SQL删除重复数据的实例教程
目录
- 1 SQL去重
- 2 distinct
- 3 group by
- 1. 查询根据名字去重后数据(名字相同取id值大的)
- 2. 删除名字相同数据(名字相同保留id值大的)
- 4 总结
1 SQL去重
SQL中去除完全相同数据可以用distinct关键字,任意字段去重可以用group by,以下面的数据表为例。
2 distinct
存在两条完全相同的纪录,用关键字distinct就可以去掉
根据单个字段去重,能精确去重;
作用在多个字段时,只有当这几个字段的完全相同时,才能去重;
关键字distinct只能放在SQL语句中的第一个,才会起作用
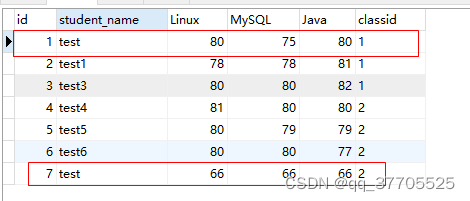


一般用来返回不重复的记录条数,返回不重复的条数(去掉test重复的,就剩下6条)

3 group by
1. 查询根据名字去重后数据(名字相同取id值大的)
SELECT * FROM stu WHERE id IN (SELECT MAX(id) FROM stu GROUP BY `name`)

2. 删除名字相同数据(名字相同保留id值大的)
group by + count + max去掉重复数据
1)SELECT * FROM stu

2)加上group by 后,会将重复的数据去掉了

3) 条件(名字)是数量大于1的重复数据
SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`) > 1 #条件是数量大于1的重复数据 SELECT * FROM stu WHERE `name` IN( SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`)>1 )

4)查看某字段重复数据的id
SELECT id, COUNT(*) FROM stu GROUP BY NAME DESC HAVING(COUNT(*) > 0)
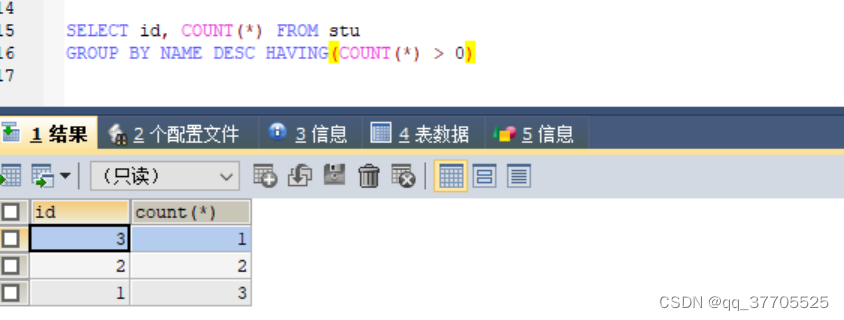
5)查询所有重复数据
SELECT * FROM stu WHERE NAME IN (SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`) > 1)

5) 去重
可以使用distinct去重(返回不重复的用户名)
删除多余的重复记录(name),只保留id最大的记录。
DELETE FROM stu WHERE id NOT IN ( SELECT a.id FROM ( SELECT MAX( id ) AS id FROM stu GROUP BY `name` )a )
或者
DELETE FROM stu WHERE `name` IN (SELECT `name` FROM (SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`)>1) e) AND id NOT IN (SELECT id FROM (SELECT MAX(id) AS id FROM stu GROUP BY `name` HAVING COUNT(`name`)>1) t) #查询显示重复的数据都是显示最前面的几条,因此不需要查询是否最小值
错误删除
DELETE FROM stu WHERE name IN (SELECT name FROM stu GROUP BY name HAVING COUNT(name)>1)
AND id NOT IN (SELECT MAX(id) FROM stu GROUP BY stu HAVING COUNT(name)>1)
原因是:不能将直接查处来的数据当做删除数据的条件,我们应该先把查出来的数据新建一个临时表,然后再把临时表作为条件进行删除功能
4 总结
去重后名字记录
SELECT `name` FROM stu GROUP BY NAME HAVING(COUNT(*) > 0)
2)
所有重复名字的记录
SELECT `name` FROM stu GROUP BY NAME HAVING COUNT(*) > 1
3)把所有重复的记录都删了
DELETE FROM stu WHERE
nameIN
(SELECTnameFROM stu GROUP BYnameHAVING COUNT(*)>1)

