uber go zap 日志框架支持异步日志输出
目录
- 事件背景
- 心智负担
- 前置知识
- 解决思路
- uber-go/zap 代码分析
- 上手开发
- 测试代码
- 同步输出日志
- 异步输出日志
- 不输出日志
- 总结
事件背景
过年在家正好闲得没有太多事情,想起年前一个研发项目负责人反馈的问题:“老李啊,我们组一直在使用你这边的 gin 封装的 webservice 框架开发,我们需要一套标准的异步日志输出模块。现在组内和其他使用 gin 的小伙伴实现的‘各有千秋’不统一,没有一个组或者部门对这部分的代码负责和长期维护。你能不能想想办法。”
这一看就是掉头发的事情,虽然 gin 封装的 webservice 框架是我开发底层服务包,已经推广到公司所有 golang 开发组使用,现在需要一个统一异步日志输出的模块是否真的有意义,要认真的考虑和研究下,毕竟有核心业务团队有这样的需求。
索性打开了 uber-go/zap 日志框架的源代码,看看到底是什么原因推动大家都要手写异步日志模块。不看不知道,一看吓一跳,项目中 issue#998 就有讨论,我看了下 issue 留言,觉得大家的说法都挺正确,而项目作者一直无动无衷,而且坚信 bufio + 定时 flush 的方式 才是正道,怪不得大家都要自己手写一个异步日志输出模块。

心智负担
在要写 uber-go/zap 异步日志模块之前,首先要明白异步日志模块的优点、缺点以及适用的场景,这样代码才写的有意义,是真正的解决问题和能帮助到小伙伴的。
关于同步和异步模型的差异,这边就不展开了,估计再写几千字也不一定能说清楚,有需要深入了解的小伙伴,可以自行 baidu,那里有很多相关的文章,而且讲解得非常清晰。这里我就不需要过多解析,而我需要讲的是同步和异步日志模块。
- 同步日志:日志信息投递后,必须要等到日志信息写到对应的 io.Writer 中(os.Stdout, 文件等等)并返回,这个调用过程结束。适合 Warning 级别以上日志输出,强记录或者落盘需求的日志信息,不能丢失。
- 异步日志:日志信息投递后,调用过程结束。而日志信息是否能够正确写到对应的 io.Writer 中(os.Stdout, 文件等等)是由异步日志模块保证,不等待调用过程。适合 Warning 级别以下日志输出,尽量存储日志,如果没有存储,丢失也没有关系。
那么我就用一句话说明白这两种日志模型的差别。
- 同步日志:慢,安全,日志不丢
- 异步日志:快,不安全,日志尽力记录
既然这里说到是心智负担,但是真正负担在哪里? 实际上面已经提到了心智负担的核心内容:就是如何正确的选择一个日志模型。
而我们这边需求是明确知道有部分日志可以丢失,追求接口响应速度,希望有统一的实现,有人维护代码和与整个 gin 封装的 webservice 框架融合的品质。
前置知识
明确了开发的需求,开发的目标。确认了开发有意义,确实能解决问题。那么:就是干!!!
在动之前还是要准备些知识,还要做好结构设计,这样才能解答:一套合理的异步输出模型应该是什么样的?
