Mysql实现模糊查询的两种方式(like子句 、正则表达式)
目录
- 前言
- 语法
- like子句
- 语法
- 示例
- 正则表达式
- 语法
- 说明:
- 示例
- 总结
通常在实际应用中,会涉及到模糊查询的需求,查询在 MySQL 中使用 SQL SELECT 命令来读取数据,有条件的查询可以在 SELECT 语句中使用 WHERE 子句来获取记录
有时候我们需要获取某字段含有 “xxxxx” 字符的所有记录,这时就是模糊查询,下面介绍一下在MySQL中实现模糊查询的两种方式
前言
MySQL 查询数据使用SQL SELECT语句
语法
MySQL数据库中查询数据通用的 SELECT 语法:
SELECT column_name, column_name FROM table_name [WHERE Clause] [LIMIT N][ OFFSET M]
说明:
- SELECT 命令可以读取一条或者多条记录,一个字段信息或者多个字段信息,可使用星号(*)来代替其他字段返回表的所有字段数据
- SELECT 命令 from 后可以使用一个 / 多个表,表之间使用逗号( , ) 分割
- SELECT 命令 使用 WHERE 语句来包含任何条件
- SELECT 命令 使用 LIMIT 属性来设定返回的记录数。
- SELECT 命令 使用 OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
like子句
根据上述的语法,模糊查询的限制位置在 where 语句后,即like 在 where 中使用
语法
SELECT field1, field2,....,fieldN FROM table_name WHERE field1 LIKE condition;
说明:
- LIKE子句 在 WHERE 子句中使用,若 condition 为明确的数据,则 LIKE子句 相当于 等号 =(精准查询)
- 通常,condition 会包含 % ,即 LIKE 通常与 % 一同使用,进行搜索(模糊查询), xxx% 查找指定前缀的记录,%xxx 查找指定后缀的记录,%xxx% 查找包含指定内容的记录
示例
前提准备:创建表与插入数据
-- ---------------------------- -- Table structure for product -- ---------------------------- DROP TABLE IF EXISTS `product`; CREATE TABLE `product` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `product_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品名称', `price` decimal(10, 2) UNSIGNED NOT NULL COMMENT '产品价格', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO `product` VALUES (1, 'Apple iPhone 13 (A2634)', 6799.00); INSERT INTO `product` VALUES (2, 'HUAWEI P50 Pro', 6488.00); INSERT INTO `product` VALUES (3, 'MIX4', 4999.00); INSERT INTO `product` VALUES (4, 'OPPO Find X3', 3999.00); INSERT INTO `product` VALUES (5, 'OPPO Find X4', 3999.00); INSERT INTO `product` VALUES (6, 'OPPO Find Pro', 6488.00); INSERT INTO `product` VALUES (7, 'vivo X70 Pro+', 5999.00);
初始数据:
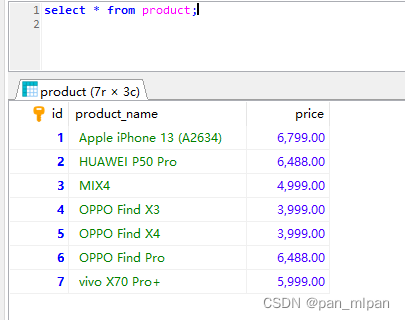
select * from product;
结果:
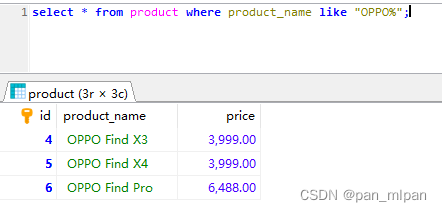
需求一:查询指定前缀的记录
查询 产品名称 为 oppo(即前缀为oppo) 的产品信息
select * from product where product_name like "OPPO%";
结果:
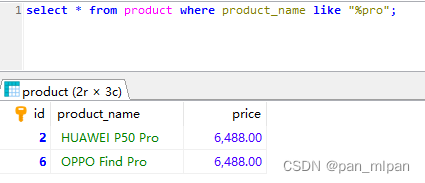
需求二:查询指定后缀的记录
查询产品系列为pro系列的产品,即 产品名称 后缀为 pro 的产品信息