无法在删除时同时查询这张表,这个问题只在MySQL中出现,oracle没有。怎么解决?我们只需要在查出结果以后加一张中间表。让执行器认为我们要查的数据不是来自正在删的这张表就可以了。
DELETE FROM stu WHERE `name` IN
(SELECT a.name FROM
(SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(*)>1) a)
所有重复数据都删除, 就剩王五一条数据了

4) 现在删除所有重复数据数据做完了,考虑怎么保留重复数据中id最小的。只需要在删除时让删除该条的记录id不在重复数据id最小的当中就可以了。
DELETE FROM stu WHERE `name` IN
(SELECT a.name FROM
(SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(*)>1) a)
AND id NOT IN
(SELECT b.id FROM
(SELECT MIN(id) id FROM stu
GROUP BY `name` HAVING COUNT(*)>1) b);

还有简单办法 算出去重后所有数据(保留最小ID),然后删除id不在该数组里的
DELETE FROM stu WHERE id NOT IN (SELECT t.id FROM (SELECT MIN(id) AS id FROM stu GROUP BY `name`)t)
到此这篇关于SQL删除重复数据的文章就介绍到这了,更多相关SQL删除重复数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
有用的SQL语句(删除重复记录,收缩日志)
删除重复记录,将TABLE_NAME中的不重复记录保存到#TABLE_NAME中 select distinct * into #table_name from table_name delete from table_name select * into table_name from #table_name drop table #table_name 与此相关的是"select into"选项,可以在数据库属性 对话框中,勾起来此项,或者在Query Analyzer中执行 ex
-
MySQL中查询、删除重复记录的方法大全
前言 本文主要给大家介绍了关于MySQL中查询.删除重复记录的方法,分享出来供大家参考学习,下面来看看详细的介绍: 查找所有重复标题的记录: select title,count(*) as count from user_table group by title having count>1; SELECT * FROM t_info a WHERE ((SELECT COUNT(*) FROM t_info WHERE Title = a.Title) > 1) ORDER BY Titl
-
sql删除重复数据的详细方法
一. 删除完全重复的记录 完全重复的数据,通常是由于没有设置主键/唯一键约束导致的.测试数据: 复制代码 代码如下: if OBJECT_ID('duplicate_all') is not nulldrop table duplicate_all GO create table duplicate_all ( c1 int, c2 int, c3 varchar(100) ) GO insert into duplicate_all select 1,100,'aaa' union allse
-
SQL重复记录查询 查询多个字段、多表查询、删除重复记录的方法
SQL重复记录查询 1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) 例二: select * from testtable where numeber in (select number from people group by numbe
-
mysql查找删除重复数据并只保留一条实例详解
有这样一张表,表数据及结果如下: school_id school_name total_student test_takers 1239 Abraham Lincoln High School 55 50 1240 Abraham Lincoln High School 70 35 1241 Acalanes High School 120 89 1242 Academy Of The Canyons 30 30 1243 Agoura High School 89 40 1244 Agour
-
SQL 查询和删除重复字段数据的方法
例如: id name value 1 a pp 2 a pp 3 b iii 4 b pp 5 b pp 6 c
-
mysql删除重复记录语句的方法
例如: id name value 1 a pp 2 a pp 3 b iii 4 b pp 5 b pp 6 c pp 7 c pp 8 c iii id是主键 要求得到这样的结果 id name value 1 a pp 3 b iii 4 b pp 6 c pp 8 c iii 方法1 delete YourTable where [id] not in ( select max([id]) from YourTable group by (name + value)) 方法2 delet
-
SQL语句实现删除重复记录并只保留一条
复制代码 代码如下: delete WeiBoTopics where Id in(select max(Id) from WeiBoTopics group by WeiBoId,Title having COUNT(*) > 1); SQL:删除重复数据,只保留一条用SQL语句,删除掉重复项只保留一条在几千条记录里,存在着些相同的记录,如何能用SQL语句,删除掉重复的呢 1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 复制代码 代码如下: select * fr
-