分享下我理解的一个异步日志模型是什么样的(欢迎大家来“锤”,但是锤我的时候,麻烦轻点哈)

有的小伙伴看到这个图觉得有点眼熟?Kafka?不对,不对,不对,还少了一个 Broker。因为这里不需要对 Producer 实现一个独立的缓冲器和分类器,那么 Broker 这样的角色就不存在了。
简单的介绍下成员角色:
- MessageProducer: 消息和数据生成者
- CriticalSurface: 并发临界面,所有 MessageProducer 都到这边竞争控制权,往 RingBuffer 中写入数据
- RingBuffer: 消息和数据的缓冲(记得缓冲和缓存区别,这边用缓冲就是为了解决 Producer 和 Consumer 和速度差)
- MessageConsumer: 消息和数据消费者
为什么选择上面的模型:
- 希望在现有的 uber-go/zap 的结构上扩展,实现一部分能力,满足功能扩展。
- 不希望重复做轮子,因为轮子做出来,需要有严格的代码测试和压力测试,才能交付生产系统。
- 模型简单,好理解,也好实现。
- 性能比较高,而且架构整体比较合理。
为了实现这个模型,还需要思考如下几个问题:
- CriticalSurface 如何实现?因为要满足多个 MessageBroker 并发使用,那么这个临界面就必须要做,要不然就出现争抢资源失控的情况。
- 为什么要选择 RingBuffer?RingBuffer 是目前速度和效率最好的一种缓冲模型,Linux/Unix 系统中广泛使用。
- 选择 RingBuffer 需要注意些什么?RingBuffer 有快慢指针的问题,如果控制不好,快指针就回覆写慢指针的数据,地址数据丢失的情况。
- MessageConsumer 数量如何限制?如何平衡信息的创建与消费之间的速度差异。
- 如何支持多种日志方式输出类型。(golang 多种 io.Writer 模型)
如果看到这里,估计已经劝退了很多的小伙伴,我想这就是为什么那个研发项目负责人带着团队问题来找我,希望能够得到解决的原因吧。确实不容易。
解决思路
uber-go/zap 代码分析
在认真看看完了 uber-go/zap 的代码以后,发现 uber 就是 uber,代码质量还是非常不错的,很多模块抽象的非常不错。通过一段时间的思考后,确认我们要实现一个独立的 WriteSyncer, 跟 uber-go/zap 中的 BufferedWriteSyncer 扮演相同的角色。
既然要实现,我们先看看 uber-go/zap 中的源代码怎么定义 WriteSyncer 的。
go.uber.org/zap@v1.24.0/zapcore/write_syncer.go
// A WriteSyncer is an io.Writer that can also flush any buffered data. Note
// that *os.File (and thus, os.Stderr and os.Stdout) implement WriteSyncer.
type WriteSyncer interface {
io.Writer
Sync() error
}
WriteSyncer 是一个 interface,也就是我们只要引用 io.Writer 和实现 Sync() error 这样的一个方法就可以对接 uber-go/zap 系统中。那么 Sync() 这个函数到底是干嘛的? 顾名思义就是让 zap 触发数据同步动作时需要执行的一个方法。但是我们是异步日志,明显 uber-go/zap 处理完日志相关的数据,丢给我实现的 WriteSyncer 以后,就不应该在干预异步日志模块的后期动作了,所以 Sync() 给他一个空壳函数就行了。
当然 uber-go/zap 早考虑到这样的情况,就给一个非常棒的包装函数 AddSync()。
go.uber.org/zap@v1.24.0/zapcore/write_syncer.go
// AddSync converts an io.Writer to a WriteSyncer. It attempts to be
// intelligent: if the concrete type of the io.Writer implements WriteSyncer,
// we'll use the existing Sync method. If it doesn't, we'll add a no-op Sync.
func AddSync(w io.Writer) WriteSyncer {
switch w := w.(type) {
case WriteSyncer:
return w
default:
return writerWrapper{w}
}
}
type writerWrapper struct {
io.Writer
}
func (w writerWrapper) Sync() error {
return nil
}
uber-go/zap 已经把我们希望要做的事情都给做好了,我们只要实现一个标准的 io.Writer 就行了,那继续看 io.Writer 的定义方式。
go/src/io/io.go
// Writer is the interface that wraps the basic Write method.
//
// Write writes len(p) bytes from p to the underlying data stream.
// It returns the number of bytes written from p (0 <= n <= len(p))
// and any error encountered that caused the write to stop early.
// Write must return a non-nil error if it returns n < len(p).
// Write must not modify the slice data, even temporarily.
//
// Implementations must not retain p.
type Writer interface {
Write(p []byte) (n int, err error)
}
哇,好简单。要实现 io.Writer 仅仅只要实现一个 Write(p []byte) (n int, err error) 方法就行了,So Easy !!!!
