JavaScript架构前端不能没有监控系统原因
目录
- 监控系统
- 前端监控具体能解决什么问题?
- 异常报错问题
- 性能检测问题
- 运营反馈工具
- 为什么要选择自研?
- 自研前端监控的技术栈
监控系统
提到监控系统,大部分同学首先想到的是后端监控。很明显,比如检测服务器性能,数据库性能,API 的访问流量,以及各种服务的运行情况等等,都与后端息息相关。而前端更多承担的是 UI 展现的角色,主要关注页面怎么排版设计,好像没什么需要监测的地方,因此一直以来都没有涉及到监控的概念。
于是呢大家就一致认为:只要后端稳定可控,应用就是稳定可控的,可实际情况真的是这样吗?
近年来,前端发展日益迅猛,得益于 JavaScript 的持续进化和浏览器功能的不断增强,前端能做到的事情越来越多,相应的前端应用的复杂度也越来越高。以前我们压根不会遇到的问题,现在蹭蹭蹭的一股脑都冒出来了。
举个例子,小明是个前端程序员,有一天用户反馈某页面某按钮点了没有反应。小明立刻找到那个按钮,轻轻一点,咦?正常的呀。然后小明又用了几个不同的账号测试,依然是正常的。这下可把小明难倒了。
怎么办?我相信全天下的前端程序员们遇到奇怪问题的反应是一样的。小明这样告诉用户:可能是浏览器缓存问题,不行强制刷新一下,或者退出登录试试? 用户按照小明的建议操作一番,果然奏效!于是给小明发来了一连串的“感谢 ”。小明尴尬一笑,连忙回复“小意思”。
过了两天,又有一个用户反馈了同样的问题。小明又祭出了上面的万能解决大法,依然奏效。可是问题真的解决了吗?没有啊!然而小明尝试过很多遍都无法复现异常,可能原因有很多,比如:
- 数据问题,可能取不到某个属性
- 前端问题,JS 代码执行异常
- 接口问题,可能接口无响应,或没有返回预期的值
然而正常情况下是没有问题的,小明多次测试也都正常,一定是在某种特定场景下才会出现这个问题,但是我们无法判断,捕捉不到。
像这类 Bug 潜伏在我们的系统中,仿佛地雷一样,指不定什么时候就会爆。最尴尬的是即便它爆了我们也很难发现,这就导致我们的“排雷行动”困难重重。
某个阳光明媚的下午,小明坐在马桶上思考人生。突然脑海中一道灵光闪过,小明想到:“如果在用户触发异常的那一刻,系统能自动获取到异常的数据并保存起来,然后在后台的某个地方能看到这些数据,我不就可以立刻找到错误原因了吗?”
小明一拍大腿,对呀!我怎么没有早点想到呢?这样的话,只要发生异常我们就能自动捕获到异常数据,如果再遇到线上报错,我们不需要用户反馈,自己就可以发现,而且能马上定位错误原因,这不是一举两得?
我相信许多前端前辈们也曾经被上述的问题所困扰,然后也像小明一样,慢慢的有了这个思路:“将报错时的异常数据存下来供后续排查”。在这个思路不断实践的过程中,逐渐演变成了今天的前端监控。
当然了,今天的前端监控并不仅仅是监控异常数据,任何有利于产品分析的数据都可以加入监控。所以我认为前端监控,就是指采集用户使用系统过程中产生的关键数据,存储到数据库,后续可以查找和分析,这样的整套实现就被称为前端监控系统。
前端监控具体能解决什么问题?
