c++快速排序详解
说一说快速排序
快速排序,实际中最常用的一种排序算法,速度快,效率高,在N*logN的同等级算法中效率名列前茅。·
基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分所有数据要小,然后再按此方法对这两部分数据分别进行快速排序。整个排序过程可以递归进行,以此达到整个数据变成有序序列。
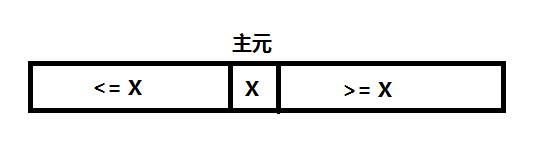
将数列变成上述形式,这一步很关键,做好这一步,才能对主元左右的部分进行递归调用。以下是实现这一部分的代码:
int partition_sort(int arr[],int l,int r)//l是数组最左边,r为最右边
{
int j=l;//设计标记
int t=arr[l];//设置主元
for(int i=l+1;i<=r;i++)
{
if(arr[i]<t){
swap(arr[j+1],arr[i]);
j++;
}
}
swap(arr[l],arr[j]);
return j;
}
上述代码中,我把最左边的元素当作主元,这样的代码对大多数排序都很高效,但是不排除个别情况(当数组近乎有序或者当数组内有大量重复元素),这时,我们的排序算法相比于归并排序显得并不是那么高效,这和我们的排序算法原理密不可分,细细分析,当数组近乎有序时,我们的快速排序竟然退化到了O(n^2)级别,这显然是非常不高效的。
要想实现上述不足的优化,我们可以将主元随机选择,或者采用其他方式的快速排序(双路快速排序,三路快速排序),本篇内容仅作为学习快排的基本思想和基本实现,不深入涉及,有兴趣的读者可查阅资料了解。
下面是全部的实现代码:
#include <iostream>
#include <math.h>
using namespace std;
//实现函数,用于partition的递归
int partition_sort(int arr[],int l,int r)//l是数组最左边,r为最右边
{
int j=l;//设计标记
int t=arr[l];//设置主元
for(int i=l+1;i<=r;i++)
{
if(arr[i]<t){
swap(arr[j+1],arr[i]);
j++;
}
}
swap(arr[l],arr[j]);
return j;
}
//实现递归的调用函数
void partition(int arr[],int l,int r)
{
if(l>=r)return ;
int p=partition_sort(arr,l,r);
partition(arr,l,p-1);
partition(arr,p+1,r);
}
int main()
{
int a[5];
for(int i=0;i<5;i++)
{
cin>>a[i];
}
partition(a,0,4);
for(int i=0;i<5;i++)
{
cout<<a[i]<<" ";
}
return 0;
}
相关推荐
-
C++ 先对数组排序,在进行折半查找
第一步:输入15个整数 第二步:对这15个数进行排序 第三部:输入一个数,在后在排好序的数中进行折半查找,判断该数的位置 实现代码如下: 方法一: 选择排序法+循环折半查找法 复制代码 代码如下: #include<iostream>using namespace std;int main(){ int a[15]; int n,i; void array_sort(int a[], int n); int zeban(int a[], int start ,int end,int n); c
-
C++快速排序的分析与优化详解
相信学过数据结构与算法的朋友对于快速排序应该并不陌生,本文就以实例讲述了C++快速排序的分析与优化,对于C++算法的设计有很好的借鉴价值.具体分析如下: 一.快速排序的介绍 快速排序是一种排序算法,对包含n个数的输入数组,最坏的情况运行时间为Θ(n2)[Θ 读作theta].虽然这个最坏情况的运行时间比较差,但快速排序通常是用于排序的最佳的实用选择.这是因为其平均情况下的性能相当好:期望的运行时间为 Θ(nlgn),且Θ(nlgn)记号中隐含的常数因子很小.另外,它还能够进行就地排序,在虚拟内存
-
C/C++实现快速排序的方法
快速排序不会直接得到最终结果,只会把比k大和比k小的数分到k的两边.(你可以想象一下i和j是两个机器人,数据就是大小不一的石头,先取走i前面的石头留出回旋的空间,然后他们轮流分别挑选比k大和比k小的石头扔给对面,最后在他们中间把取走的那块石头放回去,于是比这块石头大的全扔给了j那一边,小的全扔给了i那一边.只是这次运气好,扔完一次刚好排整齐.)为了得到最后结果,需要再次对下标2两边的数组分别执行此步骤,然后再分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果. -- 取自百度百科
-
c++实现对输入数组进行快速排序的示例(推荐)
废话不多说,直接上代码 #include "stdafx.h" #include <iostream> #include <string> #include <vector> using namespace std; void quickSort(vector<int> &a, int, int); void swap(int &a, int&b); vector<string> split(strin
-
java数据结构与算法之快速排序详解
本文实例讲述了java数据结构与算法之快速排序.分享给大家供大家参考,具体如下: 交换类排序的另一个方法,即快速排序. 快速排序:改变了冒泡排序中一次交换仅能消除一个逆序的局限性,是冒泡排序的一种改进:实现了一次交换可消除多个逆序.通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 步骤: 1.从数列中挑出一个元素,称为 "基准"(piv
