打包机,然后依托于远端的编译缓存和远端更牛的机器进行打包工作,等打包完成之后再将apk传输回本地之后安装到手机中。

云编译系统则不同于ci,可以保留当前的build cache。平均的打包速度会更加快一点,大概是3min左右。另外一个优化点是获取工程结构能缓存的话,当分支没有变化的情况下直接使用缓存数据,优化完这部分应该能更快。
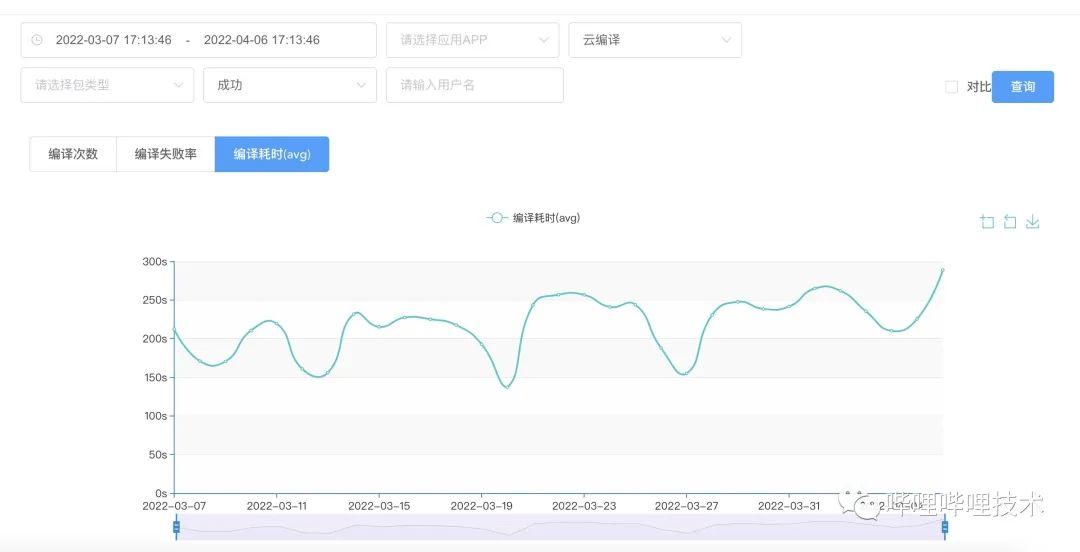
云编译的情况下平均的编译速度会比快编更加快一点,大概是3min。
独立的编译单元
当全源代码展开的时候,工程的同步速度会变得非常的慢,当前工程有500+的模块以及19个复合构建,一次同步大概需要消耗半个小时左右的时间。并且当切换分支都需要重新同步工程,这个也是当前迫切需要解决的问题。对比了下单仓和多仓的优劣,多仓模式下的一个优势就是工程依赖都是aar依赖,工程可以独立编译并运行起来。这也是单仓所缺少的能力,那么有没有办法将单仓也具有类似的能力呢?