select * from product where product_name like "%pro";
结果:
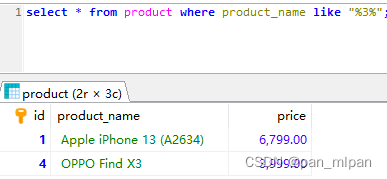
需求二:查询包含指定内容的记录
查询 产品名称 包含 3 的产品
select * from product where product_name like "%3%";
结果:
正则表达式
除了上述方法,MySQL 也支持正则表达式的匹配,通过使用 REGEXP 操作符来进行正则表达式匹配
语法
// 不区分大小写的查询 SELECT field1, field2,....,fieldN FROM table_name WHERE field1 regexp condition; // 区分大小写的查询 SELECT field1, field2,....,fieldN FROM table_name WHERE field1 regexp binary condition;
说明:
- regexp 操作符也在 WHERE 子句中使用,若 condition 不能为明确的数据,需要为正则表达式
- 默认 regexp 操作符 的查询不区分大小写,如若想区分大小写,可以在 regexp 操作符后 加上 binary 关键字即可
在 REGEXP 操作符中可以使用如下的正则模式:
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置 |
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像 ‘[.\n]’ 的模式 |
| […] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’ |
| [^…] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’ |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food” |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,} |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,} |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 |
示例
需求一:查询指定前缀的记录
查询 产品名称 为 oppo(即前缀为oppo) 的产品信息 不区分大小写
select * from product where product_name regexp "^oppo";
查询 产品名称 为 oppo(即前缀为oppo) 的产品信息 区分大小写
select * from product where product_name regexp binary "^oppo";
结果:

需求二:查询指定后缀的记录
查询产品系列为pro系列的产品,即 产品名称 后缀为 pro 的产品信息
select * from product where product_name regexp "pro$";
结果:
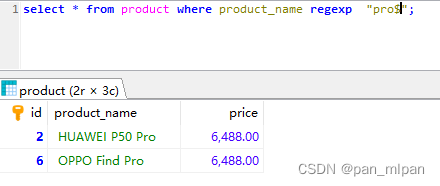
需求二:查询包含指定内容的记录
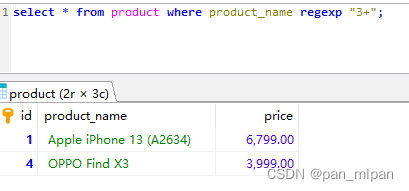
查询 产品名称 包含 3 的产品
select * from product where product_name regexp "3+";
结果:
总结
上述介绍了两种模糊匹配的实现方式,like 子句 与 正则表达式
很多场景下会使用 like 来对字符串进行匹配,从而实现模糊查询,但是这些场景往往非常简单,而正则表达式是一个非常强大的文本检索过滤工具,适用在很复杂的场景
到此这篇关于Mysql实现模糊查询(like子句 、正则表达式)的文章就介绍到这了,更多相关Mysql模糊查询方式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql中模糊查询的四种用法介绍
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] WHERE u_name LIKE '%三%' 将会把u_name为"张三","张猫三"."三脚猫","唐三藏"等等有"三"的记录全找出来. 另外,如果需要找出u_name中既有"三"又有
-
mysql中like % %模糊查询的实现