上面用一个例子推导出前端监控出现的背景,粗略的说了下它如何追踪线上报错问题,大家应该初步了解了前端监控的意义。现在我们把目光聚焦在项目上,再详细探究一下它具体能解决哪些问题。
异常报错问题
首先就是异常报错的问题。就如例子中的场景一样,线上发生异常,有时候我们难以复现,甚至如果没有用户反馈,我们都不知道有这个问题,这样就给用户传递了一种我们的产品很不稳定的感觉。因此前端监控是线上产品稳定和异常及时反馈的非常关键的保障。
当然了,除了前端的异常,我们同样可以捕获 接口异常。有的时候前端程序员们自嘲自己是“背锅侠”,产品,测试,用户,遇到问题首先找前端,不管是不是前端的问题,前端先顶,再花时间定位错误。有的时候领导脾气不好,上来先劈头盖脸一顿骂,卑微前端也不敢说话,因为啥问题得排查后才清楚,结果排查完后是接口的问题,白挨了一顿骂,心里就非常不爽。
但是如果有了前端监控,我们就能马上拿到异常发生时的错误信息,页面,地址,参数等,什么问题一查便知。下一次遇到线上事故,前端就可以从容不迫客观公正的说这是哪一方的问题。如果遇到甩锅行为,前端也能勇敢说不,毕竟我证据在手,岂容你说吼就吼?
性能检测问题
追踪异常是前端监控最实用的地方,但不光如此,性能监控 也是非常关键的部分。
当下的前端工程体量很大,如果代码质量不高,或者项目架构设计不合理,很容易遇到性能问题。性能问题比如首屏加载时间,页面是否卡顿,白屏,资源重复请求等,可以通过数据采集,比如计算渲染时间,请求接口数量,请求资源总量等,对某个页面进行监控,及时发现性能问题。
那么除了可以“解决问题”,前端监控还有哪些价值?
运营反馈工具
其实前端监控除了可以帮助程序员不断优化和完善应用,对产品和运营同学有同样不可或缺的作用。具体来说就是通过“埋点监控”来收集用户的行为数据,则可以对线上产品的使用情况作出统计分析,比如整体的 PV/UV,某个功能的访问量,访问时段,点击率等等数据。这些数据可以帮助产品和运营了解实际情况,进而改进产品功能。
