机器学习数据预处理之独热One-Hot编码及其代码详解
目录
- 1. 为什么使用 one-hot 编码?
- 问题:
- 目的:
- 瓶颈:
- 2. 什么是 one-hot 编码?
- 定义:
- 理解:
- 举例1:
- 举例2:
- 3. one-hot 编码优缺点?
- 优点:
- 缺点:
1. 为什么使用 one-hot 编码?
问题:
在机器学习算法中,我们经常会遇到分类特征,例如:人的性别有男女,祖国有中国,美国,法国等。 这些特征值并不是连续的,而是离散的,无序的。
目的:
如果要作为机器学习算法的输入,通常我们需要对其进行特征数字化。什么是特征数字化呢?例如:
性别特征:["男","女"]
祖国特征:["中国","美国,"法国"]
运动特征:["足球","篮球","羽毛球","乒乓球"]
瓶颈:
假如某个样本(某个人),他的特征是["男","中国","乒乓球"] ,我们可以用 [0,0,4] 来表示,但是这样的特征处理并不能直接放入机器学习算法中。因为类别之间是无序的。
2. 什么是 one-hot 编码?
定义:
独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
理解:
One-Hot 编码是分类变量作为二进制向量的表示。
(1) 将分类值映射到整数值。
(2) 然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
举例1:
举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:

上述feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。feature_2 和 feature_3 各有4种取值(状态)。
one-hot 编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。
上述状态用 one-hot 编码如下图所示:

举例2:
按照 N位状态寄存器 来 对N个状态 进行编码的原理,处理后应该是这样的
性别特征:["男","女"] (这里只有两个特征,所以 N=2):
男 => 10
女 => 01
祖国特征:["中国","美国,"法国"](N=3):
中国 => 100
美国 => 010
法国 => 001
运动特征:["足球","篮球","羽毛球","乒乓球"](N=4):
足球 => 1000
篮球 => 0100
羽毛球 => 0010
乒乓球 => 0001
所以,当一个样本为 ["男","中国","乒乓球"] 的时候,完整的特征数字化的结果为:
[1,0,1,0,0,0,0,0,1]
下图可能会更好理解:

python 代码示例:
from sklearn import preprocessing enc = preprocessing.OneHotEncoder() enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # 训练。这里共有4个数据,3种特征 array = enc.transform([[0,1,3]]).toarray() # 测试。这里使用1个新数据来测试 print array # [[ 1 0 0 1 0 0 0 0 1]] # 独热编码结果
以上对应关系可以解释为下图:

3. one-hot 编码优缺点?
优点:
(1) 解决了 分类器不好处理离散数据 的问题。
a. 欧式空间。在回归,分类,聚类等机器学习算法中,特征之间距离计算 或 相似度计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
b. one-hot 编码。使用 one-hot 编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值 就 对应欧式空间的某个点。将离散型特征使用 one-hot 编码,确实会让特征之间的距离计算更加合理。
(2) 在一定程度上也起到了 扩充特征 的作用。
缺点:
在文本特征表示上有些缺点就非常突出了。
(1) 它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);
(2) 它假设词与词相互独立(在大多数情况下,词与词是相互影响的);
(3) 它得到的特征是离散稀疏的 (这个问题最严重)。
上述第3点展开:
(1) 为什么得到的特征是离散稀疏的?
例如,如果将世界所有城市名称作为语料库的话,那这个向量会过于稀疏,并且会造成维度灾难。如下:
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。
(2)能不能把词向量的维度变小呢?
a) Dristributed representation:
可以解决 One hot representation 的问题,它的思路是:
1. 通过训练,将每个词都映射到一个较短的词向量上来。
2. 所有的这些 词向量 就构成了 向量空间,
3. 进而可以用 普通的统计学的方法 来研究词与词之间的关系。
这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
b) 举例:
1. 比如将词汇表里的词用 "Royalty", "Masculinity", "Femininity" 和 "Age" 4个维度来表示,King 这个词对应的词向量可能是 (0.99,0.99,0.05,0.7)。

