如何用Python进行回归分析与相关分析
目录
- 一、前言
- 1.1 回归分析
- 1.2 相关分析
- 二、代码的编写
- 2.1 前期准备
- 2.2 编写代码
- 2.2.1 相关分析
- 2.2.2 一元线性回归分析
- 2.2.3 多元线性回归分析
- 2.2.4 广义线性回归分析
- 2.2.5 logistic回归分析
- 三、代码集合
一、前言
1.1 回归分析
是用于研究分析某一变量受其他变量影响的分析方法,其基本思想是以被影响变量为因变量,以影响变量为自变量,研究因变量与自变量之间的因果关系。
1.2 相关分析
不考虑变量之间的因果关系而只研究变量之间的相关关系的一种统计方法。
二、代码的编写
2.1 前期准备
在编写代码之前,我们首先要知道需要用到的库有哪些。分别为:pandas\numpy\statsmodels\patsy。如果没有安装这些库是无法运行代码的 ,因此需要提前安装好这几个库。安装方法我在基础篇的第一章已经写有,可以进行参考:如何在Python中导入EXCEL数据
然后便可以导入库和所要处理的数据了。
import pandas as pd import numpy as np import statsmodels.api as sm from patsy import dmatrices data=pd.read_excel(r'D:\杂货\编码数据.xlsx',sheet_name='编码数据')
展示以下我所导入的数据的样式:

我准备的excel表格的数据比较多,在python中输出出来大概就是这个样子,至于这些数字是什么含义不用过多理会,这并不影响本篇方法的介绍。
2.2 编写代码
2.2.1 相关分析
首先介绍最简单的一个数据指标:相关系数
代码如下:
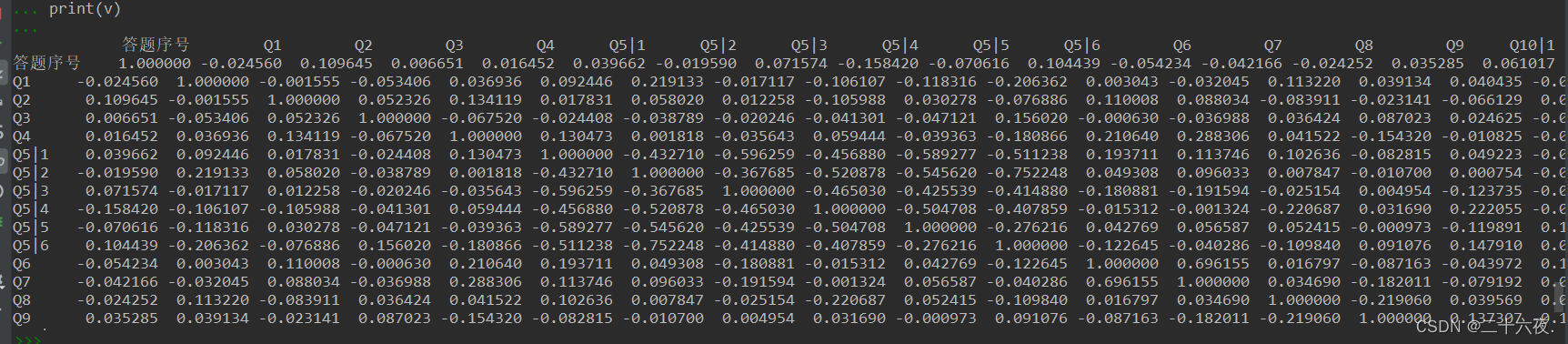
v=data['Q1'].corr(data['Q2'])#相关系数(求某两个变量的相关系数) print(v) v=data.corr()#求所有变量之间的相关系数 print(v)
前者是指定求某两个变量间的相关系数,而后者是直接接计算出所有变量的相关系数。
输出结果如下:
前者:

后者:
2.2.2 一元线性回归分析
代码如下:
x=np.array(data['Q1'])#一元线性回归分析 y=np.array(data['Q2']) X=sm.add_constant(x)#向x左侧添加截距列x0=[1,……,1] model=sm.OLS(y,X)#建立最小二乘估计 fit=model.fit()#拟合模型 print(fit.summary())
该方法是通过矩阵的形式进行运算的,首先将要输入的数据x,y转换为矩阵的形式,然后再给自变量x增加一列截距列,形成X矩阵,再进行最小二乘估计,然后拟合结果。
矩阵形式:
输出结果如下:

2.2.3 多元线性回归分析
vars=['Q1','Q2','Q6','Q7']#多元线性回归分析
df=data[vars]#将输入的数据转换为矩阵(数组)形式
y,X=dmatrices('Q1~Q2+Q6+Q7',data=df,return_type='dataframe')