基于前面的快编原理,可以挑选出当前切片下所依赖的模块的aar产物。接下来我们要做的就是让每一个业务或者sdk等等具有可以独立打开的能力就行了。
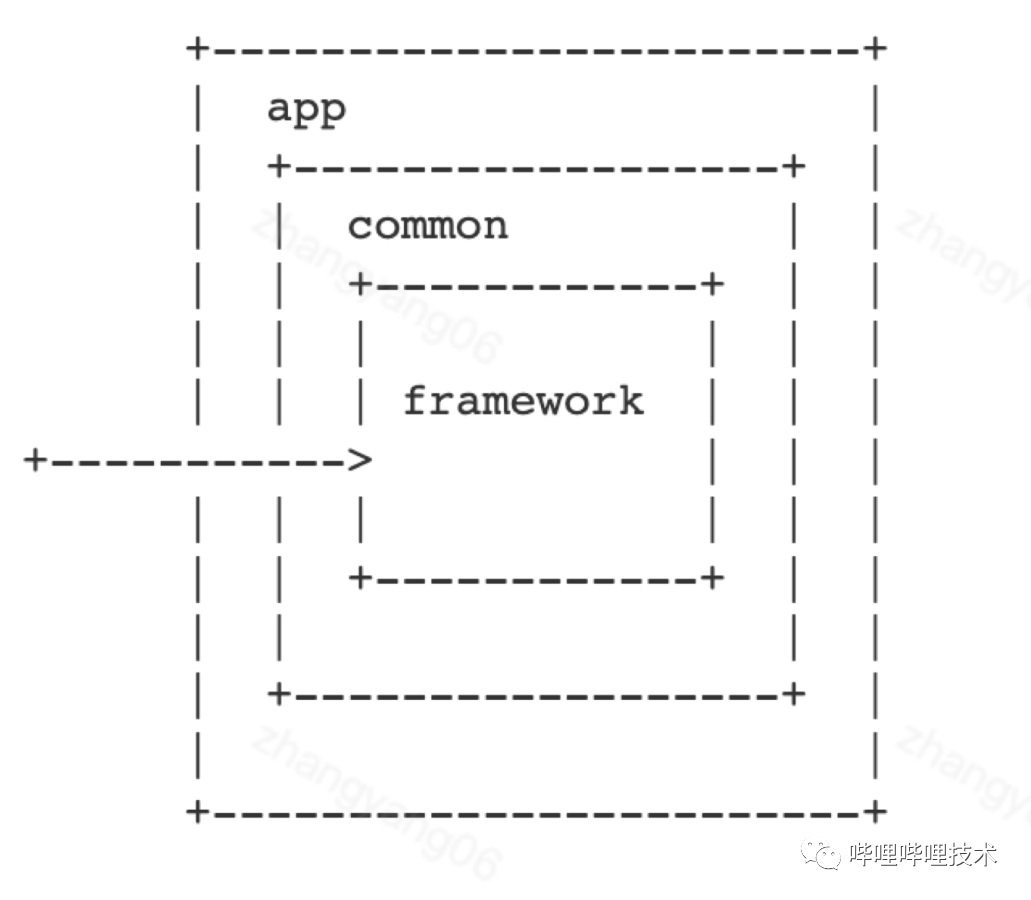
另外我们的工程结构上也将基础层,中间层等都进行了独立拆分,一个业务模块 + common + framework 就是一个完全可以独立编的工作单元。
所以只需要把快编插件添加点简单的逻辑,生成一个子模板的插件。之后将插件引入到这个独立工程的settings.gradle下。为了不影响独立工程的逻辑,这个插件只有在当前工程作为root节点的情况下生效。
if (gradle.parent == null) {
apply plugin: "fawkes.fast.build.sub.settings"
}
在这个工程目录下的添加一个saints_row的文件,之后在插件内反序列化数据结构,基于这个结构来决定后续的编译单元属性,展开的目录结构,以及编译模式等等。
info: - path: "framework" src: false - path: "common" src: true mode: "aarOnly"
其中我们可以通过src来任意关闭其中的一个工程进行重新同步索引,工程关闭情况下依赖会被替换成快编的aar version。然后我们也设立了三种完全不同的模式,来辅助业务同学进行日常的开发工作。
- normal 基础模式 全部源代码展开。
- aarOnly 引用快编的原理,将没有变更的模块变成aar,变更的模块切换到源码。
- owner 将自己作为owner的工程源代码展开,其他的和aarOnly一致。
