opencv调用yolov3模型深度学习目标检测实例详解
目录
- 引言
- 建立相关目录
- 代码详解
- 附源代码
引言
opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解
对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn。 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码
建立相关目录
在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下,找到voc.names,类别标签文件,拷到win的工程文件夹下

代码详解
weightsPath='E:\deep_learn\yolov3_modeFile\yolov3-voc_25000.weights'# 模型权重文件 configPath="E:\deep_learn\yolov3_modeFile\yolov3-voc.cfg"# 模型配置文件 labelsPath = "E:\\deep_learn\\yolov3_modeFile\\voc.names"# 模型类别标签文件
引入模型的相关文件,这里需要使用yolo v3训练模型的三个文件
(1)模型权重文件 name.weights
(2)训练模型时的配置文件 yolov3-voc.cfg(一定和训练时一致,后面会提原因)
(3)模型类别的标签文件 voc.names
LABELS = open(labelsPath).read().strip().split("\n")
从voc.names中得到标签的数组LABELS 我的模型识别的是车和人 voc,names文件内容

LABELS数组内容

COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),dtype="uint8")#颜色 随机生成颜色框
根据类别个数随机生成几个颜色 ,用来后期画矩形框 [[ 33 124 191] [211 63 59]]
boxes = [] confidences = [] classIDs = []
声明三个数组 (1)boxes 存放矩形框信息 (2)confidences 存放框的置信度 (3)classIDs 存放框的类别标签 三个数组元素一一对应,即boxes[0]、confidences[0]、classIDs[0]对应一个识别目标的信息,后期根据该信息在图片中画出识别目标的矩形框
net = cv2.dnn.readNetFromDarknet(configPath,weightsPath)
加载 网络配置与训练的权重文件 构建网络 注意此处opencv2.7不行 ,没有dnn这个类,最好opencv版本在4.0以上,对应python用3.0以上版本
image = cv2.imread('E:\deep_learn\yolov3_detection_image\R1_WH_ZW_40_80_288.jpg')
(H,W) = image.shape[0:2]
读入待检测的图片,得到图像的高和宽
ln = net.getLayerNames()
得到 YOLO各层的名称,之后从各层名称中找到输出层



可以看到yolo的各层非常多,红框圈的'yolo_94'、'yolo_106'即为输出层,下面就需要通过代码找到这三个输出层,为什么是三个?跟yolo的框架结构有关,yolo有三个输出。对应的我们在训练模型时修改 yolov3-voc.cfg文件,修改的filters、classes也是三处,详细参考darknet YOLOv3数据集训练预测8. 修改./darknet/cfg/yolov3-voc.cfg文件

下面就是在yolo的所有层名称ln中找出三个输出层,代码如下
out = net.getUnconnectedOutLayers()#得到未连接层得序号
x = []
for i in out: # i=[200]
x.append(ln[i[0]-1]) # i[0]-1 取out中的数字 [200][0]=200 ln(199)= 'yolo_82'
ln=x
yolo的输出层是未连接层的前一个元素,通过net.getUnconnectedOutLayers()找到未连接层的序号out= [[200] /n [267] /n [400] ],循环找到所有的输出层,赋值给ln 最终ln = ['yolo_82', 'yolo_94', 'yolo_106'] 接下来就是将图像转化为输入的标准格式
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),swapRB=True, crop=False)
用需要检测的原始图像image构造一个blob图像,对原图像进行像素归一化1 / 255.0,缩放尺寸 (416, 416),,对应训练模型时cfg的文件 交换了R与G通道

交换R与G通道通道是opencv在打开图片时交换了一次,此处交换即又换回来了 此时blob.shape=(1, 3, 416, 416),四维。 可以用numpy里的squeeze()函数把秩为1的维度去掉,然后显示图片出来看看
image_blob = np.squeeze(blob)
cv2.namedWindow('image_blob', cv2.WINDOW_NORMAL)
cv2.imshow('image_blob',np.transpose(image_blob,[1,2,0]))
cv2.waitKey(0)

net.setInput(blob) #将blob设为输入 layerOutputs = net.forward(ln) #ln此时为输出层名称 ,向前传播 得到检测结果
将blob设为输入 ln此时为输出层名称 ,向前传播 得到检测结果。 此时layerOutputs即三个输出的检测结果,