model=sm.OLS(y,X)
fit=model.fit()
print(fit.summary())
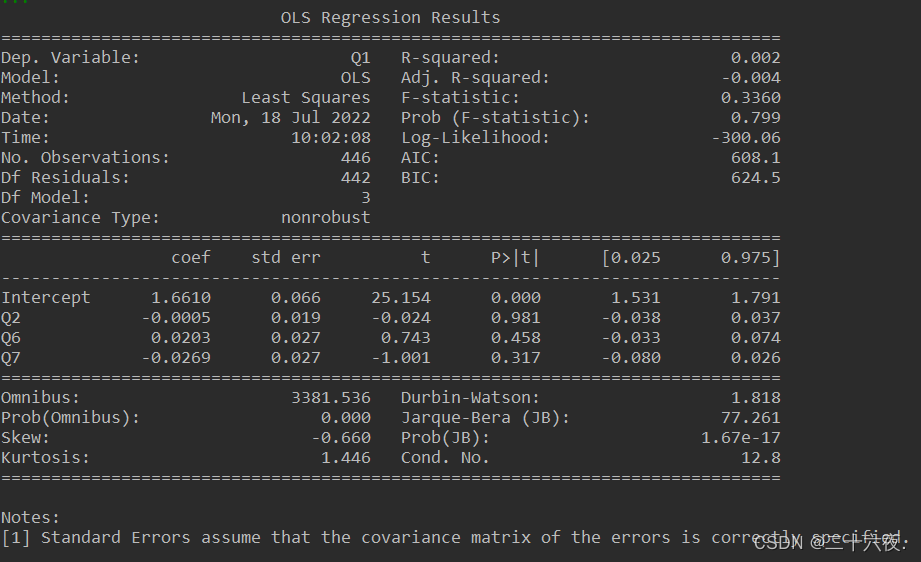
多元的代码的编写形式与一元的编写形式实质上差别不大,不同的地方在于第三行代码,其形式为 y,X=dmatrices('Q1~Q2+Q6+Q7',data=df,return_type='dataframe'),而该行代码的形式也是固定的,括号中的'Q1~Q2+Q6+Q7'这部分可根据个人想要模拟的方程形式编写,Q1为因变量,Q2,Q6,Q7……等部分为自变量,个数不限;data=df部分是将转换好的矩阵(数组)赋值给data;而return_type='dataframe'部分可以直接使用,一般不需要更改。
model=sm.OLS(y,X)进行最小二乘估计,fit=model.fit()进行模型的拟合,最后输出的fit.summary()即我们所需要的表格。
输出结果如下:
补充:
在此附上关于多元回归模型的一些内容,可帮助理解矩阵形式的回归模型。(摘自:《计量经济学基础》张晓峒)

2.2.4 广义线性回归分析
广义的线性回归分析包括四种模型,分别为:正态分布拟合;二项分布拟合;泊松分布拟合;伽马分布拟合。
本人常用二项分布,因此本篇以二项分布为例进行介绍。
代码如下:
vars2=['Q1','Q2']#广义线性回归分析 vars1=['Q6','Q7','Q8','Q9'] glm_binom=sm.GLM(data[vars2],data[vars1],family=sm.families.Binomial()) res=glm_binom.fit() print(res.summary())
需要注意的是:若在广义线性回归分析中的vars2的数据换成0-1形式的,则其结果与logistic回归分析的结果一致,即可以说0-1形式的因变量的广义线性回归为逻辑回归。
输出结果如下:

2.2.5 logistic回归分析
代码如下:
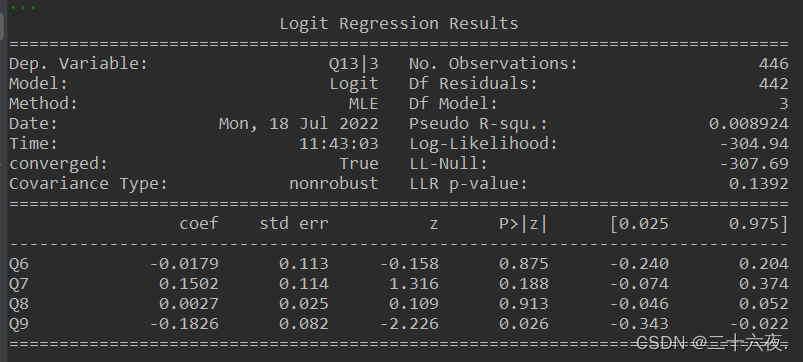
vars1=['Q6','Q7','Q8','Q9'] logit_mod=sm.Logit(data['Q13|3'],data[vars1])#logistic回归分析,注意:data['Q13|3']的位置里的数据必须是0-1形式!!! logit_res=logit_mod.fit(disp=0) print(logit_res.summary())
logistic回归的代码的编写形式与前面几个回归差别不大,理解起来不难,就不再重复讲述。但需要注意的是,在使用逻辑回归时,sm.Logit(data['Q13|3'],data[vars1])中的data['Q13|3']的数据必须为0-1形式,亦可说必须为虚拟变量的形式,否则程序会报错。这是逻辑回归本身的含义,具体可自行查找逻辑回归的资料学习。
输出结果如下:
三、代码集合
import pandas as pd
import numpy as np
import statsmodels.api as sm
from patsy import dmatrices
