Flow如何解决背压问题的方法详解
目录
- 前言
- 关于背压(BackPressure)
- 背压问题是什么
- 定义背压策略
- Flow的背压机制
- 模拟背压问题
- 背压处理方式
- 使用buffer进行缓存收集
- 使用conflate解决
- 使用collectLatest解决
- 小结
前言
随着时间的推移,越来越多的主流应用已经开始全面拥抱Kotlin,协程的引入,Flow的诞生,给予了开发很多便捷,作为协程与响应式编程结合的流式处理框架,一方面它简单的数据转换与操作符,没有繁琐的操作符处理,广受大部分开发的青睐,另一方面它并没有响应式编程带来的背压问题(BackPressure)的困扰;接下来,本文将会就Flow如何解决背压问题进行探讨
关于背压(BackPressure)
背压问题是什么
首先我们要明确背压问题是什么,它是如何产生的?简单来说,在一般的流处理框架中,消息的接收处理速度跟不上消息的发送速度,从而导致数据不匹配,造成积压。如果不及时正确处理背压问题,会导致一些严重的问题
- 比如说,消息拥堵了,系统运行不畅从而导致崩溃
- 比如说,资源被消耗殆尽,甚至会发生数据丢失的情况
如下图所示,可以直观了解背压问题的产生,它在生产者的生产速率高于消费者的处理速率的情况下出现

定义背压策略
既然知道了背压问题我们已经知道是如何产生的,就要去尝试如何正确处理它,大致意思是,如果你有一个流,你需要一个缓冲区,以防数据产生的速度快于消耗的速度,所以往往就会针对这个背压策略进行些讨论
- 定义的中间缓冲区需要多大才比较合适?
- 如果缓冲区数据已满了,我们怎么样处理新的事件?
对于以上问题,通过学习Flow里的背压策略,相信可以很快就知道答案了
Flow的背压机制
由于Flow是基于协程中使用的,它不需要一些巧妙设计的解决方案来明确处理背压,在Flow中,不同于一些传统的响应式框架,它的背压管理是使用Kotlin挂起函数suspend实现的,看下源码你会发现,它里面所有的函数方法都是使用suspend修饰符标记,这个修饰符就是为了暂停调度者的执行不阻塞线程。因此,Flow<T>在同一个协程中发射和收集时,如果收集器跟不上数据流,它可以简单地暂停元素的发射,直到它准备好接收更多。看到这,是不是觉得有点难懂.......
简单举个例子,假设我们拥有一个烤箱,可以用来烤面包,由于烤箱容量的限制,一次只能烤4个面包,如果你试着一次烤8个面包,会大大加大烤箱的承载负荷,这已经远远超过了它的内存使用量,很有可能会因此烧掉你的面包。
模拟背压问题
回顾下之前所说的,当我们消耗的速度比生产的速度慢的时候,就会产生背压,下面用代码来模拟下这个过程
首先先创建一个方法,用来每秒发送元素
fun currentTime() = System.currentTimeMillis()