1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] WHERE u_name LIKE '%三%' 将会把u_name为"张三","张猫三"."三脚猫","唐三藏"等等有"三"的记录全找出来. 另外,如果需要找出u_name中既有"三"又有"猫"的记录,请使用a
-
MySQL模糊查询语句整理集合
SQL模糊查询语句 一般模糊语句语法如下: SELECT 字段 FROM 表 WHERE 某字段 Like 条件 其中关于条件,SQL提供了四种匹配模式: 1.%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. SELECT * FROM [user] WHERE u_name LIKE '%三%' 将会把u_name为"张三","张猫三"."三脚猫","唐三藏"等等有&
-

MySQL模糊查询用法大全(正则、通配符、内置函数)
SELECT * from table where username like '%陈哈哈%' and hobby like '%牛逼' 这是一条我们在MySQL中常用到的模糊查询方法,通过通配符%来进行匹配,其实,这只是冰山一角,在MySQL中,支持模糊匹配的方法有很多,且各有各的优点.好了,今天让我带大家一起掀起MySQL的小裙子,看一看模糊查询下面还藏着多少鲜为人知的好东西. 一.MySQL通配符模糊查询(%,_) 1-1. 通配符的分类 "%" 百分号通配符: 表示任何字符出现
-
MySql like模糊查询通配符使用详细介绍
一.SQL模式 SQL的模式匹配允许你使用"_"匹配任何单个字符,而"%"匹配任意数目字符(包括零个字符).在 MySQL中,SQL的模式缺省是忽略大小写的.下面显示一些例子.注意在你使用SQL模式时,你不能使用=或!=:而使用LIKE或NOT LIKE比较操作符. SELECT 字段 FROM 表 WHERE 某字段 Like 条件 其中关于条件,SQL提供了四种匹配模式: 1,%:表示任意个或多个字符.可匹配任意类型和长度的字符. 比如 SELECT * FRO
-
mysql模糊查询like和regexp小结
在mysql中实现模糊查询的有like和regexp. ------------------------ like的用法许多人都是知道的,最为常用的情况就是select * from a where name like '%a%'; 其中'%'代表的是任意个字符,它的效果像是正则表达式里的'*',它有几种用法:'a%','%a%','%a',分别表示以什么开头,存在什么以及以什么结尾. 另外也可以使用'_'字符,这表示一个任意字符.效果类似正则表达式里面的'.'. like是对这个字段里面的所有
-
MySQL单表多关键字模糊查询的实现方法
在最近的一个项目需要实现在MySQL单表多关键字模糊查询,但这数个关键字并不一定都存在于某个字段.例如现有table表,其中有title,tag,description三个字段,分别记录一条资料的标题,标签和介绍.然后根据用户输入的查询请求,将输入的字串通过空格分割为多个关键字,再在这三个字段中查询包含这些关键字的记录. 可目前遇到的问题是,这些关键字是可能存在于三个字段中的任意一个或者多个,但又要求三个字段必须包含所有的关键词.如果分别对每个字段进行模糊匹配,是没法实现所需的要求,由此想到两种
-
MySQL Like模糊查询速度太慢如何解决
问题:明明建立了索引,为何Like模糊查询速度还是特别慢? Like是否使用索引? 1.like %keyword 索引失效,使用全表扫描.但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描. 2.like keyword% 索引有效. 3.like %keyword% 索引失效,也无法使用反向索引. 使用mysql的explain简单测试如下: explain select * from company_info where cname like '%小%'
-
Mysql实现模糊查询的两种方式(like子句 、正则表达式)
目录 前言 语法 like子句 语法 示例 正则表达式 语法 说明: 示例 总结 通常在实际应用中,会涉及到模糊查询的需求,查询在 MySQL 中使用 SQL SELECT 命令来读取数据,有条件的查询可以在 SELECT 语句中使用 WHERE 子句来获取记录 有时候我们需要获取某字段含有 “xxxxx” 字符的所有记录,这时就是模糊查询,下面介绍一下在MySQL中实现模糊查询的两种方式 前言 MySQL 查询数据使用SQL SELECT语句 语法 MySQL数据库中查询数据通用的 SELEC
-
mysql清空表数据的两种方式和区别解析