上手开发
还是回到上一章中的 5 个核心问题,我想到这里应该有答案了:
- MessageProducer:用一个函数实现,实际上就是 Write(p []byte),接收 uber-go/zap 投递来的消息内容。
- CriticalSurface 和 RingBuffer: 是最核心的部件,既然要考虑到性能、安全、兼容各种数据类型,同时要有一个 Locker 保证临界面,也要满足 FIFO 模型。思来想去,当然自己也实现了几版,最后还是用 golang 自身的 channel 来完成。
- MessageConsumer:用一个 go 协程来执行从 RingBuffer 循环读取,然后往真正的 os.Stdout/os.StdErr/os.File 中输出。(为什么是一个而不是多个?一个速度就足够快了,同时系统底层 io.Writer 自身也带锁,所以一个能减少锁冲撞。)
TIPS: 这里说说为什么我要选择 golang 自身的 channel 作为 CriticalSurface 和 RingBuffer 的实现体:
- channel 是 golang 官方的代码包,有专门的团队对这个代码质量负责。channel 很早就出来了,Bugs 修复的差不多了,非常的稳定可靠。(也有自己懒了,不想自己写 RingBuffer,然后要考虑各种场景的代码测试。)
- channel 的 “<-” 动作天生就有一个 Locker,有非常好的临界面控制。
- channel 底层是就是一个 RingBuffer 的实现,效率非常不错,而且如果 channel 满了,数据投递动作就会卡住,如果 channel 空了,数据提取动作也会被卡住,这个机制非常棒。
- channel 天生就是一个 FIFO 的模型,非常合适做数据缓冲,解决 Producer 和 Consumer 和速度差这样问题。
有了上面的思路,我的代码架构也基本出来了,结构图如下:
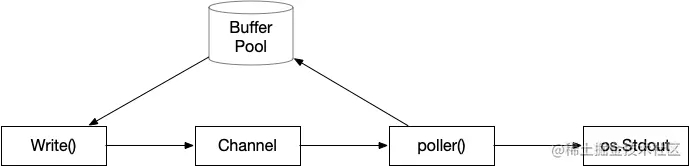
这里我贴出一个实现代码(DEMO 测试用,生产要谨慎重新实现):
const defaultQueueCap = math.MaxUint16 * 8
var QueueIsFullError = errors.New("queue is full")
var DropWriteMessageError = errors.New("message writing failure and drop it")
type Writer struct {
name string
bufferPool *extraBufferPool
writer io.Writer
wg sync.WaitGroup
lock sync.RWMutex
channel chan *extraBuffer
}
func NewBufferWriter(name string, w io.Writer, queueCap uint32) *Writer {
if len(name) <= 0 {
name = "bw_" + utils.GetRandIdString()
}
if queueCap <= 0 {
queueCap = defaultQueueCap
}
if w == nil {
return nil
}
wr := Writer{
name: name,
bufferPool: newExtraBufferPool(defaultBufferSize),
writer: w,
channel: make(chan *extraBuffer, queueCap),
}
wr.wg.Add(1)
go wr.poller(utils.GetRandIdString())
return &wr
}
func (w *Writer) Write(p []byte) (int, error) {
if w.lock.TryRLock() {
defer w.lock.RUnlock()
b := w.bufferPool.Get()
count, err := b.buff.Write(p)
if err != nil {
w.bufferPool.Put(b)
return count, err
}
select {
case w.channel <- b: // channel 内部传递的是 buffer 的指针,速度比传递对象快。
break
default:
w.bufferPool.Put(b)
return count, QueueIsFullError
}
return len(p), nil
} else {
return -1, DropWriteMessageError
}
}
func (w *Writer) Close() {
w.lock.Lock()
close(w.channel)
w.wg.Wait()
w.lock.Unlock()
}
func (w *Writer) poller(id string) {
var (
eb *extraBuffer
err error
)
defer w.wg.Done()
for eb = range w.channel {
_, err = w.writer.Write(eb.buff.Bytes())
if err != nil {
log.Printf("writer: %s, id: %s, error: %s, message: %s", w.name, id,
err.Error(), utils.BytesToString(eb.buff.Bytes()))
}
w.bufferPool.Put(eb)
}
}
然后在 uber-go/zap 中如何使用呢?