fun threadName() = Thread.currentThread().name
var start: Long = 0
fun createEmitter(): Flow<Int> =
(1..5)
.asFlow()
.onStart { start = currentTime() }
.onEach {
delay(1000L)
print("Emit $it (${currentTime() - start}ms) ")
}
接着需要收集元素,这里我们延迟3秒再接收元素, 延迟是为了夸大缓慢的消费者并创建一个超级慢的收集器。
fun main() {
runBlocking {
val time = measureTimeMillis {
createEmitter().collect {
print("\nCollect $it starts ${start - currentTime()}ms")
delay(3000L)
println(" Collect $it ends ${currentTime() - start}ms")
}
}
print("\nCollected in $time ms")
}
}
看下输出结果,如下图所示
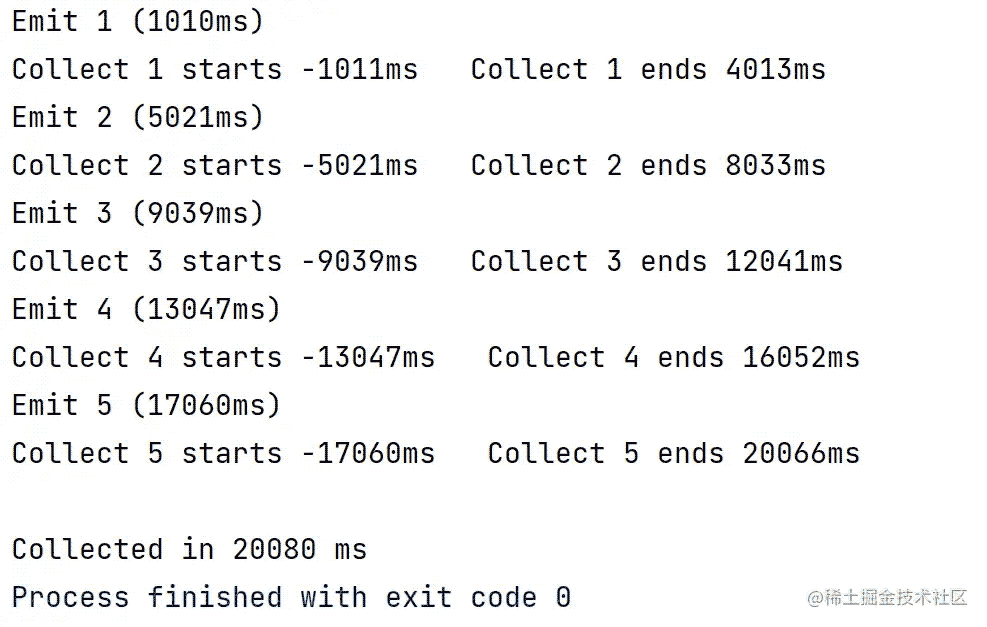
这样整个过程下来,大概需要20多秒才能结束,这里我们模拟了接收元素比发送元素慢的情况,因此就需要一个背压机制,而这正是Flow本质中的,它并不需要另外的设计来解决背压
背压处理方式
使用buffer进行缓存收集
为了使缓冲和背压处理正常工作,我们需要在单独的协程中运行收集器。这就是.buffer()操作符进来的地方,它是将所有发出的项目发送Channel到在单独的协程中运行的收集器。
public fun <T> Flow<T>.buffer(
capacity: Int = BUFFERED,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): Flow<T>
它还为我们提供了缓冲功能,我们可以指定capacity我们的缓冲区和处理策略onBufferOverflow,所以当Buffer溢出的时候,它为我们提供了三个选项
enum BufferOverflow {
SUSPEND,
DROP_OLDEST,
DROP_LATEST
}
- 默认使用
SUSPEND:会将当前协程挂起,直到缓冲区中的数据被消费了 DROP_OLDEST:它会丢弃最老的数据DROP_LATEST: 它会丢弃最新的数据
好的,我们回到上文所展示的模拟示例,这时候我们可以加入缓冲收集buffer,不指定任何参数,这样默认就是使用SUSPEND,它会将当前协程进行挂起

此时当收集器繁忙的时候,程序就开始缓冲,并在第一次收集方法调用结束的时候,两次发射后再次开始收集,此时流程的耗时时长缩短到大约16秒就可以执行完毕,如下图所示输出结果

