解读Oracle中代替like进行模糊查询的方法instr(更高效)
目录
- 一、简介
- 二、使用说明
- 对应参数描述
- 我们以一些示例讲解使用方法
- 三、instr()与like比较
- instr函数也有三种情况
- 下面通过一个示例说明like 与 instr()的使用比较
- 四、效率对比
- 五、总结
一、简介
相信大家都使用过like进行模糊匹配查询,在oracle中,instr()方法可以用来代替like进行模糊查询,大数据量的时候效率更高。
本文将对instr()的基本使用方法进行详解以及通过示例讲解与like的效率对比。
二、使用说明
instr(sourceString,destString,start,appearPosition)
对应参数描述
instr('源字符串' , '目标字符串' ,'开始位置','第几次出现'),返回目标字符串在源字符串中的位置。
后面两个参数可要可不要。
我们以一些示例讲解使用方法
【a】从开头开始查找第一个‘h’出现的位置
--从开头开始查找第一个‘h'出现的位置
select instr('zhangsan', 'h') as idx from dual; --2
查询结果:

【b】从开头开始查找‘an’在字符串中的位置
--从开头开始查找‘an'在字符串中的位置
select instr('zhangsan','an') idx from dual; --3
查询结果:

【c】从第一个位置开始查找,返回第二次出现‘a’的位置
--从第一个位置开始查找,返回第二次出现‘a'的位置
select instr('zhangsan','a',1,'2') idx from dual; --7
查询结果:

【d】从倒数第一个位置开始,查找第一次出现‘a’的位置
--从倒数第一个位置开始,查找第一次出现‘a'的位置
select instr('zhangsan','a',-1,1) idx from dual; --7
查询结果:

【e】从倒数第一个位置开始,返回第二次出现‘a’的位置
--从倒数第一个位置开始,返回第二次出现‘a'的位置
select instr('zhangsan','a',-1,2) idx from dual; --3
查询结果:

三、instr()与like比较
instr函数也有三种情况
- a. instr(字段,'关键字') > 0 相当于 字段like '%关键字%': 表示在字符串中包含‘关键字’
- b. instr(字段,'关键字') = 1 相当于 字段like '关键字%' 表示以‘关键字’开头的字符串
- c. instr(字段,'关键字') = 0 相当于 字段not like '%关键字%' 表示在字符串中不包含‘关键字’
下面通过一个示例说明like 与 instr()的使用比较
【a】使用like进行模糊查询
with temp1 as ( select 'zhangsan' as name from dual), temp2 as ( select 'zhangsi' as name from dual), temp3 as ( select 'xiaoming' as name from dual), temp4 as ( select 'xiaohong' as name from dual), temp5 as ( select 'zhaoliu' as name from dual) select * from (select * from temp1 union all select * from temp2 union all select * from temp3 union all select * from temp4 union all select * from temp5) res where res.name like '%zhang%'
查询字符串中包含‘zhang’的结果:

【b】使用instr()进行模糊查询
(1) 查询字符串中包含‘zhang’的结果:
with temp1 as ( select 'zhangsan' as name from dual), temp2 as ( select 'zhangsi' as name from dual), temp3 as ( select 'xiaoming' as name from dual), temp4 as ( select 'xiaohong' as name from dual), temp5 as ( select 'zhaoliu' as name from dual) select * from (select * from temp1 union all select * from temp2 union all select * from temp3 union all select * from temp4 union all select * from temp5) res where instr(res.name,'zhang') > 0;
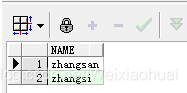
(2) 查询字符串中不包含‘zhang’的结果:
with temp1 as ( select 'zhangsan' as name from dual), temp2 as ( select 'zhangsi' as name from dual), temp3 as ( select 'xiaoming' as name from dual), temp4 as ( select 'xiaohong' as name from dual), temp5 as ( select 'zhaoliu' as name from dual) select * from (select * from temp1 union all select * from temp2 union all select * from temp3 union all select * from temp4 union all select * from temp5) res where instr(res.name,'zhang') = 0;
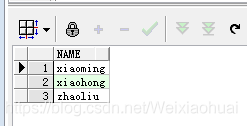
(3) 查询以‘zhang’开头的字符串:
with temp1 as ( select 'zhangsan' as name from dual), temp2 as ( select 'zhangsi' as name from dual), temp3 as ( select 'sizhangsan' as name from dual), temp4 as ( select 'xiaohong' as name from dual), temp5 as ( select 'zhaoliu' as name from dual) select * from (select * from temp1 union all select * from temp2 union all select * from temp3 union all select * from temp4 union all select * from temp5) res where instr(res.name,'zhang') = 1;