SQL删除重复数据的实例教程
目录 1 SQL去重 2 distinct 3 group by 1. 查询根据名字去重后数据(名字相同取id值大的) 2. 删除名字相同数据(名字相同保留id值大的) 4 总结 1 SQL去重 SQL中去除完全相同数据可以用distinct关键字,任意字段去重可以用group by,以下面的数据表为例. 2 distinct 存在两条完全相同的纪录,用关键字distinct就可以去掉 根据单个字段去重,能精确去重; 作用在多个字段时,只有当这几个字段的完全相同时,才能去重; 关键字distin
-
mysql数据库删除重复数据只保留一条方法实例
1.问题引入 假设一个场景,一张用户表,包含3个字段.id,identity_id,name.现在身份证号identity_id和姓名name有很多重复的数据,需要删除只保留一条有效数据. 2.模拟环境 1.登入mysql数据库,创建一个单独的测试数据库mysql_exercise create database mysql_exercise charset utf8; 2.创建用户表users create table users( id int auto_increment primary
-
Mysql删除重复数据并且只保留一条(附实例!)
(1)以这张表为例: CREATE TABLE `test` ( `id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '注解id', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '名字', PRIMARY KEY (`id`) USING BTREE ) ENGI
-
SQL删除重复的电子邮箱力扣题目解答流程
目录 写在前面 SQL题目概述 解题思路 方法实现 代码测试 知识点小结 1.内连接innerjoin(join默认就是内连接) 2.左外连接leftjoin 3.右外连接rightjoin 4.全外连接fulljoin 写在前面 想要掌握好SQL,那少不了每天的练习与学习.接下来小梦会带领小伙伴们一起每天刷一道LeetCode-数据库(SQL)相关的题目,然后在文章后例举相关知识点帮助小伙伴们学习与巩固,更好的掌握SQL. ♂️ 小伙伴们如果在学习过程中有不明白的地方,欢迎评论区留言提问,小
-
Mysql 删除重复数据保留一条有效数据(最新推荐)
目录 Mysql 删除重复数据保留一条有效数据 一.Mysql 删除重复数据,保留一条有效数据 二.Mysql 删除重复数据(多个字段分组) 三.Mysql 查询出可以删除的重复数据 补充:mysql删除重复记录并且只保留一条 MySql如何删除所有多余的重复数据 需要处理的数据,如: Mysql 删除重复数据保留一条有效数据 一.Mysql 删除重复数据,保留一条有效数据 DELETE FROM SZ_Building WHERE id NOT IN ( SELECT t.min_id FRO
-
oracle 删除重复数据
重复的数据可能有这样两种情况,第一种: 表中只有某些字段一样,第二种是两行记录完全一样. 一.对于部分字段重复数据的删除 1.查询重复的数据 select 字段1,字段2, count(*) from 表名 group by 字段1,字段2 having count(*) > 1 例:Select owner from dba_tables group by owner having count(*)>1; Select owner from dba_tables group by owner
-
Mysql删除重复数据保留最小的id 的解决方法
在网上查找删除重复数据保留id最小的数据,方法如下: DELETE FROM people WHERE peopleName IN ( SELECT peopleName FROM people GROUP BY peopleName HAVING count(peopleName) > 1 ) AND peopleId NOT IN ( SELECT min(peopleId) FROM people GROUP BY peopleName HAVING count(peopleName) >
-
MySQL中删除重复数据的简单方法
MYSQL里有五百万数据,但大多是重复的,真实的就180万,于是想怎样把这些重复的数据搞出来,在网上找了一圈,好多是用NOT IN这样的代码,这样效率很低,自己琢磨组合了一下,找到一个高效的处理方式,用这个方式,五百万数据,十来分钟就全部去除重复了,请各位参考. 第一步:从500万数据表data_content_152里提取出不重复的字段SFZHM对应的ID字段到TMP3表 create table tmp3 as select min(id) as col1 from data_content