layerOutputs是一个含有三个矩阵的列表变量,三个矩阵对应三个层的检测结果,其中一层的检测结果矩阵如下图
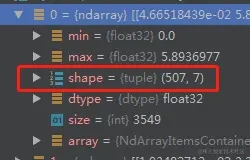
是个507*7的矩阵,这个矩阵代表着检测结果,其中507就是这层检测到了507个结果(即507个矩形框),其中7就是矩形框的信息,为什么是7呢,这里解释下,7=5+2,5是矩形框(x,y,w,h,c)2是2个类别分别的置信度(class0、class1). 所以每一行代表一个检测结果。
接下来就是对检测结果进行处理与显示 在检测结果中会有很多每个类的置信度为0的矩形框,要把这些与置信度较低的框去掉
#接下来就是对检测结果进行处理
for output in layerOutputs: #对三个输出层 循环
for detection in output: #对每个输出层中的每个检测框循环
scores=detection[5:] #detection=[x,y,h,w,c,class1,class2]
classID = np.argmax(scores)#np.argmax反馈最大值的索引
confidence = scores[classID]
if confidence >0.5:#过滤掉那些置信度较小的检测结果
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height)= box.astype("int")
# 边框的左上角
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 更新检测出来的框
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
现在就将网络的检测结果提取了出来,框、置信度、类别。 可以先画一下看下效果
a=0
for box in boxes:#将每个框画出来
a=a+1
(x,y)=(box[0],box[1])#框左上角
(w,h)=(box[2],box[3])#框宽高
if classIDs[a-1]==0: #根据类别设定框的颜色
color = [0,0,255]
else:
color = [0, 255, 0]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2) #画框
text = "{}: {:.4f}".format(LABELS[classIDs[a-1]], confidences[a-1])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1)#写字
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.imshow("Image", image)
cv2.waitKey(0)
结果:

可以看到对于同一目标有几个矩形框,这需要对框进行非极大值抑制处理。 进行非极大值抑制的操作,opencv的dnn有个直接的函数 NMSBoxes(bboxes, scores, score_threshold, nms_threshold, eta=None, top_k=None) bboxes需要操作的各矩形框对应咱程序的boxes scores矩形框对应的置信度对应咱程序的confidences score_threshold置信度的阈值,低于这个阈值的框直接删除 nms_threshold nms的阈值 非极大值的原理没有理解的话,里面的参数不好设置。 下面简单说下非极大值抑制的原理
1)先对输入检测框按置信度由高到低排序
2)挑选第一个检测框(即最高置信度,记为A)和其它检测框(记为B)进行iou计算
3)如果iou大于nmsThreshold, 那就将B清除掉
4)跳转到2)从剩余得框集里面找置信度最大得框和其它框分别计算iou
5)直到所有框都过滤完 NMSBoxes()函数返回值为最终剩下的按置信度由高到低的矩形框的序列号 进行非极大值抑制后,显示部分代码改一部分即可。
直接给出代码
idxs=cv2.dnn.NMSBoxes(boxes, confidences, 0.2,0.3)
box_seq = idxs.flatten()#[ 2 9 7 10 6 5 4]
if len(idxs)>0:
for seq in box_seq:
(x, y) = (boxes[seq][0], boxes[seq][1]) # 框左上角
(w, h) = (boxes[seq][2], boxes[seq][3]) # 框宽高
if classIDs[seq]==0: #根据类别设定框的颜色
color = [0,0,255]
else:
color = [0,255,0]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2) # 画框
text = "{}: {:.4f}".format(LABELS[classIDs[seq]], confidences[seq])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1) # 写字
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.imshow("Image", image)
cv2.waitKey(0)
最终的检测结果