一般情况下,开发同学只需要更改自己业务代码就行了,所以他们可以将自己不需要的模块直接切换成aar,这样的同步速度对他们来说是最快的,所以我们把默认模式都切换成aarOnly模式。
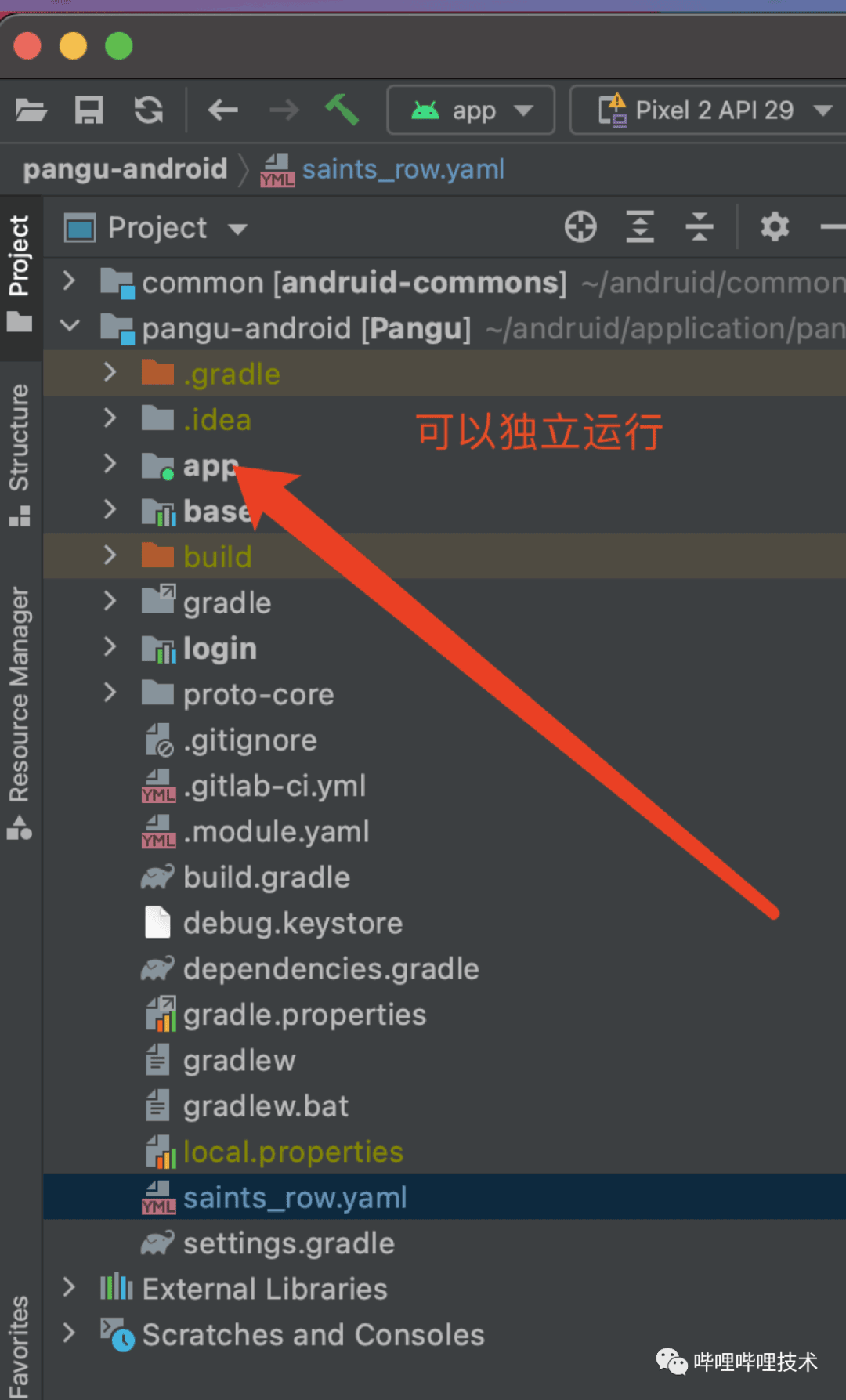
另外我们只是在原始的工程结构下,开辟出了独立的编译单元,因为Android Studio打开的路径不同,则选择的模式就会出现差异,所以他并不会实际影响到当前的工程结构。

通过这两张数据对比图,可以看出我们在同步的时间上,是有非常大的数据提升的。在这种模式下,可以让工程找到相对准确的aar版本,展开模块数量变少,编译和同步速度也就能更快的。对于开发来说,他也只需要对自己的业务代码负责。
展望
后续我们计划和自动化初始化框架进行配合,在每个可单独打开的工程下都生成好一个壳工程,让业务同学可以更快速感知到当前代码的变更并进行调试。然后通过idea插件,或命令行工具可以快速的生成这个壳工程。这个插件后续也能跟随着b站的工程迭代而持续更新,提供更多更便利的功能给到开发同学。
我们的任务就是提供更多的可能性,更多的便利性,将选择的权利交给业务同学。让他们能在大仓的模式下快速稳定的开发下去,可以选择大仓,也可以选择自己业务的独立编译路径。
结语
我们是如何做编译优化的,到这里已经聊得差不多了。项目中还有很多东西是可以继续进行优化的。比如说文件访问速度,编译缓存,将工程粒度更细化,更多idea插件,快速帮开发定位代码等等。
B站在单仓的路上其实已经走了很多年了,也碰到了很多的挑战和问题,我们甚至一度想要放弃这种模式。但坚持下来之后,我们还是认为单仓的优点是要大于多仓的。作为开发同学,我们更多的时候应该迎接挑战,然后思考如何去战胜这些问题,更多关于哔哩哔哩Android编译优化的资料请关注我们其它相关文章!
