详解Servlet 3.0/3.1 中的异步处理
在Servlet 3.0之前,Servlet采用Thread-Per-Request的方式处理请求,即每一次Http请求都由某一个线程从头到尾负责处理。如果一个请求需要进行IO操作,比如访问数据库、调用第三方服务接口等,那么其所对应的线程将同步地等待IO操作完成, 而IO操作是非常慢的,所以此时的线程并不能及时地释放回线程池以供后续使用,在并发量越来越大的情况下,这将带来严重的性能问题。即便是像Spring、Struts这样的高层框架也脱离不了这样的桎梏,因为他们都是建立在Servlet之上的。为了解决这样的问题,Servlet 3.0引入了异步处理,然后在Servlet 3.1中又引入了非阻塞IO来进一步增强异步处理的性能。
本文源代码:https://github.com/davenkin/servlet-3-async-learning
项目下载地址:servlet-3-async-learning_jb51.rar
在Servlet 3.0中,我们可以从HttpServletRequest对象中获得一个AsyncContext对象,该对象构成了异步处理的上下文,Request和Response对象都可从中获取。AsyncContext可以从当前线程传给另外的线程,并在新的线程中完成对请求的处理并返回结果给客户端,初始线程便可以还回给容器线程池以处理更多的请求。如此,通过将请求从一个线程传给另一个线程处理的过程便构成了Servlet 3.0中的异步处理。
举个例子,对于一个需要完成长时处理的Servlet来说,其实现通常为:
@WebServlet("/syncHello")
public class SyncHelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
new LongRunningProcess().run();
response.getWriter().write("Hello World!");
}
}
为了模拟长时处理过程,我们创建了一个LongRunningProcess类,其run()方法将随机地等待2秒之内的一个时间:
public class LongRunningProcess {
public void run() {
try {
int millis = ThreadLocalRandom.current().nextInt(2000);
String currentThread = Thread.currentThread().getName();
System.out.println(currentThread + " sleep for " + millis + " milliseconds.");
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
此时的SyncHelloServlet将顺序地先执行LongRunningProcess的run()方法,然后将将HelloWorld返回给客户端,这是一个典型的同步过程。
在Servlet 3.0中,我们可以这么写来达到异步处理:
@WebServlet(value = "/simpleAsync", asyncSupported = true)
public class SimpleAsyncHelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
AsyncContext asyncContext = request.startAsync();
asyncContext.start(() -> {
new LongRunningProcess().run();
try {
asyncContext.getResponse().getWriter().write("Hello World!");
} catch (IOException e) {
e.printStackTrace();
}
asyncContext.complete();
});
}
此时,我们先通过request.startAsync()获取到该请求对应的AsyncContext,然后调用AsyncContext的start()方法进行异步处理,处理完毕后需要调用complete()方法告知Servlet容器。start()方法会向Servlet容器另外申请一个新的线程(可以是从Servlet容器中已有的主线程池获取,也可以另外维护一个线程池,不同容器实现可能不一样),然后在这个新的线程中继续处理请求,而原先的线程将被回收到主线程池中。事实上,这种方式对性能的改进不大,因为如果新的线程和初始线程共享同一个线程池的话,相当于闲置下了一个线程,但同时又占用了另一个线程。
当然,除了调用AsyncContext的start()方法,我们还可以通过手动创建线程的方式来实现异步处理:
@WebServlet(value = "/newThreadAsync", asyncSupported = true)
public class NewThreadAsyncHelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
AsyncContext asyncContext = request.startAsync();
Runnable runnable = () -> {
new LongRunningProcess().run();
try {
asyncContext.getResponse().getWriter().write("Hello World!");
} catch (IOException e) {
e.printStackTrace();
}
asyncContext.complete();
};
new Thread(runnable).start();
}
}
自己手动创建新线程一般是不被鼓励的,并且此时线程不能重用。因此,一种更好的办法是我们自己维护一个线程池。这个线程池不同于Servlet容器的主线程池,如下图:
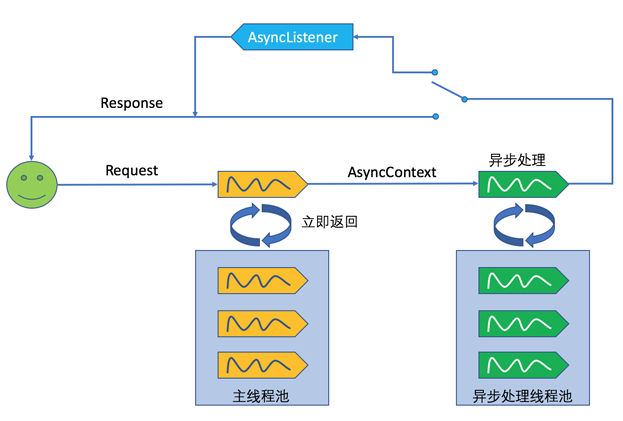
在上图中,用户发起的请求首先交由Servlet容器主线程池中的线程处理,在该线程中,我们获取到AsyncContext,然后将其交给异步处理线程池。可以通过Java提供的Executor框架来创建线程池:
@WebServlet(value = "/threadPoolAsync", asyncSupported = true)
public class ThreadPoolAsyncHelloServlet extends HttpServlet {
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 200, 50000L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
AsyncContext asyncContext = request.startAsync();
executor.execute(() -> {
new LongRunningProcess().run();
try {
asyncContext.getResponse().getWriter().write("Hello World!");
} catch (IOException e) {
e.printStackTrace();
}
asyncContext.complete();
});
}
}
Servlet 3.0对请求的处理虽然是异步的,但是对InputStream和OutputStream的IO操作却依然是阻塞的,对于数据量大的请求体或者返回体,阻塞IO也将导致不必要的等待。因此在Servlet 3.1中引入了非阻塞IO(参考下图红框内容),通过在HttpServletRequest和HttpServletResponse中分别添加ReadListener和WriterListener方式,只有在IO数据满足一定条件时(比如数据准备好时),才进行后续的操作。
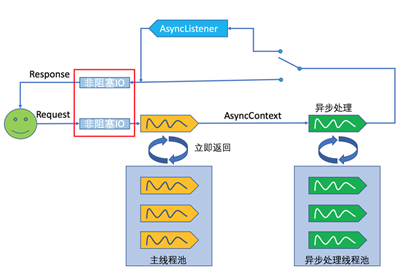
对应的代码示:
@WebServlet(value = "/nonBlockingThreadPoolAsync", asyncSupported = true)
public class NonBlockingAsyncHelloServlet extends HttpServlet {
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 200, 50000L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
AsyncContext asyncContext = request.startAsync();
ServletInputStream inputStream = request.getInputStream();
inputStream.setReadListener(new ReadListener() {
@Override
public void onDataAvailable() throws IOException {
}
@Override
public void onAllDataRead() throws IOException {
executor.execute(() -> {
new LongRunningProcess().run();
try {
asyncContext.getResponse().getWriter().write("Hello World!");
} catch (IOException e) {
e.printStackTrace();
}
asyncContext.complete();
});
}
@Override
public void onError(Throwable t) {
asyncContext.complete();
}
});
}
}
在上例中,我们为ServletInputStream添加了一个ReadListener,并在ReadListener的onAllDataRead()方法中完成了长时处理过程。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Tomcat怎么实现异步Servlet
有时Servlet在生成响应报文前必须等待某些耗时的操作,比如在等待一个可用的JDBC连接或等待一个远程Web服务的响应.对于这种情况servlet规范中定义了异步处理方式,由于Servlet中等待阻塞会导致Web容器整体的处理能力低下,所以对于比较耗时的操作可以放置到另外一个线程中进行处理,此过程保留连接的请求和响应对象,在处理完成之后可以把处理的结果通知到客户端. 下面先看Servlet在同步情况下的处理过程,如图所示,Tomcat的客户端请求由管道处理最后会通过Wrapper容器的管道,这
-
java基于servlet的文件异步上传
在这里使用了基于servlet的文件异步上传,好了废话不多说,直接上代码了... package com.future.zfs.util; import java.io.File; import java.io.IOException; import java.io.PrintWriter; import java.util.Iterator; import java.util.List; import javax.servlet.ServletException; import javax.s
-
Jquery+ajax+JAVA(servlet)实现下拉菜单异步取值
首先来看工程结构图: 项目所需要的包,如下所示: JSP代码: <%@ page language="java" import="java.util.*" pageEncoding="GBK"%> <% String path = request.getContextPath(); String basePath = request.getScheme() + "://" + request.getServe
-
详解Servlet 3.0/3.1 中的异步处理
在Servlet 3.0之前,Servlet采用Thread-Per-Request的方式处理请求,即每一次Http请求都由某一个线程从头到尾负责处理.如果一个请求需要进行IO操作,比如访问数据库.调用第三方服务接口等,那么其所对应的线程将同步地等待IO操作完成, 而IO操作是非常慢的,所以此时的线程并不能及时地释放回线程池以供后续使用,在并发量越来越大的情况下,这将带来严重的性能问题.即便是像Spring.Struts这样的高层框架也脱离不了这样的桎梏,因为他们都是建立在Servlet之上的.