至此及用opencv加载yolo v3的模型,进行了一次图片的检测。
附源代码
#coding:utf-8
import numpy as np
import cv2
import os
weightsPath='E:\deep_learn\yolov3_modeFile\yolov3-voc_25000.weights'# 模型权重文件
configPath="E:\deep_learn\yolov3_modeFile\yolov3-voc.cfg"# 模型配置文件
labelsPath = "E:\\deep_learn\\yolov3_modeFile\\voc.names"# 模型类别标签文件
#初始化一些参数
LABELS = open(labelsPath).read().strip().split("\n")
boxes = []
confidences = []
classIDs = []
#加载 网络配置与训练的权重文件 构建网络
net = cv2.dnn.readNetFromDarknet(configPath,weightsPath)
#读入待检测的图像
image = cv2.imread('E:\deep_learn\yolov3_detection_image\R1_WH_ZW_40_80_288.jpg')
#得到图像的高和宽
(H,W) = image.shape[0:2]
# 得到 YOLO需要的输出层
ln = net.getLayerNames()
out = net.getUnconnectedOutLayers()#得到未连接层得序号 [[200] /n [267] /n [400] ]
x = []
for i in out: # 1=[200]
x.append(ln[i[0]-1]) # i[0]-1 取out中的数字 [200][0]=200 ln(199)= 'yolo_82'
ln=x
# ln = ['yolo_82', 'yolo_94', 'yolo_106'] 得到 YOLO需要的输出层
#从输入图像构造一个blob,然后通过加载的模型,给我们提供边界框和相关概率
#blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None, ddepth=None)
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),swapRB=True, crop=False)#构造了一个blob图像,对原图像进行了图像的归一化,缩放了尺寸 ,对应训练模型
net.setInput(blob) #将blob设为输入??? 具体作用还不是很清楚
layerOutputs = net.forward(ln) #ln此时为输出层名称 ,向前传播 得到检测结果
for output in layerOutputs: #对三个输出层 循环
for detection in output: #对每个输出层中的每个检测框循环
scores=detection[5:] #detection=[x,y,h,w,c,class1,class2] scores取第6位至最后
classID = np.argmax(scores)#np.argmax反馈最大值的索引
confidence = scores[classID]
if confidence >0.5:#过滤掉那些置信度较小的检测结果
box = detection[0:4] * np.array([W, H, W, H])
#print(box)
(centerX, centerY, width, height)= box.astype("int")
# 边框的左上角
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 更新检测出来的框
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
idxs=cv2.dnn.NMSBoxes(boxes, confidences, 0.2,0.3)
box_seq = idxs.flatten()#[ 2 9 7 10 6 5 4]
if len(idxs)>0:
for seq in box_seq:
(x, y) = (boxes[seq][0], boxes[seq][1]) # 框左上角
(w, h) = (boxes[seq][2], boxes[seq][3]) # 框宽高
if classIDs[seq]==0: #根据类别设定框的颜色
color = [0,0,255]
else:
color = [0,255,0]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2) # 画框
text = "{}: {:.4f}".format(LABELS[classIDs[seq]], confidences[seq])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1) # 写字
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.imshow("Image", image)
cv2.waitKey(0)
以上就是opencv调用yolov3模型深度学习目标检测实例详解的详细内容,更多关于opencv调用yolov3目标检测的资料请关注我们其它相关文章!
相关推荐
-
OpenCV哈里斯角检测|Harris Corner理论实践
目录 目标 理论 OpenCV中的哈里斯角检测 SubPixel精度的转角 目标 在本章中,将学习 "Harris Corner Detection”背后的思想 函数:cv2.cornerHarris(),cv.2cornerSubPix() 理论 可以用如下图来表示: 因此,Harris Corner Detection的结果是具有这些分数的灰度图像.合适的阈值可提供图像的各个角落. OpenCV中的哈里斯角检测 在OpenCV中有实现哈里斯角点检测,cv2.cornerHarris().其参
-
Android OpenCV基础API清晰度亮度识别检测
目录 背景 基础知识 主要Api - 加载图片 imread Utils.bitmapToMat 主要API - 写入图片 端侧常用分析方法 亮度检测 清晰度检测 最后 背景 工作中遇到业务诉求是通过OpenCV对图片进行一些判断操作和优化,这里是看了部分不错的文章,希望总结一个自己的学习过程,温故而知新,有不对的地方可以评论区指出,小白学习海涵. 基础知识 Mat在OpenCV中是非常重要的存在,后续各个API都是在Mat的基础上去做文章,Mat 是Matrix(矩阵)的缩写 ... inli
-