(4)instr与like特殊用法
select id, name from users where instr('a, b', id) > 0;
--等价于
select id, name
from users
where id = a
or id = b;
--等价于
select id, name from users where id in (a, b);
四、效率对比
【a】使用plsql创建一张十万条数据测试数据表,同时为需要进行模糊查询的列增加索引
--创建10万条测试数据 create table test_instr_like as select rownum as id,'zhangsan' as name from dual connect by level <= 100000; --name列建立索引 create index idx_tb_name on test_instr_like(name);
【b】使用like进行模糊查询
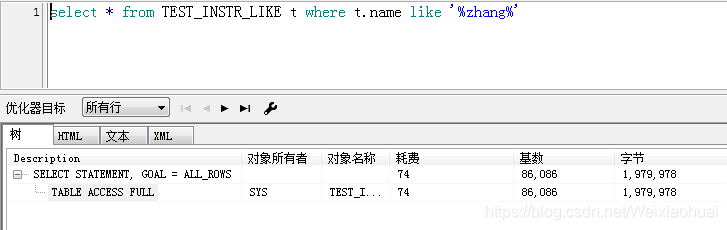
select * from TEST_INSTR_LIKE t where t.name like '%zhang%'
总耗时: 60秒

【c】使用instr进行模糊查询
select * from TEST_INSTR_LIKE t where instr(t.name, 'zhang') > 0;
总耗时:50秒

由图可见,instr查询的速度确实比like快一些,但是,看执行计划的话,instr却比like耗时一点。如下图:

五、总结
以上是对instr基本使用方法的讲解以及通过示例对比了like与instr的效率,在进行模糊查询的时候,能用instr的话就尽量用instr,毕竟数据量大的时候还是有一点优势的,本文是笔者对like以及instr的一些总结和见解,仅供大家学习参考,也希望大家多多支持我们。
相关推荐
-
Oracle 模糊查询及like用法
目录 Oracle 模糊查询like用法 一.where子句中使用like关键字 1._ 2.[] 3.[^] 二.在Oracle中提供了instr(strSource,strTarget)函数 Oracle 模糊查询like用法 一.where子句中使用like关键字 我们可以在where子句中使用like关键字来达到Oracle模糊查询的效果:在Where子句中,可以对datetime.char.varchar字段类型的列用Like关键字配合通配符来实现模糊查询, 以下是可使用的通配符: %
-
Oracle中的instr()函数应用及使用详解
1.instr()函数的格式 (俗称:字符查找函数) 格式一:instr( string1, string2 ) // instr(源字符串, 目标字符串) 格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) // instr(源字符串, 目标字符串, 起始位置, 匹配序号) 解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检
-
Oracle中Like与Instr模糊查询性能大比拼
instr(title,'手册')>0 相当于 title like '%手册%' instr(title,'手册')=1 相当于 title like '手册%' instr(title,'手册')=0 相当于 title not like '%手册%' t表中将近有1100万数据,很多时候,我们要进行字符串匹配,在SQL语句中,我们通常使用like来达到我们搜索的目标.但经过实际测试发现,like的效率与instr函数差别相当大.下面是一些测试结果: SQL> set timing on
-