-
详解servlet配置load-on-startup的作用
在servlet的配置当中,<load-on-startup>1</load-on-startup>的含义是:标记容器是否在启动的时候就加载这个servlet. 当值为0或者大于0时,表示容器在应用启动时就加载这个servlet:当是一个负数时或者没有指定时,则指示容器在该servlet被选择时才加载. 正数的值越小,启动该servlet的优先级越高. 如果我们在web.xml中设置了多个servlet的时候,可以使用load-on-startup来指定servlet的加载顺序,服
-
详解servlet调用的几种简单方式总结
servlet调用的几种简单方式 这里总结的是我在学习web开发的过程中需要用到的几种比较常见的用于转发和调用servlet的方式,这些方式的使用率非常高.在网上总结了相关的方法,大多对于初学者不是特别的友好,自己总结了一下. 1.servlet直接转发到另一个servlet 我们在进行jsp页面点击按钮进行登录的时候,首先需要登录到进行登录检查的servlet,但是在下个jsp页面,我们需要那个页面通过servlet进行转发,所以需要从servlet直接跳转到另一个servlet,其实写法很简
-
详解MySQL数据类型DECIMAL(N,M)中N和M分别表示的含义
同事问MySQL数据类型DECIMAL(N,M)中N和M分别表示什么含义,M不用说,显然是小数点后的小数位数,但这个N究竟是小数点之前的最大位数,还是加上小数部分后的最大位数?这个还真记不清了.于是乎,创建测试表验证了一番,结果如下: 测试表,seller_cost字段定义为decimal(14,2) CREATE TABLE `test_decimal` ( `id` int(11) NOT NULL, `seller_cost` decimal(14,2) DEFAULT NULL ) EN
-
详解租约机制以及在hbase中的应用
详解租约机制以及在hbase中的应用 为什么需要Lease 分布式系统中为什么需要租约机制,这是因为在分布式系统,为了保证服务的高可用,需要在服务发生故障的时候及时启动另外一个服务实例以替换故障服务.这样就需要在服务端和客户端或者服务端和控制中心维持一个心跳信息,用于服务进程向控制中心汇报当前自己的健康情况,如果控制中心在一段时间收不到服务进程上报的心跳,则会启动新的进程继续对外提供服务. 但是,由于实际网络情况的复杂性,控制中心无法收到心跳时不能准确地判断究竟是服务故障了还是服务进程和控制中心
-
详解javascript void(0)
void关键字介绍 首先,void关键字是javascript当中非常重要的关键字,该操作符指定要计算或运行一个表达式,但是不返回值. 语法格式: void func() void(func()) 实例1 当点击超级链接时,什么都不发生 <!-- 1.当用户链接时,void(0)计算为0,用户点击不会发生任何效果 --> <a href="javascript:void(0);" rel="external nofollow" rel="
-
详解如何在C#/.NET Core中使用责任链模式
最近我有一个朋友在研究经典的"Gang Of Four"设计模式.他经常来询问我在实际业务应用中使用了哪些设计模式.单例模式.工厂模式.中介者模式 - 都是我之前使用过,甚至写过相关文章的模式.但是有一种模式是我还没有写过文章,即责任链模式. 什么是责任链?# 责任链模式(之前我经常称之为命令链模式)是一种允许以使用分层方式"处理"对象的模式.在维基百科中的经典定义是 在面向对象设计中,责任链模式是一种由命令对象源及其一系列处理对象组成的设计模式.每个处理对象包含了
-
详解MySQL 8.0 之不可见索引
言 MySQL 8.0 从第一版release 到现在已经走过了4个年头了,8.0版本在功能和代码上做了相当大的改进和重构.和DBA圈子里的朋友交流,大部分还是5.6 ,5.7的版本,少量的走的比较靠前采用了MySQL 8.0.为了紧追数据库发展的步伐,能够尽早享受技术红利,我们准备将MySQL 8.0引入到有赞的数据库体系. 落地之前 我们会对MySQL 8.0的新特性和功能,配置参数,升级方式,兼容性等等做一系列的学习和测试.以后陆陆续续会发布文章出来.本文算是MySQL 8.0新特性学习的
-
详解Servlet入门级设置(超详细 IDEA2020版)
第一次用IntelliJ IDEA写java代码,之前都是用eclipse,但eclipse太老了. 下面为兄弟们奉上IntelliJ IDEA创建Servlet方法,写这个的目的也是因为很多视频教程还在用2017版的IDEA(并不是针对大家用老版本,只是吐槽一下版本更新迭代),所以把我走过的坑和弯路直接告诉兄弟们,为大家节省点宝贵的时间. 说一下现在创建Servlet或者是web和之前的主要区别,之前是直接创建,现在是先要创建java项目 然后通过添加支持框架变成Servlet或者web项目
-
详解Vue.js3.0 组件是如何渲染为DOM的
本文主要是讲述 Vue.js 3.0 中一个组件是如何转变为页面中真实 DOM 节点的.对于任何一个基于 Vue.js 的应用来说,一切的故事都要从应用初始化「根组件(通常会命名为 APP)挂载到 HTML 页面 DOM 节点(根组件容器)上」说起.所以,我们可以从应用的根组件为切入点. 主线思路:聚焦于一个组件是如何转变为 DOM 的. 辅助思路: 涉及到源代码的地方,需要明确标记源码所在文件,同时将 TS 简化为 JS 以便于直观理解 思路每前进一步要能够得出结论 尽量总结归纳出流程图 应用