这些行为数据的收集,可以非常精准的描绘出某个功能或者某个人的实际使用情况。当然采集的数据量也要比异常数据大的多。相比来说,异常监控是只有发生异常才会收集数据,而行为数据则是,只要用户使用我们的产品,与产品发生交互,理论上这些数据都要收集起来。
当然监控是多方面的,收集哪些数据视情况而定。总之你想了解产品的任何情况,都可以通过设计采集规则然后收集数据来实现,这方面是非常灵活的,并不仅仅限于大家熟知的那几个指标。
为什么要选择自研?
前端监控发展到现在,必然会有成熟的第三方平台。目前国内最常用的有三个:
- sentry
- webfunny
- fundebug
首先 sentry 和 fundebug 这两个平台是付费的,而且你的数据越多费用越高,相当于是数据托管平台。webfunny 虽然可以私有化部署,但是它的功能是固定的,没法改代码,这就是它的缺点:不够灵活,无法定制功能。
所以目前虽然市面上已经有成熟的监控系统,但依然有很多团队选择自研。一是数据可以保存在自己的服务器上,不用另外花钱;二是灵活性强,可以自定义功能,比如你可以在触发异常时,接入自己的钉钉或企业微信消息推送,这就需要你的监控系统灵活性很高。
还有我们上面说的,自定义采集规则。我认为这个是最重要的原因。不同规则采集到的数据不一样,因此第三方标准的采集规则可能并不符合你公司的需求。比如有的公司需要获取设备标识作为唯一 ID,有的公司却需要用户标识。这是由业务决定的,每个公司都不一样。
我司前端组就是自研前端监控平台。优势就是可以自定义自己的采集规则,设计自己的数据库存储字段,数据都保存在自己的平台,灵活性和可靠性都非常高,能满足自己的多样性需求。
自研前端监控的技术栈
先上结论,我司的前端监控是前端组自己搞的,所以技术栈是 React + Node.js + MongoDB。
这是一个比较常规的技术方案,前端自己搞嘛,所以技术栈都以 JS 为主。同时这也是前端比较能琢磨明白的东西,算是一个标准方案吧。
