深入了解Vue2中的的双端diff算法
目录
- 简单diff算法
- 更新文本节点
- key的作用
- 如何移动呢
- 双端diff算法
- 比较方式
- 非理想情况的处理方式
今天又重读了vue2的核心源码,主要之前读vue2源码的时候纯属的硬记,或者说纯粹的为了应付面试,导致我们并没有去细品源码中的精妙之处。如果回头在重读源码的时候,发现其中有很多地方是值得我们深入了解的。比如我们今天要看的“双端diff”。还记得之前就记得双端diff对比的口诀”头头、尾尾、头尾、尾头“,具体对比做了啥事,这种对比有什么好处,可以说是一无所知。今天我们就来好好的看看。
patch可以将vnode渲染成真实的DOM,实际作用是在现有的DOM进行修改来完成更新视图的目的。
在说“双端diff”之前,我们先来简单看看“简单diff”。
简单diff算法
更新文本节点
const oldVNode = {
type: "div",
children: [{ type: "p", children: " 1" }],
children: [{ type: "p", children: " 2" }],
children: [{ type: "p", children: " 3" }],
};
const newVNode = {
type: "div",
children: [{ type: "p", children: " 4" }],
children: [{ type: "p", children: " 5" }],
children: [{ type: "p", children: " 6" }],
};
我们知道,操作DOM的性能开销都比较大,比如我们创建一个DOM的时候,会连带着创建很多的属性。如果我们想将oldVNode替换成newVNode,最暴力的解法就是卸载所有旧子节点,挂载所有新的子节点,这样就会频繁的操作dom。但是我们根据例子发现,如果说节点都是p标签,只是内容发生了改变,那是不是就只可以直接修改内容了,这样就不需要频繁的删除dom,创建dom了。
key的作用
const oldVNode = [{ type: "p" }, { type: "div" }, { type: "span" }];
const newVNode = [{ type: "span" }, { type: "p" }, { type: "div" }];
根据上面的例子,如果操作DOM的话,则需要将旧子节点中的标签和新子节点中的标签进行一对一的对比,如果旧子节点中的{type: 'p'}和新子节点中的{type: 'span'}不是相同的标签,会先卸载{type: 'p'},然后再挂载{ type:'span'},这需要执行 2 次 DOM 操作。仔细观察可以发现,新旧子节点仅仅是顺序不同,这样就可以通过DOM的移动来完成子节点的更新了。
如果仅仅通过type判断,那么type相同,内容不同呢。比如:
const oldVNode = [
{ type: "p", children: " 1" },
{ type: "p", children: " 2" },
{ type: "p", children: " 3" },
];
const newVNode = [
{ type: "p", children: " 3" },
{ type: "p", children: " 1" },
{ type: "p", children: " 2" },
];
这里我们确实可以通过移动DOM来完成更新,但是我们现在继续用type去判断还能行吗?肯定不行的,因为type都是一样的。这时,我们就需要引入额外的key来作为vnode的标识。
const oldVNode = [
{ type: "p", children: " 1", key: " 1" },
{ type: "p", children: " 2", key: " 2" },
{ type: "p", children: " 3", key: " 3" },
];
const newVNode = [
{ type: "p", children: " 3", key: " 3" },