使用conflate解决
conflate操作符于Channel中的Conflate模式是一直的,新数据会直接覆盖掉旧数据,它不设缓冲区,也就是缓冲区大小为 0,丢弃旧数据,也就是采取 DROP_OLDEST 策略,那么不就等于buffer(0,BufferOverflow.DROP_OLDEST),可以看下它的源码可以佐证我们的判断
public fun <T> Flow<T>.conflate(): Flow<T> = buffer(CONFLATED)
在某些情况下,由于根本原因是解决生产消费速率不匹配的问题,我们需要做一些取舍的操作,conflate将丢弃掉旧数据,只有在收集器空闲之前发出的最后一个元素才被收集,将上文的模拟实例改为conflate执行,你会发现我们直接丢弃掉了2和4,或者说新的数据直接覆盖掉了它们,整个流程只需要10秒左右就执行完成了

使用collectLatest解决
通过官方介绍,我们知道collectLatest作用在于当原始流发出一个新的值的时候,前一个值的处理将被取消,也就是不会被接收, 和conflate的区别在于它不会用新的数据覆盖,而是每一个都会被处理,只不过如果前一个还没被处理完后一个就来了的话,处理前一个数据的逻辑就会被取消
suspend fun <T> Flow<T>.collectLatest(action: suspend (T) -> Unit)
还是上文的模拟实例,这里我们使用collectLatest看下输出结果:
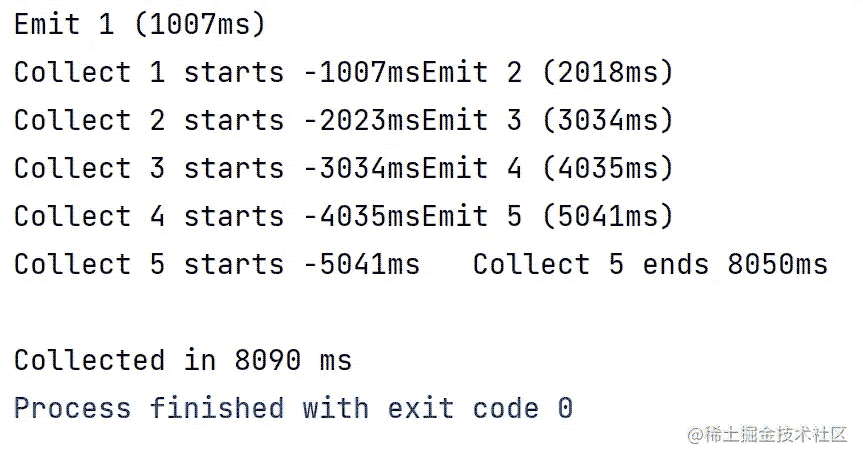
这样也是有副作用的,如果每个更新都非常重要,例如一些视图,状态刷新,这个时候就不必要用collectLatest ; 当然如果有些更新可以无损失的覆盖,例如数据库刷新,就可以使用到collectLatest,具体详细的使用场景,还需要靠开发者自己去衡量选择使用
小结
对于Flow可以说不需要额外提供什么巧妙的方式解决背压问题,Flow的本质,亦或者说Kotlin协程本身就已经提供了相应的解决方案;开发者只需要在不同的场景中选择正确的背压策略即可。总的来说,它们都是通过使用Kotlin挂起函数suspend,当流的收集器不堪重负时,它可以简单地暂停发射器,然后在准备好接受更多元素时恢复它。
关于挂起函数suspend这里就不过多赘述了,只需要明白的一点是它与传统的基于线程的同步数据管道中背压管理非常相似,无非就是,缓慢的消费者通过阻塞生产者的线程自动向生产者施加背压,简单来说,suspend通过透明地管理跨线程的背压而不阻塞它们,将其超越单个线程并进入异步编程领域。
以上就是Flow如何解决背压问题的方法详解的详细内容,更多关于Flow 解决背压问题的资料请关注我们其它相关文章!