import (
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
"os"
"time"
)
func main() {
wr := NewBufferWriter("lee", os.Stdout, 0)
defer wr.Close()
c := zapcore.NewCore(
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig()),
zapcore.AddSync(wr),
zap.NewAtomicLevelAt(zap.DebugLevel),
)
log := zap.New(c)
log.Info("demo log")
time.Sleep(3 * time.Second) // 这里要稍微等待下,因为是异步的输出,log.Info() 执行完毕,日志并没有完全输出到 console
}
Console 输出:
$ go run asynclog.go
{"level":"info","ts":1674808100.0148869,"msg":"demo log"}
输出结果符合逾期
测试代码
为了验证架构和代码质量,这里做了异步输出日志、同步输出日志和不输出日志 3 种情况下,对 gin 封装的 webservice 框架吞吐力的影响。
| # | 测试内容 | Requests/sec |
|---|---|---|
| 1 | 同步输出日志 | 20074.24 |
| 2 | 异步输出日志 | 64197.08 |
| 3 | 不输出日志 | 65551.84 |
同步输出日志
$ wrk -t 10 -c 1000 http://127.0.0.1:8080/xx/
Running 10s test @ http://127.0.0.1:8080/xx/
10 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 12.03ms 14.23ms 202.46ms 89.23%
Req/Sec 2.03k 1.36k 9.49k 59.28%
202813 requests in 10.10s, 100.58MB read
Socket errors: connect 757, read 73, write 0, timeout 0
Requests/sec: 20074.24
Transfer/sec: 9.96MB
异步输出日志
$ wrk -t 10 -c 1000 http://127.0.0.1:8080/xx/
Running 10s test @ http://127.0.0.1:8080/xx/
10 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.75ms 2.43ms 39.94ms 92.68%
Req/Sec 6.48k 3.86k 14.78k 57.11%
648554 requests in 10.10s, 321.62MB read
Socket errors: connect 757, read 79, write 0, timeout 0
Requests/sec: 64197.08
Transfer/sec: 31.84MB
不输出日志
$ wrk -t 10 -c 1000 http://127.0.0.1:8080/xx/
Running 10s test @ http://127.0.0.1:8080/xx/
10 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.69ms 505.13us 9.29ms 77.36%
Req/Sec 6.60k 4.25k 15.31k 56.45%
662381 requests in 10.10s, 328.48MB read
Socket errors: connect 757, read 64, write 0, timeout 0
Requests/sec: 65551.84
Transfer/sec: 32.51MB
总结
通过对上面的工程代码测试,基本实现了 gin + zap 的异步日志输出功能的实现。当然上面的代码仅供小伙伴学习研究用,并不能作为生产代码使用。
从结果来看,golang 的 channel 整体性能还是非常不错。基于 channel 实现的异步日志输出基本于不输出日志的吞吐力和性能相当。
在实际工作中,我们能用 golang 原生库的时候就尽量用,因为 golang 团队在写库的时候,大多数的情况和场景都考虑过,所以没有必自己做一个轮子。安全!安全!安全!
至于 uber-go/zap 团队为什么不愿意实现这样的异步日志输出模型,可能有他们的想法吧。但是我想,不论那种异步日志模型,都存在着程序异常会丢日志的情况。这里再次提醒小伙伴,要慎重选择日志系统模型,切不可以一味追求速度而忽略日志,因为服务日志也是重要的业务数据。
以上就是uber go zap 日志框架支持异步日志输出的详细内容,更多关于uber go zap日志异步输出的资料请关注我们其它相关文章!