{ type: "p", children: " 1", key: " 1" },
{ type: "p", children: " 2", key: " 2" },
];
这时我们找到需要移动的元素更新即可了。
如何移动呢
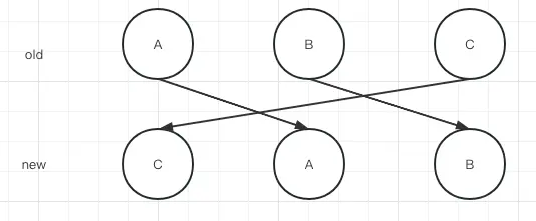
比如我们有三个节点,我们希望移动将老的节点更新成为新的节点,此时我们需要一个变量lastIndex为0来记录,只要当前的节点索引小于lastIndex,则说明此节点需要移动。如果当前的索引大于等于lastIndex,则说明此节点不需要移动,并且将当前节点的索引值赋值给lastIndex。
let lastIndex = 0;
for (let i = 0; i < newChildren.length; i++) {
const newVNode = newChildren[i];
// 遍历旧的children
// 在第一场循环中定义变量find,代表是否在旧的一组子节点中找到可复用的节点
let find = false;
for (let j = 0; j < oldChildren.length; j++) {
const oldVNode = oldChildren[j];
// 如果找到具有相同的key值得两个节点,说明可以复用,仍然需要调用patch函数更新
if (newVNode.key === oldVNode.key) {
patch(oldVNode, newVNode, container);
if (j < lastIndex) {
// 如果当前找到的节点在旧children中的索引小于最大索引值lastIndex
// 说明该节点对应的真实DOM需要移动
// 先获取newVnode的前一个vnode, prevVNode
const prevVNode = newChildren[i - 1];
if (prevVNode) {
// 由于我们要将newVnode对应的真实DOM移动到prevVNode所对应真实DOM后面
// 所以我们需要获取prevVNode所对应真实DOM的下一个兄弟节点,并将其作为锚点
const anchor = prevVNode.el.nextSibling;
// 调用insert方法将newVNode对应的真实DOM插入到锚点元素前面
// 也就是preVNode对应真实DOM的后面
insert(newVNode.el, container, anchor);
}
} else {
// 如果当前找到的节点在旧children中的索引不小于最大索引值
// 则更新lastIndex的值
lastIndex = j;
}
break;
}
}
}
以上是一个简单的demo实现,则发现需要对旧子节点移动两次才能更新成新的子节点。
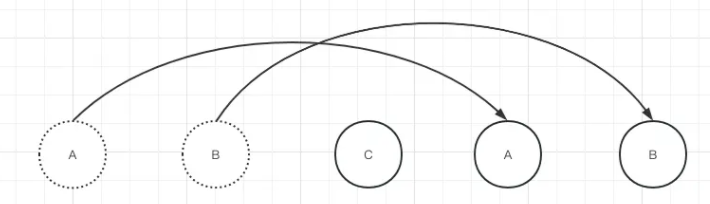
但是我们仔细观察发现,其实只需要将C移动到最前面,这一步就可以实现了。此时我们就需要双端diff算法了
双端diff算法
双端diff算法是一种同时对新旧两组子节点的两个断点进行对比的算法。所以我们需要四个索引值,分别指向新旧两组子节点的端点。

比较方式
在双端diff算法比较中,每一轮比较都会分成4个步骤
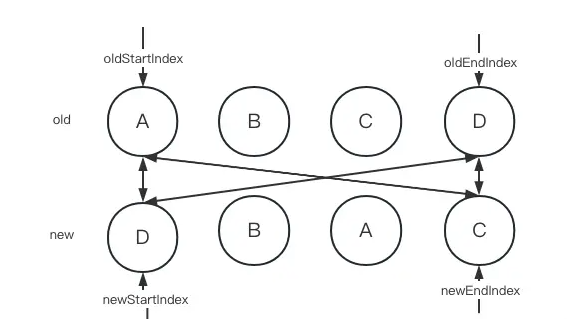
- 第一步:旧子节点的开始节点和新子节点的开始节点进行对比,看看他们是否相同。根据他们的标签和key判断,两个节点不相同,所以什么都不做
- 第二步:旧子节点的结束节点和新子节点的结束节点进行对比,看看他们是否相同。根据他们的标签和key判断,两个节点不相同,所以什么都不做
- 第三步:旧子节点的开始节点和新子节点的结束节点进行对比,看看他们是否相同。根据他们的标签和key判断,两个节点不相同,所以什么都不做
- 第四步:旧子节点的结束节点和新子节点的开始节点进行对比,看看他们是否相同。根据他们的标签和key判断,两个节点相同,说明节点可以复用,此时节点需要通过移动来更新。
那又该怎么移动呢?