其中,Node.js 部分我们使用 express 框架写接口,接口总体分两大类,就是 写入 和 查询统计,作用呢就是前端采集到数据之后,要通过调用接口存储。之后在监控面版上,也要通过接口将数据查询展现出来。
接口的背后就是 MongoDB 数据库,作用就是存储我们采集到的数据。为什么选择 MongoDB 呢?最主要的原因就是它的写入性能非常高,写入速度非常快。上面我们说,监控系统在采集行为数据的时候,写入非常频繁,那么对写入性能的要求就非常高,反观查询反而要求不那么高。
这里也有比较难啃的点,就是采集到大量的数据之后,我们需要各个维度的统计分析。比如:
- 某个时间段用户的访问次数和访问时长排行
- 某个时间段页面的访问频率和停留时间排行
- 某个时间段接口报错的次数以及占比统计
这些比较复杂的查询统计,主要用到 MongoDB 的聚合查询。前端写个基本的分组统计还行,这类复杂查询我们就捉襟见肘了。怎么办呢?我们用很长一段时间啃掉了 MongoDB 聚合查询的所有文档,按照需求一个一个找函数,看哪个能实现,几乎把所有聚合函数都翻了一遍。
接口做完,最后用 React 实现一个管理后台,将数据以图表,表格的形式展示出来,就可以实时看到线上产品的使用情况了。
当然还有一步,就是写一个对接钉钉或企业微信的通知接口,在触发异常的时候发起通知,让我们能及时知道异常情况。我们的通知是这样:
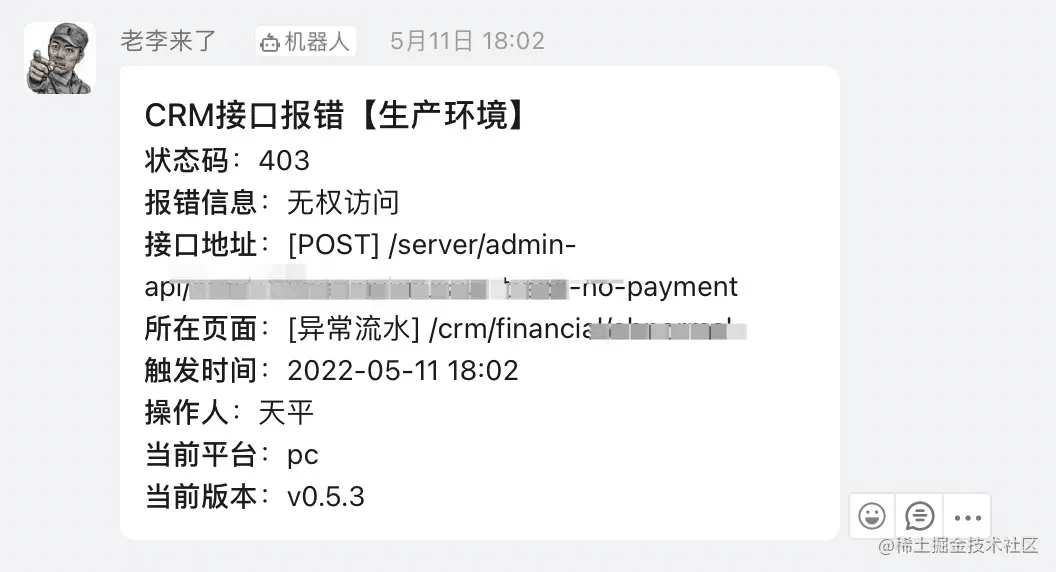
这个信息就能比较全面的看出来是哪里出了问题,如果看更详细的错误再去异常面板去找:
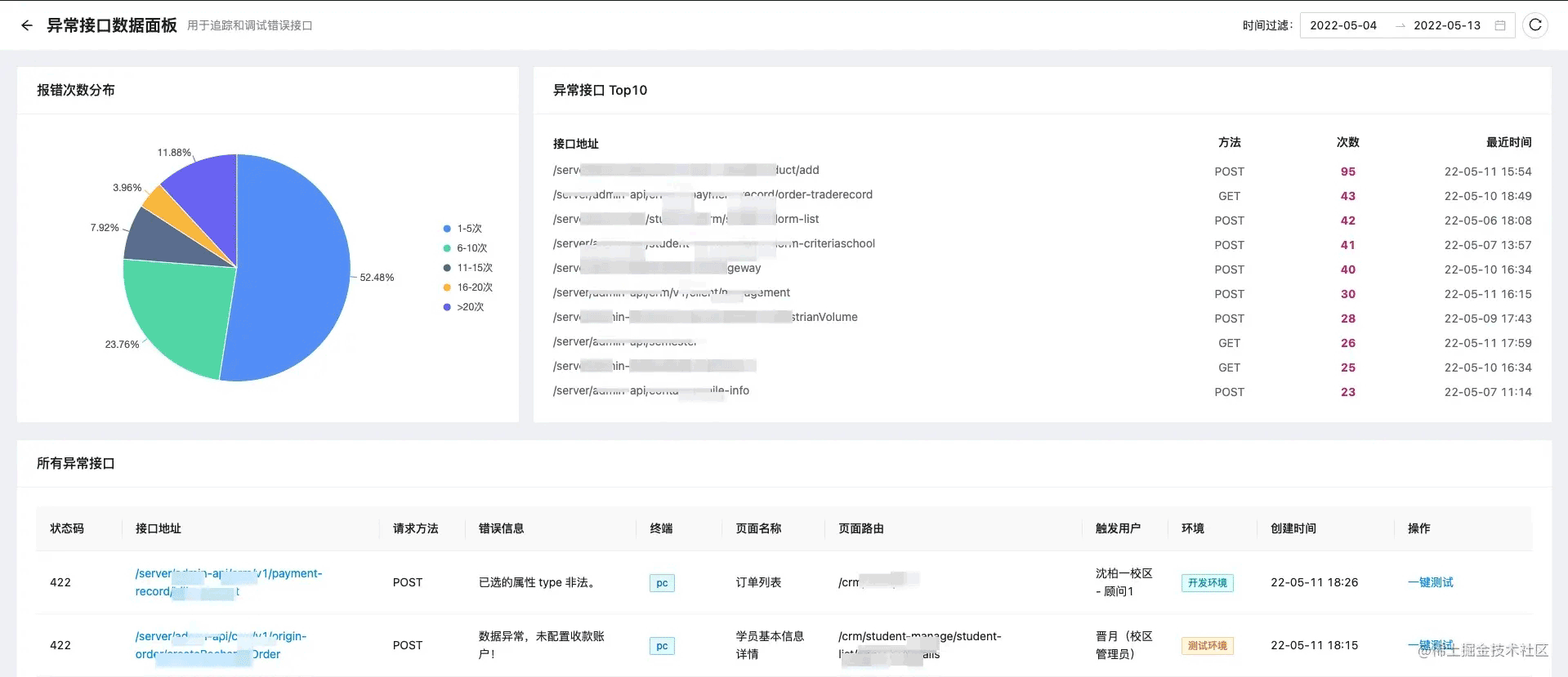
总之首先对接口异常全面监控,确认数据没问题之后我们再前端去排查,效率提高了,锅也少背了,这不是两全其美吗?
最后我们自研的这个小系统在产品上线后发挥了很大的作用,受到了老板的表扬,这样让我们受到了鼓舞,继续完善它~
更多关于前端监控系统的资料请关注我们其它相关文章!
