python pandas 解析(读取、写入)CSV 文件的操作方法
目录
- 1. 使用 pandas 读取 CSV 文件
- 2. 使用 pandas 写入 CSV 文件
1. 使用 pandas 读取 CSV 文件
原始数据包含了公司员工的数据:
| Name | Hire Date | Salary | Sick Days remaining |
|---|---|---|---|
| Graham Chapman | 03/15/14 | 50000.00 | 10 |
| John Cleese | 06/01/15 | 65000.00 | 8 |
| Eric Idle | 05/12/14 | 45000.00 | 10 |
| Terry Jones | 11/01/13 | 70000.00 | 3 |
| Terry Gilliam | 08/12/14 | 48000.00 | 7 |
| Michael Palin | 05/23/13 | 66000.00 | 8 |
将 CSV 文件读入 pandas DataFrame 快速而直接:
import pandas
df = pandas.read_csv('hrdata.csv')
print(df)
就这样简单:仅仅三行代码,而且其中只有一行真正有用。pandas.read_csv() 打开、分析并读取提供的 CSV 文件,并将数据存储在 DataFrame 中,打印 DataFrame 会产生以下输出:
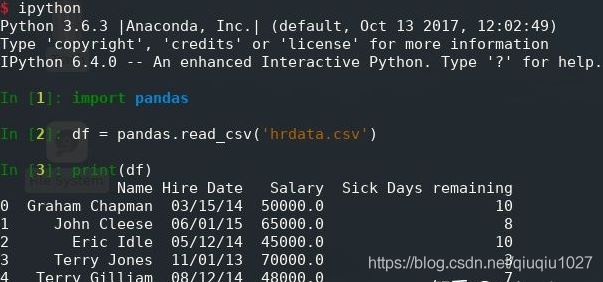
以下是值得注意的几点:
首先,pandas 识别到 CSV 的第一行包含列名,并自动使用它们。
但是,pandas 也在 DataFrame 中使用从零开始的整数索引,那是因为没有告诉它我们的索引应该是什么。
此外,如果查看列的数据类型,会看到 pandas 已将 Salary and Sick Days 剩余列正确转换为数字,但 Hire Date 列仍然是 String,这在交互模式下很容易确认:

让我们一次解决这些问题,要使用其他列作为 DataFrame 的索引,添加 index_col 可选参数:
df2 = pandas.read_csv('hrdata.csv', index_col='Name')
print(df2)
现在,Name 字段就是我们的 DataFrame 索引:
接下来,让我们修复「Hire Date」字段的数据类型。可以使用 parse_dates 可选参数强制pandas 将数据作为日期读取,该参数定义为要作为日期处理的列名列表:
df3 = pandas.read_csv('hrdata.csv', index_col='Name', parse_dates=['Hire Date'])
print(df3)
注意输出的差异:
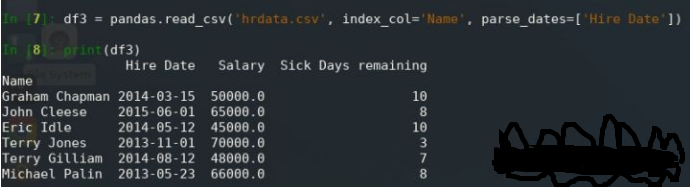
现在日期格式正确,可以在交互模式下轻松确认:
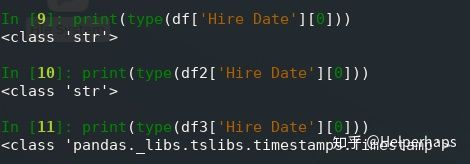
如果 CSV 文件的第一行中没有列名,则可以使用 names 可选参数来提供列名的列表。 如果要覆盖第一行中提供的列名,也可以使用此选项。 在这种情况下,还必须使用header = 0可选参数告诉 pandas.read_csv()忽略现有列名:
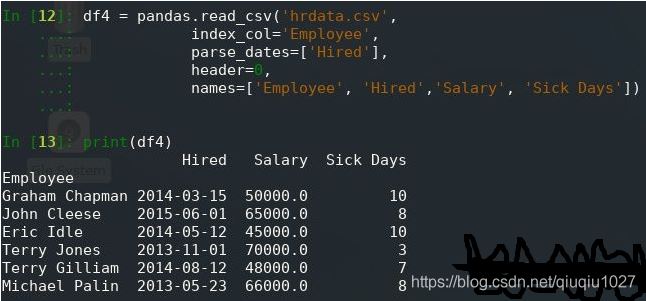
df4 = pandas.read_csv('hrdata.csv',
index_col='Employee',
parse_dates=['Hired'],
header=0,
names=['Employee', 'Hired','Salary', 'Sick Days'])
print(df4)
请注意,由于列名称已更改,因此还必须更改index_col和parse_dates可选参数中指定的列,现在这会产生以下输出:
2. 使用 pandas 写入 CSV 文件
当然,如果无法将数据从 pandas 中输出,那 pandas 可能没有多大好处。将 DataFrame 写入CSV 文件就像读取一个文件一样简单。下面让我们将带有新列名称的数据写入新的 CSV 文件:
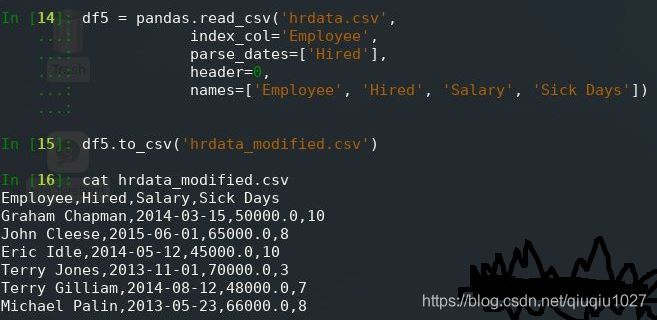
df5 = pandas.read_csv('hrdata.csv',
index_col='Employee',
parse_dates=['Hired'],
header=0,
names=['Employee', 'Hired', 'Salary', 'Sick Days'])
df5.to_csv('hrdata_modified.csv')
此代码与上述读取代码之间的唯一区别是 print(df) 替换为 df.to_csv(),新的 CSV 文件如下所示:
参考此文章连接
到此这篇关于python pandas 解析(读取、写入) CSV 文件的文章就介绍到这了,更多相关python pandas 解析CSV 文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
python 使用pandas读取csv文件的方法
目录 pandas读取csv文件的操作 1. 读取csv文件 在这里记录一下,python使用pandas读取文件的方法用到pandas库的read_csv函数 # -*- coding: utf-8 -*- """ Created on Mon Jan 24 16:48:32 2022 @author: zxy """ # 导入包 import numpy as np import pandas as pd import matplotlib.