-

c++快速排序详解
说一说快速排序 快速排序,实际中最常用的一种排序算法,速度快,效率高,在N*logN的同等级算法中效率名列前茅.· 基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分所有数据要小,然后再按此方法对这两部分数据分别进行快速排序.整个排序过程可以递归进行,以此达到整个数据变成有序序列. 将数列变成上述形式,这一步很关键,做好这一步,才能对主元左右的部分进行递归调用.以下是实现这一部分的代码: int partition_sort(int arr[],int l
-
Python实现的数据结构与算法之快速排序详解
本文实例讲述了Python实现的数据结构与算法之快速排序.分享给大家供大家参考.具体分析如下: 一.概述 快速排序(quick sort)是一种分治排序算法.该算法首先 选取 一个划分元素(partition element,有时又称为pivot):接着重排列表将其 划分 为三个部分:left(小于划分元素pivot的部分).划分元素pivot.right(大于划分元素pivot的部分),此时,划分元素pivot已经在列表的最终位置上:然后分别对left和right两个部分进行 递归排序. 其中
-
JS排序之快速排序详解
本文为大家分享了JS快速排序的具体代码,供大家参考,具体内容如下 说明 时间复杂度指的是一个算法执行所耗费的时间 空间复杂度指运行完一个程序所需内存的大小 稳定指,如果a=b,a在b的前面,排序后a仍然在b的前面 不稳定指,如果a=b,a在b的前面,排序后可能会交换位置 --JS快速排序-- 原理 从数组中选定一个基数,然后把数组中的每一项与此基数做比较,小的放入一个新数组,大的放入另外一个新数组.然后再采用这样的方法操作新数组.直到所有子集只剩下一个元素,排序完成. 时间复杂度,空间复杂度,稳
-
深入单链表的快速排序详解
单链表的快排序和数组的快排序基本思想相同,同样是基于划分,但是又有很大的不同:单链表不支持基于下标的访问.故书中把待排序的链表拆分为2个子链表.为了简单起见,选择链表的第一个节点作为基准,然后进行比较,比基准小得节点放入左面的子链表,比基准大的放入右边的子链表.在对待排序链表扫描一遍之后,左边子链表的节点值都小于基准的值,右边子链表的值都大于基准的值,然后把基准插入到链表中,并作为连接两个子链表的桥梁.然后分别对左.右两个子链表进行递归快速排序,以提高性能.但是,由于单链表不能像数组那样随机存储
-
JAVA十大排序算法之快速排序详解
目录 快速排序 问题 思路 荷兰国旗问题 代码实现 时间复杂度 算法稳定性 总结 快速排序 快速排序是对冒泡排序的一种改进,也是采用分治法的一个典型的应用.JDK中Arrays的sort()方法,具体的排序细节就是使用快速排序实现的. 从数组中任意选取一个数据(比如数组的第一个数或最后一个数)作为关键数据,我们称为基准数(pivot,或中轴数),然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序,也称为分区(partition)操作. 问题 若给定一个无序数组
-
python 二分查找和快速排序实例详解
思想简单,细节颇多:本以为很简单的两个小程序,写起来发现bug频出,留此纪念. #usr/bin/env python def binary_search(lst,t): low=0 height=len(lst)-1 quicksort(lst,0,height) print lst while low<=height: mid = (low+height)/2 if lst[mid] == t: return lst[mid] elif lst[mid]>t: height=mid-1 e
-
JavaScript算法系列之快速排序(Quicksort)算法实例详解
"快速排序"的思想很简单,整个排序过程只需要三步: (1)在数据集之中,选择一个元素作为"基准"(pivot). (2)所有小于"基准"的元素,都移到"基准"的左边:所有大于"基准"的元素,都移到"基准"的右边. (3)对"基准"左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止. 举例来说,现在有一个数据集{85, 24, 63, 45,
-
C语言数据结构 快速排序实例详解
C语言数据结构 快速排序实例详解 一.快速排序简介 快速排序采用分治的思想,第一趟先将一串数字分为两部分,第一部分的数值都比第二部分要小,然后按照这种方法,依次对两边的数据进行排序. 二.代码实现 #include <stdio.h> /* 将两个数据交换 */ void swap(int* Ina , int* Inb) { int temp = *Ina; *Ina = *Inb; *Inb = temp; } /* 进行一趟的快速排序,把一个序列分为两个部分 */ int getPart
-
Java编程实现快速排序及优化代码详解
普通快速排序 找一个基准值base,然后一趟排序后让base左边的数都小于base,base右边的数都大于等于base.再分为两个子数组的排序.如此递归下去. public class QuickSort { public static <T extends Comparable<? super T>> void sort(T[] arr) { sort(arr, 0, arr.length - 1); } public static <T extends Comparabl