相关推荐
-

Flowable 设置流程变量的四种方式详解
目录 引言 1. 为什么需要流程变量 2. 流程变量的分类 3. 全局流程变量 3.1 启动时设置 3.2 通过 Task 设置 3.3 完成任务时设置 3.4 通过流程设置 4. 本地流程变量 4.1 通过 Task 设置 5. 临时流程变量 引言 在之前的文章中,松哥也有和小伙伴们使用过流程变量,然而没有和大家系统的梳理过流程变量的具体玩法以及它对应的数据表详情,今天我们就来看看 Flowable 中流程变量的详细玩法. 1. 为什么需要流程变量 首先我们来看看为什么需要流程变量. 举一个简
-
Tensorflow高性能数据优化增强工具Pipeline使用详解
目录 安装方法 功能 高级用户部分 用例1,为训练创建数据Pipeline 用例2,为验证创建数据Pipeline 初学者部分 Keras 兼容性 配置 增强: GridMask MixUp RandomErase CutMix Mosaic CutMix , CutOut, MixUp Mosaic Grid Mask 安装方法 给大家介绍一个非常好用的TensorFlow数据pipeline工具. 高性能的Tensorflow Data Pipeline,使用SOTA的增强和底层优化. pi
-
绘制flowable 流程图的Vue 库使用详解
目录 引言 workflow-bpmn-modeler 注册 bpmnModeler 组件 muheflow-bpmn-modeler 引言 之前松哥发了一篇文章和小伙伴们介绍了前端的 bpmn.js 这个库,利用这个库我们可以自己将绘制流程图的功能嵌入到我们的项目中. 然而,这个库默认是给 Camunda 设计的,所以画出来的流程图导出来的 XML 文件无法直接使用,必须要做一些深度定制,才能将 XML 文件转为 Flowable 流程引擎可用的 XML 文件.这个深度定制太太太麻烦了. 所以
-
Flowable执行完毕的流程查找方法
目录 正文 1. 历史流程信息 2. 历史任务查询 3. 历史活动查询 4. 历史变量查询 5. 历史日志查询 6. 历史权限查询 7. 自定义查询 SQL 8. 历史数据记录级别 正文 @[toc]在之前的文章中松哥和小伙伴们聊过,正在执行的流程信息是保存在以 ACT_RU_ 为前缀的表中,执行完毕的流程信息则保存在以 ACT_HI_ 为前缀的表中,也就是流程历史信息表,当然这个历史信息表继续细分的话,还有好多种,今天我们就来聊一聊这个话题. 假设我有如下一个流程: 当这个流程执行完毕后,以
-
图解 Kotlin SharedFlow 缓存系统及示例详解
目录 前言 replay extraBufferCapacity onBufferOverflow SharedFlow Buffer 前言 Kotlin 为我们提供了两种创建“热流”的工具:StateFlow 和 SharedFlow.StateFlow 经常被用来替代 LiveData 充当架构组件使用,所以大家相对熟悉.其实 StateFlow 只是 SharedFlow 的一种特化形式,SharedFlow 的功能更强大.使用场景更多,这得益于其自带的缓存系统,本文用图解的方式,带大家更
-
Flow如何解决背压问题的方法详解
目录 前言 关于背压(BackPressure) 背压问题是什么 定义背压策略 Flow的背压机制 模拟背压问题 背压处理方式 使用buffer进行缓存收集 使用conflate解决 使用collectLatest解决 小结 前言 随着时间的推移,越来越多的主流应用已经开始全面拥抱Kotlin,协程的引入,Flow的诞生,给予了开发很多便捷,作为协程与响应式编程结合的流式处理框架,一方面它简单的数据转换与操作符,没有繁琐的操作符处理,广受大部分开发的青睐,另一方面它并没有响应式编程带来的背压问题
-
解决JTable排序问题的方法详解
JTable的排序是一个让人头疼的问题,Sun没有为排序这个最常用的功能提供类.但是近日翻看Sun官方java的tutorial,却发现其在文档中提供了这个类的实现,使用非常简单!使用方法示例: 复制代码 代码如下: TableSorter sorter = new TableSorter(new MyTableModel()); //ADDED THIS//JTable table = new JTable(new MyTableModel()); //OLDJTable table = ne
-
YUM解决RPM包安装依赖关系及yum工具介绍本地源配置方法详解