-
Python使用pandas导入csv文件内容的示例代码
目录 使用pandas导入csv文件内容 1. 默认导入 2. 指定分隔符 3. 指定读取行数 4. 指定编码格式 5. 列标题与数据对齐 使用pandas导入csv文件内容 1. 默认导入 在Python中导入.csv文件用的方法是read_csv(). 使用read_csv()进行导入时,指定文件名即可 import pandas as pd df = pd.read_csv(r'G:\test.csv') print(df) 2. 指定分隔符 read_csv()默认文件中的数据都是以逗号
-

python读写数据读写csv文件(pandas用法)
python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法.Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能. 一.pandas读取csv文件 数据处理过程中csv文件用的比较多. import pandas as pd data = pd.read_csv('F:/Zhu/test/test.csv') 下面看一下pd.read_csv常用的参数: panda
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
python pandas库读取excel/csv中指定行或列数据
目录 引言 1.根据index查询 2.已知数据在第几行找到想要的数据 3.根据条件查询找到指定行数据 4.找出指定列 5.找出指定的行和指定的列 6.在规定范围内找出符合条件的数据 总结 引言 关键!!!!使用loc函数来查找. 话不多说,直接演示: 有以下名为try.xlsx表: 1.根据index查询 条件:首先导入的数据必须的有index 或者自己添加吧,方法简单,读取excel文件时直接加index_col 代码示例: import pandas as pd #导入pandas库 ex
-
python pandas 解析(读取、写入)CSV 文件的操作方法
目录 1. 使用 pandas 读取 CSV 文件 2. 使用 pandas 写入 CSV 文件 1. 使用 pandas 读取 CSV 文件 原始数据包含了公司员工的数据: Name Hire Date Salary Sick Days remaining Graham Chapman 03/15/14 50000.00 10 John Cleese 06/01/15 65000.00 8 Eric Idle 05/12/14 45000.00 10 Terry Jones 11/01/13
-
Python实现读取及写入csv文件的方法示例
本文实例讲述了Python实现读取及写入csv文件的方法.分享给大家供大家参考,具体如下: 新建csvData.csv文件,数据如下: 具体代码如下: # coding:utf-8 import csv # 读取csv文件方式1 csvFile = open("csvData.csv", "r") reader = csv.reader(csvFile) # 返回的是迭代类型 data = [] for item in reader: print(item) dat
-
在python中读取和写入CSV文件详情
目录 前言 1.导入CSV库 2.对CSV文件进行读写 2.1 用列表形式写入CSV文件 2.2 用列表形式读取CSV文件 2.3 用字典形式写入csv文件 2.4 用字典形式读取csv文件 结语 前言 CSV(Comma-Separated Values)即逗号分隔值,一种以逗号分隔按行存储的文本文件,所有的值都表现为字符串类型(注意:数字为字符串类型).如果CSV中有中文,应以utf-8编码读写. 1.导入CSV库 python中对csv文件有自带的库可以使用,当我们要对csv文件进行读写的
-
Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题
先举个例子,分别以不指定编码.指定编码为 utf-8.指定编码为 utf-8-sig 三种方式来做比较,再将写入 csv 文件和 txt 文件来做个对比 一.不指定编码方式,直接存入 csv 文件 import csv with open('test.csv', 'w') as fp: writer = csv.writer(fp) writer.writerow(['汉语', '俄语', '韩语', '日语', '英语']) writer.writerow(['爱你', 'люблю тебя
-
Python实现PDF文字识别提取并写入CSV文件
目录 1.前言 2.需求描述 3.开始动手动脑 3.1安装相关第三方包 3.2导入需要用到的第三方库 3.3读取pdf文件,并识别内容 3.4对识别的数据进行处理,写入csv文件 总结 1. 前言 扫描件一直受大众青睐,任何纸质资料在扫描之后进行存档,想使用时手机就能打开,省心省力.但是扫描件的优点也恰恰造成了它的一个缺点,因为是通过电子设备扫描,所以出来的是图像,如果想要处理文件上的内容,直接操作是无法实现的. 那要是想要引用其中的内容怎么办呢?别担心,Python帮你解决问题. 2. 需求描
-
Python写入CSV文件的方法
本文实例讲述了Python写入CSV文件的方法.分享给大家供大家参考.具体如下: # _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import csv csvfile = file('csvtest.csv', 'wb') writer = csv.writer(csvfile) writer.writerow(['id', 'url', 'keywords']) data = [ ('1', 'http
-
Python导出数据到Excel可读取的CSV文件的方法
本文实例讲述了Python导出数据到Excel可读取的CSV文件的方法.分享给大家供大家参考.具体实现方法如下: import csv with open('eggs.csv', 'wb') as csvfile: #spamwriter = csv.writer(csvfile, delimiter=' ',quotechar='|', #quoting=csv.QUOTE_MINIMAL) spamwriter = csv.writer(csvfile, dialect='excel') s