2. 在实际情况中,并不能对词向量的每个维度做一个很好的解释。
3.将king这个词从一个可能非常稀疏的向量坐在的空间,映射到现在这个 四维向量 所在的空间,必须满足以下性质:
(1)这个映射是单射;
(2)映射之后的向量 不会丢失之前的 那种向量 所含的信息 。
4.这个过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。如图:
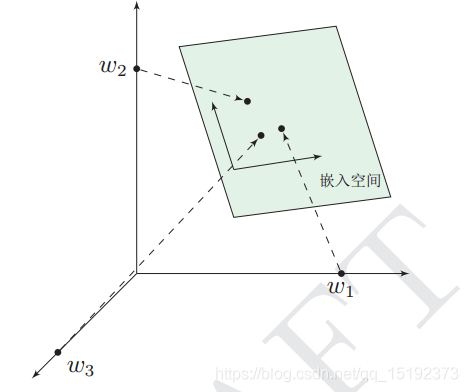
5.经过我们一系列的降维神操作,有了用 representation 表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到 2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:

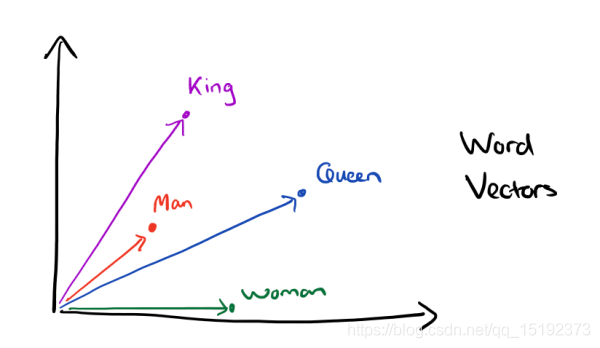
6. 出现这种现象的原因是,我们得到最后的词向量的训练过程中引入了词的上下文。举例:

想到得到 "learning" 的词向量,但训练过程中,你同时考虑了它左右的上下文,那么就可以使 "learning" 带有语义信息了。通过这种操作,我们可以得到近义词,甚至 cat 和它的复数 cats 的向量极其相近。
--------------------------------------------------------------------
参考博客:
到此这篇关于机器学习数据预处理之独热One-Hot编码及其代码详解的文章就介绍到这了,更多相关one-hot 编码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python对离散变量的one-hot编码方法
我们在进行建模时,变量中经常会有一些变量为离散型变量,例如性别.这些变量我们一般无法直接放到模型中去训练模型.因此在使用之前,我们往往会对此类变量进行处理.一般是对离散变量进行one-hot编码.下面具体介绍通过python对离散变量进行one-hot的方法. 注意:这里提供两种哑编码的实现方法,pandas和sklearn.它们最大的区别是,pandas默认只处理字符串类别变量,sklearn默认只处理数值型类别变量(需要先 LabelEncoder ) ① pd.get_dummies(pr
-