data=pd.read_excel(r'D:\杂货\编码数据.xlsx',sheet_name='编码数据')
pd.set_option('display.max_columns',1000)
pd.set_option("display.width",1000)
pd.set_option('display.max_colwidth',1000)
pd.set_option('display.max_rows',1000)
print(data)
v=data['Q1'].corr(data['Q2'])#相关系数
print(v)
x=np.array(data['Q1'])#一元线性回归分析
y=np.array(data['Q2'])
X=sm.add_constant(x)#向x左侧添加截距列x0=[1,……,1]
model=sm.OLS(y,X)#建立最小二乘估计
fit=model.fit()#拟合模型
print(fit.summary())
vars=['Q1','Q2','Q6','Q7']#多元线性回归分析
df=data[vars]
y,X=dmatrices('Q1~Q2+Q6+Q7',data=df,return_type='dataframe')
model=sm.OLS(y,X)
fit=model.fit()
print(fit.summary())
vars2=['Q1','Q2']#广义线性回归分析
vars1=['Q6','Q7','Q8','Q9']
glm_binom=sm.GLM(data[vars2],data[vars1],family=sm.families.Binomial())
res=glm_binom.fit()
print(res.summary())
logit_mod=sm.Logit(data['Q13|3'],data[vars1])#logistic回归分析,注意:data['Q13|3']的位置里的数据必须是0-1形式!!!
logit_res=logit_mod.fit(disp=0)
print(logit_res.summary())
#若在广义线性回归分析中的vars2的数据换成0-1形式的,则其结果与logistic回归分析的结果一致。
到此这篇关于如何用Python进行回归分析与相关分析的文章就介绍到这了,更多相关python 数据分析 回归 数据挖掘内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python人工智能算法之线性回归实例
目录 线性回归 使用场景 分析: 总结: 线性回归 是一种常见的机器学习算法,也是人工智能中常用的算法.它是一种用于预测数值型输出变量与一个或多个自变量之间线性关系的方法.例如,你可以使用线性回归模型来预测房价,根据房屋的面积.地理位置.周围环境等. 主要思想是通过构建一个线性模型,来描述自变量和输出变量之间的关系.模型可以表示为: y = a0 + a1*x1 + a2*x2 + - + an*xn 其中,y是输出变量(也称为响应变量),x1.x2.….xn是自变量(也称为特征),a0.a1.