在MySQL中删除数据有两种方式: truncate(截短)属于粗暴型的清空 delete属于精细化的删除 删除操作 如果你需要清空表里的所有数据,下面两种均可: delete from tablename; truncate table tablename; 而如果你只是删除一部分数据,就只能使用delete: delete from tablename where case1 and case2; 区别 在精细化的删除部分数据时,只能使用delete. 而清空所有表数据时,两者均可,此时这两
-
阿里云服务器手动实现mysql双机热备的两种方式
一.概念 1.热备份和备份的区别 热备份指的是:High Available(HA)即高可用,而备份指的是Backup,数据备份的一种.这是两种不同的概念,应对的产品也是两种功能上完全不同的产品.热备份主要保障业务的连续性,实现的方法是故障点的转移.而备份,主要目的是为了防止数据丢失,而做的一份拷贝,所以备份强调的是数据恢复而不是应用的故障转移. 2.什么是双机热备? 双机热备从广义上讲,就是对于重要的服务,使用两台服务器,互相备份,共同执行同一服务.当一台服务器出现故障时,可以由另一台服务器承
-
MyBatis实现模糊查询的几种方式
在学习MyBatis过程中想实现模糊查询,可惜失败了.后来上百度上查了一下,算是解决了.记录一下MyBatis实现模糊查询的几种方式. 数据库表名为test_student,初始化了几条记录,如图: 起初我在MyBatis的mapper文件中是这样写的: <select id="searchStudents" resultType="com.example.entity.StudentEntity" parameterType="com.exampl
-
vue实现input输入模糊查询的三种方式
目录 1 计算属性实现模糊查询 2 watch 监听实现模糊查询 3 通过按钮点击实现模糊查询 1 计算属性实现模糊查询 vue 中通过计算属性实现模糊查询,创建 html 文件,代码直接放入即可. 这里自己导入 vue,我是导入本地已经下载好的. <script src="./lib/vue-2.6.12.js"></script> 演示: 打开默认显示全部 输入关键字模糊查询,名字和年龄都可以 完整代码如下: <!DOCTYPE html> &l
-
Mysql添加外键的两种方式详解
目录 Mysql添加外键的几种方式 方法一: 方法二: 补充:MySQL 删除外键操作 总结 Mysql添加外键的几种方式 注意:添加外键是给从表添加(即子表)父表是主表 方法一: 创建表之前: FOREIGN KEY (子表id) REFERENCES 关联表名(外主表id) 例如 create table emp( e_id int auto_increment primary key, ename varchar(50) not null, age int, job varchar(20)
-
Mysql中分页查询的两个解决方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 复制代码 代码如下: SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM foo WHERE b = 1 LIMIT 100,10; 另外一种是使用SQL_CALC_FOUND_ROWS 复制代码 代码如下: SELECT SQL_CALC_FOUND_ROWS a FROM foo WHERE b = 1 LIMIT 100, 10; SELECT FOUND_
-
mysql自动填充时间的两种实现方式小结
目录 mysql自动填充时间的两种方式 方法一:数据库级别 方式二:代码级别 mysql自动填充时间的两种方式 mysql建表的时候有两个列,一个是createtime.另一个是updatetime 当插入一条数据,createtime列和updatetime列由数据库获取当前时间自动创建时间 当修改一条记录时,updatetime列由数据库获取按当前时间自动更新时间 方法一:数据库级别 (工作中不允许你修改数据库),一般我们采用方法二 1.在表中新增字段 create_time, update
-
php连接MySQL的两种方式对比
记录一下PHP连接MySQL的两种方式. 先mock一下数据,可以执行一下sql. /*创建数据库*/ CREATE DATABASE IF NOT EXISTS `test`; /*选择数据库*/ USE `test`; /*创建表*/ CREATE TABLE IF NOT EXISTS `user` ( name varchar(50), age int ); /*插入测试数据*/ INSERT INTO `user` (name, age) VALUES('harry', 20), ('