相关推荐
-
Java 用Prometheus搭建实时监控系统过程详解
上帝之火 本系列讲述的是开源实时监控告警解决方案Prometheus,这个单词很牛逼.每次我都能联想到带来上帝之火的希腊之神,普罗米修斯.而这个开源的logo也是火,个人挺喜欢这个logo的设计. 本系列着重介绍Prometheus以及如何用它和其周边的生态来搭建一套属于自己的实时监控告警平台. 本系列受众对象为初次接触Prometheus的用户,大神勿喷,偏重于操作和实战,但是重要的概念也会精炼出提及下.系列主要分为以下几块 Prometheus各个概念介绍和搭建,如何抓取数据(本次分享内容)
-

C# 实现视频监控系统(附源码)
去过工厂或者仓库的都知道,在工厂或仓库里面,会有很多不同的流水线,大部分的工厂或仓库,都会在不同流水线的不同工位旁边安装一台电脑,一方面便于工位上的师傅把产品的重要信息录入系统,便于公司系统数据采集分析.另一方面严谨的工厂或仓库也会在每个工位上安装摄像头,用于采集或监控流水线上工人的操(是)作(否)习(偷)惯(懒). 好了,闲话少说,咱们直入主题吧! 本系统监控系统,主要核心是使用AForge.NET提供的接口和插件(dll),感兴趣的朋友也可以去他们官网查看文档http://www.aforg
-
.NET程序性能监控系统Elastic AMP的使用方法
目录 什么是Elastic AMP 工作原理 代码演示 1.新增Web项目 2.新增Nuget包 3.配置HttpModule 4.配置Agent 5.启动网站 Elastic APM核心模块 1.Transaction:我们通过Transaction可以看其中Api的调用信息 2. Dependencies:通过Dependencies看到服务依赖关系 3. Error: 能通过Error看到程序中的错误信息 4. Matrics: 可以通过Matrics看到服务气的内存与CPU信息 Elas
-
python实现的web监控系统
完整项目地址: https://github.com/zsjtoby/DevOpsCloud 欢迎使用极云监控系统 极云监控系统实现了跳板机应有的功能.基于ssh协议来管理,客户端无需安装agent. 支持常见系统: CentOS, RedHat, Fedora, Amazon Linux Debian SUSE, Ubuntu FreeBSD 其他ssh协议硬件设备 首页 WebTerminal: Web批量执行命令 录像回放 跳转和批量命令 命令统计 安装 cd /opt git clone
-
JavaScript架构前端不能没有监控系统原因
目录 监控系统 前端监控具体能解决什么问题? 异常报错问题 性能检测问题 运营反馈工具 为什么要选择自研? 自研前端监控的技术栈 监控系统 提到监控系统,大部分同学首先想到的是后端监控.很明显,比如检测服务器性能,数据库性能,API 的访问流量,以及各种服务的运行情况等等,都与后端息息相关.而前端更多承担的是 UI 展现的角色,主要关注页面怎么排版设计,好像没什么需要监测的地方,因此一直以来都没有涉及到监控的概念. 于是呢大家就一致认为:只要后端稳定可控,应用就是稳定可控的,可实际情况真的是这样
-
JavaScript架构前端监控搭建过程步骤
目录 前言 采集阶段:要采集哪些数据? 前端异常 接口异常 行为数据 API 阶段:搭建上报数据的 API 接口 数据存储阶段:接口对接数据库 查询统计阶段:数据查询和统计分析 可视化阶段:最终的数据图表展现 报警阶段:发现异常马上报警通知 部署阶段:万事俱备只等上线 总结 前言 上一篇介绍了,前端为什么要有监控系统?前端监控系统的意义何在?有小伙伴看完后留言想听些详细的实现.那么本篇我们就开始介绍前端监控如何实现. 如果还不明白为什么,搞监控有什么用,建议先看上篇文章:为什么前端不能没有监控系
-
JavaScript架构搭建前端监控如何采集异常数据