相关推荐
-
Go语言k8s kubernetes使用leader election实现选举
目录 一.背景 二.官网代码示例 三.锁的实现 一.背景 在kubernetes的世界中,很多组件仅仅需要一个实例在运行,比如controller-manager或第三方的controller,但是为了高可用性,需要组件有多个副本,在发生故障的时候需要自动切换.因此,需要利用leader election的机制多副本部署,单实例运行的模式.应用程序可以使用外部的组件比如ZooKeeper或Etcd等中间件进行leader eleaction, ZooKeeper的实现是采用临时节点的方案,临时节
-

Google Kubernetes Engine 集群实战详解
目录 GKE 集群介绍 K8s 带来的好处 使用 GKE 编排集群 GKE 集群介绍 Google Kubernetes Engine (GKE) 集群由 Kubernetes 开源集群管理系统提供支持.Kubernetes 为用户提供了与容器集群进行交互的机制.您可以使用 Kubernetes 命令和资源来部署和管理应用.执行管理任务.设置政策,以及监控您部署的工作负载的运行状况. K8s 带来的好处 自动管理 对应用容器进行监控和活跃性探测 自动扩缩 滚动更新 Google Cloud 上的
-
使用client-go工具调用kubernetes API接口的教程详解(v1.17版本)
目录 说明 效果 实现 1.拉取工具源码 2.创建目录结构 查询代码实例 创建deployment资源 更新deployment类型服务 删除deployment类型服务 说明 可以调取k8s API 接口的工具有很多,这里我就介绍下client-go gitlab上client-go项目地址: https://github.com/kubernetes/client-go 这个工具是由kubernetes官方指定维护的,大家可以放心使用 效果 运行完成后,可以直接获取k8s集群信息等 实现 1
-
Golang 依赖注入经典解决方案uber/fx理论解析
目录 开篇 uber/fx provider 声明依赖关系 invoker 应用的启动器 fx.In 封装多个入参 fx.Out 封装多个出参 基于同类型提供多种实现 Annotate 注解器 小结 开篇 今天继续我们的[依赖注入开源解决方案系列], Dependency Injection 业界的开源库非常多,大家可以凭借自己的喜好也业务的复杂度来选型.基于 github star 数量以及方案的全面性,易用性上.推荐这两个: 1.[代码生成]派系推荐大家用 wire, 做的事情非常轻量级,省
-
springboot]logback日志框架配置教程
目录 一.application配置文件实现日志配置 日志格式占位符 二.使用logback-spring.xml实现日志配置 2.1.需求 2.2.需求实现 2.3.测试一下 logback既可以通过application配置文件进行日志的配置,又可以通过logback-spring.xml进行日志的配置.通常情况下,使用全局配置文件application.yml或properties进行配置就足够了,如果您的日志输出需求特别复杂而且需求比较个性化,可以考虑使用logback-spring.x
-
spring boot Slf4j日志框架的体系结构详解
目录 前言 一.五花八门的日志工具包 1.1. 日志框架 1.2.日志门面 1.3日志门面存在的意义 二.日志框架选型 三.日志级别 四.常见术语概念解析 总结 前言 刚刚接触到java log日志的同学可能会被各种日志框架吓到,包括各种日志框架之间的jar总是发生冲突,另很多小伙伴头疼不已.那我们本篇的内容就是将各种java 日志框架发展过程,以及他们之间的关系,以及如何选型来介绍给大家. 一.五花八门的日志工具包 1.1. 日志框架 JDK java.util.logging 包:java.