1.背景概述 在实际生产环境下,对于在linux系统上安装rpm包,主要面临两个实际的问题 1)安装rpm包过程中,不断涌现的依赖关系问题,导致需要按照提示或者查询资料,手工安装更多的包 2)由于内外网的隔离,无法连接外网的yum源 鉴于上述因此,本文将详细介绍,yum工具以及配置本地yum源的方法 2.yum工具简介 •yum工具作为rpm包的软件管理器,可以进行rpm包的安装.升级以及删除等日常管理工作,而且对于rpm包之间的依赖关系可以自动分析,大大简化了rpm包的维护成本. •yum工具
-
FileZilla Server搭建FTP服务器配置及425错误与TLS警告解决方法详解
我们为大家提供FileZilla下载链接: FileZilla 客户端:FileZilla_3.24.0_win64-setup.exe: FileZilla Server服务端绿色汉化版:FileZilla_Server-0_9_59.exe: 在服务器上安装并配置服务端: 安装过程这里不再赘述,一直下一步,在跳出弹窗时勾选"Always connect to this server",然后点击"Connect"即可(密码可自行设置或者为空): 默认安装完会有如下
-
python爬虫泛滥的解决方法详解
我们可以把互联网上搬运数据的程序看成小蚂蚁,它们需要采集不同的食物带回洞里存储.但是大家也知道白蚁泛滥的事件,在我们的网络环境里,如果爬虫都集中在某几个位置,最直接的结果就是这个网站的拥挤.对于我们这些网站访问者而言也不是好事情,首先网页的页面会被卡住.网站的管理人员面对爬虫过多,这时候就要进行一系列的限制措施了,这里小编分了两个大的应对方向,从不同的角度进 行分析爬虫过多的解决思路. 一.识别爬虫 1. HTTP请求头 这算是最基础的网络爬虫识别了,正常的网络访问者都是通过浏览器对网站进行访问
-
php生成唯一uid的解决方法详解
目录 一.生成唯一uuid 二.生成唯一uid 三.生成唯一uid的正确方法 补充 一.生成唯一uuid 看到某些人会用uuid去代替用户的uid 从代码中可以看出,通过unique生成一个以毫秒级时间戳为前缀的字符后md5加密 再通过分隔符进行分割后得到uuid 这种方式虽然极大程度的避免了uid的重复 但是生成的uid太长,足足36个字符,而且是混杂英文和数字符号的,可读性很差 而一般的uid中都是纯数值组成的 <?php function generateUUid($strtoupper
-
Redis解决Session共享问题的方法详解
企业项目中,一般都是将项目部署到多台服务器上,用nginx做负载均衡.这样可以减轻单台服务器的压力,不过这样也带来一些问题,例如之前单机部署的话,session存取都是直接了当的,因为请求就只到这一台服务器上,不需要考虑数据共享.接下来分别用8000和8001端口启动同一个项目,做一个简单演示: 测试接口代码: package com.wl.standard.controller; import cn.hutool.core.util.StrUtil; import com.wl.standar
-
PHP内存溢出的解决方法详解
目录 1.处理数组时出现内存溢出 2.使用sql查询数据,查出来很多,导致内存溢出 3.假定日志中存放的记录数为500000条,那么解决方案如下 4.上传excel文件时,出现内存溢出的情况 什么是内存溢出 内存溢出是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于虚拟机能提供的最大内存. 引起内存溢出的原因有很多种,常见的有以下几种: 1 内存中加载的数据量过于庞大,如一次从数据库取出过多数据: 2 集合类中有对对象的引用,使用完后未清空: 3 代码中存在死循环
-
Spring循环依赖的解决方法详解
目录 什么是循环依赖: Spring实例Bean的本质 循环依赖主要场景 什么情况下循环依赖可以被解决 解决方式 说明:spring如何解决循环依赖,是面试中经常问到的题目,今天我们就来分享一下spring是如何解决循环依赖问题的. 什么是循环依赖: 我们先来看看官方文档的说法: 通俗来讲,就是A依赖B或者B依赖A,或者C依赖自己本身,或是三个以上,例如A依赖B,B依赖C,C又依赖A.如下图: Spring实例Bean的本质 Spring在实例化一个bean的时候,是首先递归的实例化其所依赖的所
-
python编程之requests在网络请求中添加cookies参数方法详解
哎,好久没有学习爬虫了,现在想要重新拾起来.发现之前学习爬虫有些粗糙,竟然连requests中添加cookies都没有掌握,惭愧.废话不宜多,直接上内容. 我们平时使用requests获取网络内容很简单,几行代码搞定了,例如: import requests res=requests.get("https://cloud.flyme.cn/browser/index.jsp") print res.content 你没有看错,真的只有三行代码.但是简单归简单,问题还是不少的. 首先,这