在 Python 中进行 One-Hot 编码
目录 1.介绍 2.什么是One-Hot编码? 3.实现-Pandas 4.实现-Scikit-Learn 5.One-hot编码在机器学习领域的应用 1.介绍 在计算机科学中,数据可以用很多不同的方式表示,自然而然地,每一种方式在某些领域都有其优点和缺点. 由于计算机无法处理分类数据,因为这些类别对它们没有意义,如果我们希望计算机能够处理这些信息,就必须准备好这些信息. 此操作称为预处理. 预处理的很大一部分是编码 - 以计算机可以理解的方式表示每条数据(该
-
对python sklearn one-hot编码详解
one-hot编码的作用 使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点 将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间. sklearn的一个例子 from sklearn import preprocessing enc = preprocessing.One
-
pandas使用get_dummies进行one-hot编码的方法
离散特征的编码分为两种情况: 1.离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码 2.离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3} 使用pandas可以很方便的对离散型特征进行one-hot编码 import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5
-
机器学习数据预处理之独热One-Hot编码及其代码详解
目录 1. 为什么使用 one-hot 编码? 问题: 目的: 瓶颈: 2. 什么是 one-hot 编码? 定义: 理解: 举例1: 举例2: 3. one-hot 编码优缺点? 优点: 缺点: 1. 为什么使用 one-hot 编码? 问题: 在机器学习算法中,我们经常会遇到分类特征,例如:人的性别有男女,祖国有中国,美国,法国等. 这些特征值并不是连续的,而是离散的,无序的. 目的: 如果要作为机器学习算法的输入,通常我们需要对其进行特征数字化.什么是特征数字化呢?例如: 性别特征:["男
-
机器学习经典算法-logistic回归代码详解
一.算法简要 我们希望有这么一种函数:接受输入然后预测出类别,这样用于分类.这里,用到了数学中的sigmoid函数,sigmoid函数的具体表达式和函数图象如下: 可以较为清楚的看到,当输入的x小于0时,函数值<0.5,将分类预测为0:当输入的x大于0时,函数值>0.5,将分类预测为1. 1.1 预测函数的表示 1.2参数的求解 二.代码实现 函数sigmoid计算相应的函数值:gradAscent实现的batch-梯度上升,意思就是在每次迭代中所有数据集都考虑到了:而stoGradAscen
-
Java数据溢出代码详解
java是一门相对安全的语言,那么数据溢出时它是如何处理的呢? 看一段代码, public class Overflow { /** * @param args */ public static void main(String[] args) { int big = 0x7fffffff; //max int value System.out.println("big = " + big); int bigger = big * 4; System.out.println("
-
Java编程Post数据请求和接收代码详解
这两天在做http服务端请求操作,客户端post数据到服务端后,服务端通过request.getParameter()进行请求,无法读取到数据,搜索了一下发现是因为设置为text/plain模式才导致读取不到数据 urlConn.setRequestProperty("Content-Type","text/plain; charset=utf-8"); 若设置为以下方式,则通过request.getParameter()可以读取到数据 urlConn.setReq
-
Java编程多线程之共享数据代码详解
本文主要总结线程共享数据的相关知识,主要包括两方面:一是某个线程内如何共享数据,保证各个线程的数据不交叉:一是多个线程间如何共享数据,保证数据的一致性. 线程范围内共享数据 自己实现的话,是定义一个Map,线程为键,数据为值,表中的每一项即是为每个线程准备的数据,这样在一个线程中数据是一致的. 例子 package com.iot.thread; import java.util.HashMap; import java.util.Map; import java.util.Random; /*
-
MySQL中查询某一天, 某一月, 某一年的数据代码详解
今天 select * from 表名 where to_days(时间字段名) = to_days(now()); 昨天(包括昨天和今天的数据) SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1 昨天(只包括昨天) SELECT * FROM 表名 WHERE DATEDIFF(字段,NOW())=-1; -- 同理,查询前天的就是-2 近7天 SELECT * FROM 表名 where DATE_SUB(CURD
-
MySQL 快速删除大量数据(千万级别)的几种实践方案详解
笔者最近工作中遇见一个性能瓶颈问题,MySQL表,每天大概新增776万条记录,存储周期为7天,超过7天的数据需要在新增记录前老化.连续运行9天以后,删除一天的数据大概需要3个半小时(环境:128G, 32核,4T硬盘),而这是不能接受的.当然如果要整个表删除,毋庸置疑用 TRUNCATE TABLE就好. 最初的方案(因为未预料到删除会如此慢),代码如下(最简单和朴素的方法): delete from table_name where cnt_date <= target_date 后经过研究,
-
关于在IDEA热部署插件JRebel使用问题详解
问题描述: 在日常开发工作中,代码出现问题时往往要不停的修改测试验证其正确性.每一次修改代码都需要重启项目,十分耗时,对于企业大型项目来说重启一次项目的时间够你去喝杯咖啡了.为了减少项目重启的时间所以来介绍这款插件工具JRebel JRebel介绍: JRebel是一款JVM插件,它使得Java代码修改后不用重启项目,立即生效.IDEA上原生是不支持热部署的,一般更新了 Java 文件后要手动重启项目,才能生效,浪费时间浪费生命. 目前对于idea热部署最好的解决方案就是安装JRebel插件 s
-
SQL 使用 VALUES 生成带数据的临时表实例代码详解
VALUES 是 INSER 命令的子句. INSERT INOT 表名(列名1,列名2,-) VALUES(值1,值2,-) --语法: --SELECT * FROM ( --VALUES -- (1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) --) AS t(c1,c2,c3......) SELECT * FROM (
-
Spring boot实现热部署的两种方式详解
热部署是什么 大家都知道在项目开发过程中,常常会改动页面数据或者修改数据结构,为了显示改动效果,往往需要重启应用查看改变效果,其实就是重新编译生成了新的 Class 文件,这个文件里记录着和代码等对应的各种信息,然后 Class 文件将被虚拟机的 ClassLoader 加载. 而热部署正是利用了这个特点,它监听到如果有 Class 文件改动了,就会创建一个新的 ClaassLoader 进行加载该文件,经过一系列的过程,最终将结果呈现在我们眼前. 类加载机制 Java 中的类经过编译器可以把代