-

python数据分析之线性回归选择基金
目录 1 前言 2 基金趋势分析 3 数据抓取与分析 3.1 基金数据抓取 3.2 数据分析 4 总结 1 前言 在前面的章节中我们牛刀小试,一直在使用python爬虫去抓取数据,然后把数据信息存放在数据库中,至此已经完成了基本的基本信息的处理,接下来就来处理高级一点儿的内容,今天就从基金的趋势分析开始. 2 基金趋势分析 基金的趋势,就是选择一些表现强势的基金,什么样的才是强势呢?那就是要稳定的,逐步的一路北上.通常情况下,基金都会沿着一条趋势线向上或者向下,基金的趋势形成比股票的趋势更加确定
-
Python实现随机森林回归与各自变量重要性分析与排序
目录 1 代码分段讲解 1.1 模块与数据准备 1.2 特征与标签分离 1.3 RF模型构建.训练与预测 1.4 预测图像绘制.精度衡量指标计算与保存 1.5 决策树可视化 1.6 变量重要性分析 2 完整代码 本文介绍在Python环境中,实现随机森林(Random Forest,RF)回归与各自变量重要性分析与排序的过程. 其中,关于基于MATLAB实现同样过程的代码与实战,大家可以点击查看MATLAB实现随机森林(RF)回归与自变量影响程度分析这篇文章. 本文分为两部分,第一部分为代码的分
-
Python反向传播实现线性回归步骤详细讲解
目录 1. 导入包 2. 生成数据 3. 训练数据 4. 绘制图像 5. 代码 1. 导入包 我们这次的任务是随机生成一些离散的点,然后用直线(y = w *x + b )去拟合 首先看一下我们需要导入的包有 torch 包为我们生成张量,可以使用反向传播 matplotlib.pyplot 包帮助我们绘制曲线,实现可视化 2. 生成数据 这里我们通过rand随机生成数据,因为生成的数据在0~1之间,这里我们扩大10倍. 我们设置的batch_size,也就是数据的个数为20个,所以这里会产生维
-
Python数据分析之双色球基于线性回归算法预测下期中奖结果示例
本文实例讲述了Python数据分析之双色球基于线性回归算法预测下期中奖结果.分享给大家供大家参考,具体如下: 前面讲述了关于双色球的各种算法,这里将进行下期双色球号码的预测,想想有些小激动啊. 代码中使用了线性回归算法,这个场景使用这个算法,预测效果一般,各位可以考虑使用其他算法尝试结果. 发现之前有很多代码都是重复的工作,为了让代码看的更优雅,定义了函数,去调用,顿时高大上了 #!/usr/bin/python # -*- coding:UTF-8 -*- #导入需要的包 import pan
-
Python基于TensorFlow接口实现深度学习神经网络回归
目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2.3 原有模型删除 2.4 数据导入与数据划分 2.5 Feature Columns定义 2.6 模型优化方法构建与模型结构构建 2.7 模型训练 2.8 模型验证与测试 2.9 精度评定.拟合图像绘制与模型参数与精度结果保存 3 详细代码 1 写在前面 1. 本文介绍的是基于TensorFlow tf.estimator接口的深度学习网络,而非TensorFlow 2.0中常用的Keras接口:关于Keras接口实现
-
Python利用keras接口实现深度神经网络回归
目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2.3 数据导入与数据划分 2.4 联合分布图绘制 2.5 因变量分离与数据标准化 2.6 原有模型删除 2.7 最优Epoch保存与读取 2.8 模型构建 2.9 训练图像绘制 2.10 最优Epoch选取 2.11 模型测试.拟合图像绘制.精度验证与模型参数与结果保存 3 完整代码 1 写在前面 前期一篇文章Python TensorFlow深度学习回归代码:DNNRegressor详细介绍了基于TensorFlow
-
如何用Python进行回归分析与相关分析
目录 一.前言 1.1 回归分析 1.2 相关分析 二.代码的编写 2.1 前期准备 2.2 编写代码 2.2.1 相关分析 2.2.2 一元线性回归分析 2.2.3 多元线性回归分析 2.2.4 广义线性回归分析 2.2.5 logistic回归分析 三.代码集合 一.前言 1.1 回归分析 是用于研究分析某一变量受其他变量影响的分析方法,其基本思想是以被影响变量为因变量,以影响变量为自变量,研究因变量与自变量之间的因果关系. 1.2 相关分析 不考虑变量之间的因果关系而只研究变量之间的相关关
-
如何用Python徒手写线性回归