相关推荐
-

Android项目开发常用工具类LightTaskUtils源码介绍
目录 LightTaskUtils概述 LightTaskUtils截图 LightTaskUtils源码 版权声明 本文原创作者:谷哥的小弟 作者博客地址:http://blog.csdn.net/lfdfhl LightTaskUtils概述 LightTaskUtils是一个轻量级的线程管理工具. LightTaskUtils截图 LightTaskUtils截图如下: LightTaskUtils源码 LightTaskUtils源码如下: import android.os.Handl
-
Android Gradle同步优化详解
目录 动态修改gradle配置 hook agp ProjectsServices 方法签名检查是否存在support包 年初开始我们就开始了关于Gradle Sync阶段的优化.之前和大家都简单的介绍过工程相关的背景情况了,我们大概有400+的Module,然后一次的同步时间就非常的慢,我们迫切的需要对这个问题进行优化.大部分工作都是和团队内的同学一起完成的,我也只出了一点点力而已. 这次写文章真的很倒霉,之前忘了保存导致要重新开始写了.如果不是白嫖了掘金的端午礼盒,拿人手短啊,我已经打算鸽了
-
Android MonoRepo多仓和单仓的差别理论
目录 前言 什么是Monorepo 什么是multi-repo multi-repo的问题 multi-repo的优点 MonoRepo的缺点 MonoRepo的优点 前言 今天不打算展开任何关于技术的探讨,只是想抛出一些观点,关于工程结构上的.可能有些人赞成也有些人反对,但是我觉得技术的世界还是需要一些讨论和探索的. 并没有指明那些就是最优解,可能都只是一些个人观点而已. 两种模式其实我都略微有点接触,当然文章也存粹是个人观点.我们先看下下面这幅图,其实就是一个原始工程结构,分仓结构,还有单仓
-
Android实现Tab切换界面功能详解
目录 一.实验目的 二.实验任务 三.实验内容与要求 四.实现效果 五.代码实现 六.实验总结 一.实验目的 1. 掌握各种高级UI控件的基本使用: 2. 能够实现Tab切换效果. 二.实验任务 1. 根据原型图设计界面: 2. 实现Tab切换: 三.实验内容与要求 3.1 界面设计: (1)使用线性布局实现界面的基本布局: (2)使用不同的Tab实现方式实现tab的布局. 3.2 Tab切换 (1)监听Tab变化事件: (2)切换对应的页面内容: 四.实现效果 显示界面 隐藏界面 移除界面 五
-
哔哩哔哩Android项目编译优化
目录 背景 编译优化 工作流程 快编插件 获取工程树结构 version版本 源码orAAR 主动Skip模块 Configuration策略 远端upload R8 class check Faster 云编译 独立的编译单元 展望 结语 背景 哔哩哔哩的安卓项目的工程结构是Monorepo(单仓)变种,也就是所有的代码都在一个工程结构下编译.我们认为Monorepo(单仓)是一个非常适合我们的开发模式,主要是因为其提供的原子提交,可见性,参与度,切片的稳定性等等优点,这些都是我们选择Mono
-
用于cocos2d-x引擎(ndk)中为android项目生成编译文件列表
复制代码 代码如下: package com.leeass.generate; import java.io.File;import java.io.FileFilter;import java.io.FileNotFoundException; /** * 用于cocos2d-x引擎中android项目编译文件列表生成 * @author leeassamite * */public class GenerateAndroidMakefile { /** 分隔符 */ private stat
-
优化Vue项目编译文件大小的方法步骤