golang 开启opencv图形化编程
目录 正文 环境配置 API编程 常用API OpenVideoCapture VideoCaptureDevice VideoCaptureFile NewWindow SetWindowTitle NewMat NewMatWithSize NewMatFromScalar NewCascadeClassifier Load 正文 最近在国外一个嵌入式编程网站上看到其平台支持Opencv库,出于好奇在其说明文档上看到gocv.io Opencv golang库的官网.就是下面这个. 在开启编
-
opencv python截取圆形区域的实现
目录 一.先进行剪切操作 二.去除背景 总结 一.先进行剪切操作 圆形区域占图片可能不多,多余的部分不要.看下图. 只要纽扣电池内部和少许的边缘部分,其余黑色背景部分不需要.先沿着纽扣电池的边缘剪切出来感兴趣的区域.有2个方法,用寻找轮廓外接圆的方法,或者基尔霍夫圆的方法.在这里以轮廓外接圆方法为例.代码如下: import cv2 import numpy as np image = cv2.imread('F:\Siamese-pytorch-master\datasets\images_b
-
opencv调用yolov3模型深度学习目标检测实例详解
目录 引言 建立相关目录 代码详解 附源代码 引言 opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解 对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn. 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码 建立相关目录 在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下
-
Python Flask搭建yolov3目标检测系统详解流程
[人工智能项目]Python Flask搭建yolov3目标检测系统 后端代码 from flask import Flask, request, jsonify from PIL import Image import numpy as np import base64 import io import os from backend.tf_inference import load_model, inference os.environ['CUDA_VISIBLE_DEVICES'] = '
-
python目标检测yolo3详解预测及代码复现
目录 学习前言 实现思路 1.yolo3的预测思路(网络构建思路) 2.利用先验框对网络的输出进行解码 3.进行得分排序与非极大抑制筛选 实现结果 学习前言 对yolo2解析完了之后当然要讲讲yolo3,yolo3与yolo2的差别主要在网络的特征提取部分,实际的解码部分其实差距不大 代码下载 本次教程主要基于github中的项目点击直接下载,该项目相比于yolo3-Keras的项目更容易看懂一些,不过它的许多代码与yolo3-Keras相同. 我保留了预测部分的代码,在实际可以通过执行dete
-
python目标检测yolo2详解及预测代码复现
目录 前言 实现思路 1.yolo2的预测思路(网络构建思路) 2.先验框的生成 3.利用先验框对网络的输出进行解码 4.进行得分排序与非极大抑制筛选 实现结果 前言 ……最近在学习yolo1.yolo2和yolo3,写这篇博客主要是为了让自己对yolo2的结构有更加深刻的理解,同时要理解清楚先验框的含义. 尽量配合代码观看会更容易理解. 直接下载 实现思路 1.yolo2的预测思路(网络构建思路) YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19
-
与Django结合利用模型对上传图片预测的实例详解
1 预处理 (1)对上传的图片进行预处理成100*100大小 def prepicture(picname): img = Image.open('./media/pic/' + picname) new_img = img.resize((100, 100), Image.BILINEAR) new_img.save(os.path.join('./media/pic/', os.path.basename(picname))) (2)将图片转化成数组 def read_image2(file
-
jQuery中通过ajax调用webservice传递数组参数的问题实例详解
下面通过实例给大家说明比较直观些,更方便大家了解. 本人的项目中通过jquery.ajax调用webservice. 客户端代码如下: $.ajax({ url: "test/xxx.asmx", type: 'POST', dataType: 'xml', timeout: , data: { name: "zhangsan", tags: ["aa", "bb", "cc"] }, error: fun
-
laravel框架模型和数据库基础操作实例详解
本文实例讲述了laravel框架模型和数据库基础操作.分享给大家供大家参考,具体如下: laravel分为三大数据库操作(DB facade[原始查找],查询构造器[Query Builder],Eloquent ORM): use Illuminate\Support\Facades\DB; 1.DB facade[原始查找] $results = DB::select('select * from users where id = :id', ['id' => 1]); DB::insert
-
PyTorch模型保存与加载实例详解
目录 一个简单的例子 保存/加载 state_dict(推荐) 保存/加载整个模型 保存加载用于推理的常规Checkpoint/或继续训练 保存多个模型到一个文件 使用其他模型来预热当前模型 跨设备保存与加载模型 总结 torch.save:保存序列化的对象到磁盘,使用了Python的pickle进行序列化,模型.张量.所有对象的字典. torch.load:使用了pickle的unpacking将pickled的对象反序列化到内存中. torch.nn.Module.load_state_di
-
MybatisPlus调用原生SQL的三种方法实例详解
目录 前言 方法一 方法二 方法三 MyBatis-Plus执行原生SQL 前言 在有些情况下需要用到MybatisPlus查询原生SQL,MybatisPlus其实带有运行原生SQL的方法,我这里列举三种 方法一 这也是网上流传最广的方法,但是我个人认为这个方法并不优雅,且采用${}的方式代码审计可能会无法通过,会被作为代码漏洞 public interface BaseMapper<T> extends com.baomidou.mybatisplus.core.mapper.BaseMa
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数