对于大多数数据科学家而言,线性回归方法是他们进行统计学建模和预测分析任务的起点.这种方法已经存在了 200 多年,并得到了广泛研究,但仍然是一个积极的研究领域.由于良好的可解释性,线性回归在商业数据上的用途十分广泛.当然,在生物数据.工业数据等领域也不乏关于回归分析的应用. 另一方面,Python 已成为数据科学家首选的编程语言,能够应用多种方法利用线性模型拟合大型数据集显得尤为重要. 如果你刚刚迈入机器学习的大门,那么使用 Python 从零开始对整个线性回归算法进行编码是一次很有意义的尝试,
-
如何用Python来搭建一个简单的推荐系统
在这篇文章中,我们会介绍如何用Python来搭建一个简单的推荐系统. 本文使用的数据集是MovieLens数据集,该数据集由明尼苏达大学的Grouplens研究小组整理.它包含1,10和2亿个评级. Movielens还有一个网站,我们可以注册,撰写评论并获得电影推荐.接下来我们就开始实战演练. 在这篇文章中,我们会使用Movielens构建一个基于item的简易的推荐系统.在开始前,第一件事就是导入pandas和numPy. import pandas as pd import numpy a
-
如何用Python合并lmdb文件
由于Caffe使用的存储图像的数据库是lmdb,因此有时候需要对lmdb文件进行操作,本文主要讲解如何用Python合并lmdb文件.没有lmdb支持的,需要用pip命令安装. pip install lmdb 代码及注释如下: # coding=utf-8 # filename: merge_lmdb.py import lmdb # 将两个lmdb文件合并成一个新的lmdb def merge_lmdb(lmdb1, lmdb2, result_lmdb): print 'Merge sta
-
Python 线性回归分析以及评价指标详解
废话不多说,直接上代码吧! """ # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据集中的特征值总共10项, 如下: # 年龄 # 性别 #体质指数 #血压 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围. #验证就会发现任
-
如何用python处理excel表格
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-
如何用python免费看美剧
最早一部<越狱>转变了我对美剧的看法.主人公scofield的聪明才智和坚强的毅力,<绝命毒师>里面主人公的中年逆袭,<纸牌屋>里面老谋深算的政客,等等,这些美剧和里面鲜活的任务,至今令人记忆尤新. 最近,又迷上了美剧,无奈多数视频平台上的美剧都是收费的.对于一个资深Pythoner,我们可以用Python自动获取美剧的网址,下载了慢慢看. 我们以天天看M剧这个网站为例,来展示如何分析和下载这些内容,这里提供一种思路供大家学习.当然,我们还是得支持正版内容,这里是介绍技
-
如何用Python 加密文件
生活中,有时候我们需要对一些重要的文件进行加密,Python 提供了诸如 hashlib,base64 等便于使用的加密库. 但对于日常学习而言,我们可以借助异或操作,实现一个简单的文件加密程序,从而强化自身的编程能力. 基础知识 在 Python 中异或操作符为:^,也可以记作 XOR.按位异或的意思是:相同值异或为 0,不同值异或为 1.具体来讲,有四种可能:0 ^ 0 = 0,0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0.我们还可总结出规律(A 为 0 或 1):0 和
-
如何用Python绘制3D柱形图
本文主要讲解如何使用python绘制三维的柱形图,如下图 源代码如下: import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D #构造需要显示的值 X=np.arange(0, 5, step=1)#X轴的坐标 Y=np.arange(0, 9, step=1)#Y轴的坐标 #设置每一个(X,Y)坐标所对应的Z轴的值,在这边Z(X,Y)=X+Y Z=np.zeros(sh
-
教你如何用python操作摄像头以及对视频流的处理
实验介绍 此次实验帮助大家利用 OpenCV 去读取摄像头的视频流,你可以直接使用笔记本本身的摄像头,也可以用 USB 连接直接的摄像头.如果你在操作过程中,摄像头读取失败, 实验中还为你提供了几个问题排查步骤.当然,对视频进行操作时还需要讲解视频相关的编解码格式以及特定帧的读取.在实验的最后,还提供了 OpenCV 的项目实战:视频录制与视频读取. 知识点 视频录制 视频编解码格式 视频读取以及特定帧的读取 视频录制 使用 OpenCV 录制视频,主要涉及 OpenCV 的 VideoWrit