与其说是优化 Vue,不如说主要是在 webpack 打包的配置中做些文章,使得 Vue 编译后的文件尽可能的小.以下介绍自己在项目中进行优化的过程,其中的内容也许并不适合于每个项目,但整体思路是差不多的. 定位问题 要想进行优化,首先我们得清楚问题所在.即:是哪些代码/依赖包导致最后的编译文件过大? 这里,我们需要使用 webpack-bundle-analyzer 工具.修改 package.json 文件,添加: "analyze": "NODE_ENV=product
-
Vue项目打包编译优化方案
1. 不生成.map文件 默认情况下,当我们执行 npm run build 命令打包完一个项目后,会得到一个dist目录,里面有一个js目录,存放了该项目编译后的所有js文件. 我们发现每个js文件都有一个相应的 .map 文件,它们仅是用来调试代码的,可以加快打包速度,但会增大打包体积,线上我们是不需要这个代码的.这里我们需要配置不生成map文件. vue-cli2 config/index.js文件中,找到 productionSourceMap: true 这一行,将 true 改为 f
-
常见Android编译优化问题梳理总结
目录 编译常见问题 踩坑1 踩坑2 编译常见问题 在开发过程中,有碰到过一些由于编译优化导致的代码修改并不符合我们预期的情况.这也就是之前为什么我经常说编译产物其实是不太可以被信任的. 方法签名变更,底层仓库的方法变更但是上层模块并没有跟随一起重新编译导致的这个问题. 常量优化,将一些常量的调用点直接替换成常量的值. 删除空导包, 没有用的一些导包就会做一次剔除. 踩坑1 我们最近碰到一个 pipeline 相关而且很妖怪的问题.我们一个 pipeline 会检查apk产物中是否存在异常的方法调
-
Jenkins使用Gradle编译Android项目详解
创建项目 在主界面的左侧菜单选 新建 在向导中选择 输入项目名称,类型选择 构建一个自由风格的软件项目 点确定进入项目的配置界面 源码管理 选择git Repository URL输入项目路径 比如 https://git.coding.net/coderstory/Mi-Purify.git Credentials是对应的账户密码 点击add按钮添加github账户密码 Branch Specifier 是选择具体的分支 默认是master 在构建大类中 勾选Invoke Gradle [不知
-
哔哩哔哩在Hilt组件化的使用技术探索
目录 前言 接入Hilt Hilt在组件化 出现了点小问题 总结 前言 DI(Dependency Injection),即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中.依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活.可扩展的平台.通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现. 最近业务同学需要接入
-
Android项目基本结构详解
一.简介 第3章虽然通过百度地图应用展示了你可能感兴趣的内容,但是,如果你是一个初学者,一开始就看懂和理解代码可能会非常费劲.为了解决此问题,从这一章开始,本模块将从最基本的内容讲起,带你逐步进入用C#进行Android应用开发的乐园. 二.AndroidApp入口 要用C#开发Android应用程序,首先需要对项目的基本结构有一个感性认识.如下图所示: Android应用程序使用的是单一入口,源程序中并不能一眼看出程序从哪开始运行,当应用程序加载到内存中时,Android操作系统会自动从内部自
-
用Eclipse搭建Android开发环境并创建第一个Android项目(eclipse+android sdk)
一.搭建Android开发环境 准备工作:下载Eclipse.JDK.Android SDK.ADT插件 1.安装和配置JAVA开发环境: ①把准备好的Eclipse和JDK安装到本机上(最好安装在全英文路径下),并给JDK配置环境变量,其中JDK的变量值为JDK安装路径的根目录,如我的为:D:\Program Files\Java\jdk1.7.0_02: ②打开命令提示符(cmd),输入java -version命令,显示如下图则说明JAVA环境变量已经配置好了. 2.安装ADT插件: ①