-
详解MyBatis日志如何做到兼容所有常用的日志框架
前言 日志,在我们开发中是一个非常重要的话题,良好的日志打印可以帮助我们快速的定位问题,可能现在我们开发用到最多的日志框架就是slf4j了,但是日志还有其他很多优秀的框架,比如:Apache Common Log,Log4j,java.util.logging等.MyBatis作为一款优秀的ORM框架,定义了一套统一的日志接口供应用层调用,而底层却利用适配器模式兼容了我们上面所列出来的常用日志框架. MyBatis日志分类 在介绍MyBatis的全局配置文件的时候,我们提到setting内有一个
-
Go日志框架zap增强及源码解读
目录 正文 初始化Logger 打一条Log 小结 增强zap 自定义sink error调用栈 正文 本文包括两部分,一部分是源码解读,另一部分是对zap的增强. 由于zap是一个log库,所以从两方面来深入阅读zap的源码,一个是初始化logger的流程,一个是打一条log的流程. 初始化Logger zap的Logger是一般通过一个Config结构体初始化的,首先看下这个结构体有哪些字段 type Config struct { // 日志Level,因为可以动态更改,所以是atomic
-
zap接收gin框架默认的日志并配置日志归档示例
目录 使用zap接收gin框架默认的日志并配置日志归档 gin默认的中间件 基于zap的中间件 在gin项目中使用zap 使用zap接收gin框架默认的日志并配置日志归档 我们在基于gin框架开发项目时通常都会选择使用专业的日志库来记录项目中的日志,go语言常用的日志库有zap.logrus等. 但是我们该如何在日志中记录gin框架本身输出的那些日志呢? gin默认的中间件 首先我们来看一个最简单的gin项目: func main() { r := gin.Default() r.GET("/h
-
golang日志框架之logrus的使用
golang日志库 golang标准库的日志框架非常简单,仅仅提供了print,panic和fatal三个函数对于更精细的日志级别.日志文件分割以及日志分发等方面并没有提供支持.所以催生了很多第三方的日志库,但是在golang的世界里,没有一个日志库像slf4j那样在Java中具有绝对统治地位.golang中,流行的日志框架包括logrus.zap.zerolog.seelog等. logrus是目前Github上star数量最多的日志库,目前(2018.08,下同)star数量为8119,fo
-
GO语言框架快速集成日志模块的操作方法
目录 前言 zap包的集成 简介 最基础的使用 定制化 进阶封装 前言 在我们的日常开发中, 日志模块永远是最基础且最重要的一个模块, 它可以有效的帮我们发现问题, 定位问题, 最后去解决问题; zap包的集成 简介 zap是一个可以在go项目中进行快速, 结构化且分级的日志记录包, git star数高达16.3k, Git 项目地址, 在各大公司项目中被广泛使用; 最基础的使用 package main import ( "go.uber.org/zap" "time&q
-
详解ABP框架中的日志管理和设置管理的基本配置
日志管理 Server side(服务器端) ASP.NET Boilerplate使用Castle Windsor's logging facility日志记录工具,并且可以使用不同的日志类库,比如:Log4Net, NLog, Serilog... 等等.对于所有的日志类库,Castle提供了一个通用的接口来实现,我们可以很方便的处理各种特殊的日志库,而且当业务需要的时候,很容易替换日志组件. 译者注释:Castle是什么:Castle是针对.NET平台的一个开源项目,从数据访问框架ORM到
-
Java日志框架之logback使用详解
为什么使用logback 记得前几年工作的时候,公司使用的日志框架还是log4j,大约从16年中到现在,不管是我参与的别人已经搭建好的项目还是我自己主导的项目,日志框架基本都换成了logback,总结一下,logback大约有以下的一些优点: 内核重写.测试充分.初始化内存加载更小,这一切让logback性能和log4j相比有诸多倍的提升 logback非常自然地直接实现了slf4j,这个严格来说算不上优点,只是这样,再理解slf4j的前提下会很容易理解logback,也同时很容易用其他日志框架
-
关于log4j2的异步日志输出方式
目录 log4j2的异步日志输出方式 第一种实现异步方式AsyncAppender 第二种实现异步方式AsyncLogger log4j2异步注意事项 log4j2异步类型 小提示 log4j2的异步日志输出方式 使用log4j2的同步日志进行日志输出,日志输出语句与程序的业务逻辑语句将在同一个线程运行. 而使用异步日志进行输出时,日志输出语句与业务逻辑语句并不是在同一个线程中运行,而是有专门的线程用于进行日志输出操作,处理业务逻辑的主线程不用等待即可执行后续业务逻辑. Log4j2中的异步日志