目录 前言 什么是异常数据? 接口异常 拦截器中捕获异常 前端异常 为啥不用 window.onerror ? 异常处理函数 处理接口异常 处理前端异常 获取环境数据 在 Vue 中 在 React 中 总结 前言 前两篇,我们介绍了为什么前端应该有监控系统,以及搭建前端监控的总体步骤,前端监控的 Why 和 What 想必你已经明白了.接下来我们解决 How 如何实现的问题. 如果不了解前端监控,建议先看前两篇: 为什么前端不能没有监控系统? 前端监控的总体搭建步骤 本篇我们介绍,前端如何采集
-
js前端埋点监控解析
一.为什么需要埋点&监控 在开始正文之前,我们先想想为什么需要埋点&监控? 当我们在分析复盘一个产品是否成功的时候,不同的角色考虑的方向是不同的. 站在产品的视角,经常会问如下几个问题: 1.产品有没有用户使用 2.用户用得怎么样 3.系统会不会经常出现异常 4.如何更好地满足用户需求服务用户 当站在技术视角时,经常会问如下几个问题: 1.系统出现异常的频率如何 2.异常出现后如何快速进行定位追踪 3.如何分析解决问题 而当站在老板的视角时,问题可能又会变为: 1.我的存量用户多少,未来还
-
GoLang日志监控系统实现
目录 日志监控系统 项目简答介绍 系统架构 读取模块具体实现 日志解析模块 日志监控系统 Nginx(日志文件) -> log_process (实时读取解析写入) -> influxdb(存储) ->grafana(前端日志展示器) influxdb 属于GO语言编写的开源的时序型数据,着力于高性能 查询与存储时序型数据,influxdb 广泛的应用于存储系统的监控数据,IOT行业的实时数据. 目前市面上流行 TSDB(时序型处理数据库):influxDB, TimescaleDB,
-
关于.NET/C#/WCF/WPF 打造IP网络智能视频监控系统的介绍
OptimalVision网络视频监控系统 OptimalVision(OV)网络视频监控系统(Video Surveillance System),是一套基于.NET.C#.WCF.WPF等技术构建的IP网络视频监控系统.设计与实现该系统的初衷是希望在家用电脑中部署该系统,连接本地或局域网设备,通过浏览器或手机客户端浏览宝宝实时视频,也就是俗称的"宝宝在线"或"家庭看护". 但由于业余时间总是有限,完成系统中的服务.配置.采集.传输和桌面GUI部分后,继续完成后续
-
Python写的一个简单监控系统
市面上有很多开源的监控系统:Cacti.nagios.zabbix.感觉都不符合我的需求,为什么不自己做一个呢 用Python两个小时徒手撸了一个简易的监控系统,给大家分享一下,希望能对大家有所启发 首先数据库建表 建立一个数据库"falcon",建表语句如下: CREATE TABLE `stat` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `host` varchar(256) DEFAULT NULL, `mem_free`
-
python实现内存监控系统
本文实例为大家分享了python实现内存监控系统的具体代码,供大家参考,具体内容如下 思路:通过系统命令或操作系统文件获取到内存信息(linux 内存信息存在/proc/meminfo文件中,mac os 通过命令vm_stat命令可以查看) 并将获取到信息保存到数据库中,通过web将数据实时的展示出来.(获取数据-展示数据) 1.后台数据采集(获取数据) import subprocess import re import MySQLdb as mysql import time import
-
eBay 打造基于 Apache Druid 的大数据实时监控系统
首先需要注意的是,本文即将提到的 Druid,并非阿里巴巴的 Druid 数据库连接池,而是另一个大数据场景下的解决方案:Apache Druid. Apache Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式时序数据库系统,旨在快速处理大规模的数据,并能够实现快速查询和分析.尤其是当发生代码部署.机器故障以及其他产品系统遇到宕机等情况时,Druid 仍能够保持 100% 正常运行.创建 Druid 的最初意图主要是为了解决查询延迟问题,当时试图使用 Hadoop 来实现交