解读Oracle中代替like进行模糊查询的方法instr(更高效)
目录 一.简介 二.使用说明 对应参数描述 我们以一些示例讲解使用方法 三.instr()与like比较 instr函数也有三种情况 下面通过一个示例说明like 与 instr()的使用比较 四.效率对比 五.总结 一.简介 相信大家都使用过like进行模糊匹配查询,在oracle中,instr()方法可以用来代替like进行模糊查询,大数据量的时候效率更高. 本文将对instr()的基本使用方法进行详解以及通过示例讲解与like的效率对比. 二.使用说明 instr(sourceString
-
springboot使用JPA时间类型进行模糊查询的方法
这个问题是我自己开发中遇到的问题 数据库使用的是mysql5.6 字段名称为checkingTime 类型为timestamp 显而易见 存到库中的是保留6位毫秒 即yyyy-MM-dd HH:mm:ss.ssssss 此时需求是精确到分钟的相同时间 不进行存储 这时候就需要进行模糊查询 搜了一圈百度 并没有什么好用的方法 我的bean类定义的是date类型 使用注解将类型更改为timestamp 存入库中 其实在做模糊查询的时候 只需要向持久层传入String类型参数即可 我的做
-
jQuery实现模糊查询的方法分析
本文实例讲述了jQuery实现模糊查询的方法.分享给大家供大家参考,具体如下: 需求:list列表内容很多,用户需要找出列表内容中的某些条目,只有当与用户输入值匹配的条目才显示出来.(后台无分页,直接异步接口返回数据添加形成的内容列表) 虽然可以通过传参再调用查询出来,但这里主要记录的是前端处理进行模糊查询而无需再次调用接口的实现方法. html部分: <div class="search-form"> <input type="text" pla
-
Python使用cx_Oracle模块将oracle中数据导出到csv文件的方法
本文实例讲述了Python使用cx_Oracle模块将oracle中数据导出到csv文件的方法.分享给大家供大家参考.具体实现方法如下: # Export Oracle database tables to CSV files # FB36 - 201007117 import sys import csv import cx_Oracle connection = raw_input("Enter Oracle DB connection (uid/pwd@database) : "
-
在php7中MongoDB实现模糊查询的方法详解
前言 在实际开发中, 有不少的场景需要使用到模糊查询, MongoDB shell 模糊查询很简单: db.collection.find({'_id': /^5101/}) 上面这句就是查询_id以'5101'开始的内容. 在老的MogoDB中模糊查询挺简单的,这里简单记录下模糊查询的操作方式: 命令行下: db.letv_logs.find({"ctime":/uname?/i}); php操作 $query=array("name"=>new Mongo
-
sqlserver和oracle中对datetime进行条件查询的一点区别小结
首先,看一下sql server,之前我们都通过前台用户选择一个起始时间和一个结束时间(以日为最小单位),然后来作为条件进行查询,如果直接通过"between starttime and endtime"来作为条件的话,发现会自动将"2009-06-17"转化为" 2009-06-17 00:00:00",于是如下查询条件" between '2009-06-16' and '2009-06-17'",只能得到16日的数据,1
-
简介iOS开发中应用SQLite的模糊查询和常用函数
SQLite模糊查询 一.示例 说明:本文简单示例了SQLite的模糊查询 1.新建一个继承自NSObject的模型 该类中的代码: 复制代码 代码如下: // // YYPerson.h // 03-模糊查询 // // Created by apple on 14-7-27. // Copyright (c) 2014年 wendingding. All rights reserved. // #import <Foundation/Foundation.h> @interface
-
ASP.NET中利用存储过程实现模糊查询
一.建立存储过程 在MSSQL中的Northwind数据库中为employess表新建存储过程(作用按LastName进行模糊查询): CREATE PROCEDURE Employess_Sel @lastname nvarchar (20)ASselect lastname from Employees where lastname like '%' + @lastname + '%'GO 二.窗体设计 1.新建ASP.NET Web应用程序,命名为WebSql,选择保存路径然后点击确定.
-
Oracle中获取执行计划的几种方法分析
1. 预估执行计划 - Explain PlanExplain plan以SQL语句作为输入,得到这条SQL语句的执行计划,并将执行计划输出存储到计划表中. 首先,在你要执行的SQL语句前加explain plan for,此时将生成的执行计划存储到计划表中,语句如下:explain plan for SQL语句然后,在计划表中查询刚刚生成的执行计划,语句如下:select * from table(dbms_xplan.display);注意:Explain plan只生成执行计划,并不会真正
-
Node.js对MongoDB数据库实现模糊查询的方法
前言 模糊查询是数据库的基本操作之一,实现对给定的字符串是否与指定的模式进行匹配.如果字符完全匹配,可以用=等号表示,如果部分匹配可认为是一种模糊查询.在关系型数据中,通过SQL使用like '%fens%'的语法.那么在mongodb中我们应该如何实现模糊查询的效果呢. 目录 mongodb模糊查询 nodejs通过mongoose的模糊查询 1. mongodb模糊查询 我们打开mongodb,以name文字字段进行测试. 精确查询 当{'name':'未来警察'}时,精确匹配到一条记录.