根据对比我们发现,我们在第四步是将旧子节点的结束节点和新子节点的开始节点进行对比,发现节点可复用。说明节点’D‘在旧子节点中是最后一个节点,在新子节点中是第一个节点,而我们要操作的是老节点也就是现有节点,来实现视图的更新。所以我们只需要将索引 oldEndIdx 指向的虚拟节点所对应的真实DOM 移动到索引 oldStartIdx 指向的虚拟节点所对应的真实 DOM前面。我们看下源码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 老的开始节点 和 新的开始节点一样
···
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 老的结束节点 和 新的结束节点一样
···
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
// 老的开始节点 和 新的结束节点一样
···
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
// 老的结束节点 和 新的开始节点一样
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
// 将老的结束节点 塞到 老的新节点之前
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else { // 非理想状态下的处理方式
···
}
}
}
从源码中我们看到执行了patchVnode。这个函数其实就是将需要对比的两个新老节点进行打补丁,因为我们此时只能确认新老节点他们的标签和key是一样的,并不代表他们的内容一样,所以需要先更新节点的内容,然后再修改节点的位置。最后我们只需要以头部元素oldStartVNode.elm 作为锚点,将尾部元素 oldEndVNode.elm 移动到锚点前面即可。最后涉及的两个索引分别是oldEndIdx和newStartIdx,所以我们需要更新两者的值,让它们各自朝正确的方向前进一步,并指向下一个节点。
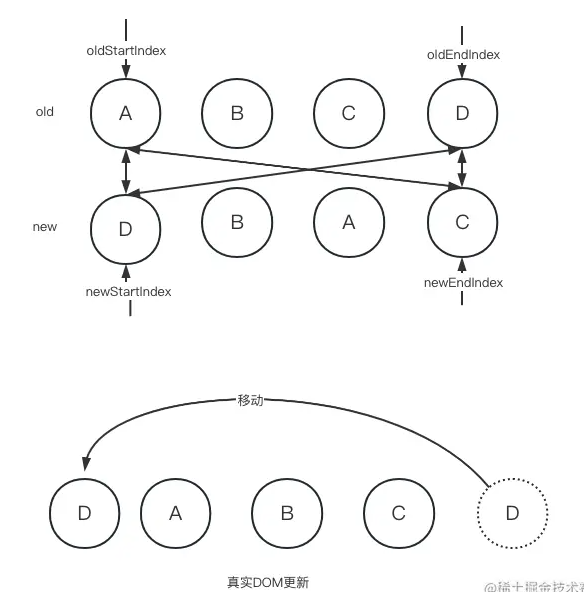
接着继续进行下一轮对比:
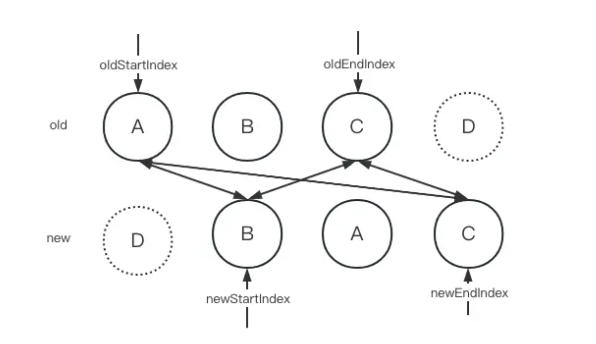
还是按照我们上面说的那4步对比。此时,当我们执行第二步对比的时候,发现老的结束节点和新的结束节点是一样的。所以就会执行以下操作:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 老的开始节点 和 新的开始节点一样
···
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 老的结束节点 和 新的结束节点一样
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
// 老的开始节点 和 新的结束节点一样
···
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
// 老的结束节点 和 新的开始节点一样
···
} else { // 非理想状态下的处理方式
···
}
}
}
这里就只需要通过patchVnode更新新旧子节点的内容,然后更新oldEndIdx和newStartIdx,让它们各自朝正确的方向前进一步,并指向下一个节点。
接着继续进行下一轮对比:
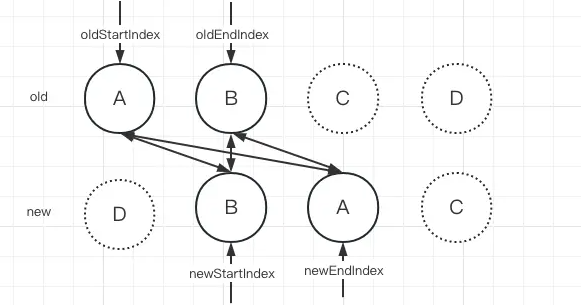
当对比到第三步的时候,发现老的开始节点和新的结束节点一样
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 老的开始节点 和 新的开始节点一样
···
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 老的结束节点 和 新的结束节点一样
···
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
// 老的开始节点 和 新的结束节点一样
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
// 将老的开始节点 塞到 老的结束节点后面
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
// 老的结束节点 和 新的开始节点一样
···
} else { // 非理想状态下的处理方式
···
}
}
}
首先通过patchVnode更新新旧子节点的内容。旧的一组子节点的头部节点与新的一组子节点的尾部节点匹配,则说明该旧节点所对应的真实 DOM 节点需要移动到尾部。因此,我们需要获取当前尾部节点的下一个兄弟节点作为锚点,即 oldEndVNode.el.nextSibling。最后,更新相关索引到下一个位置。

接着继续进行下一轮对比:
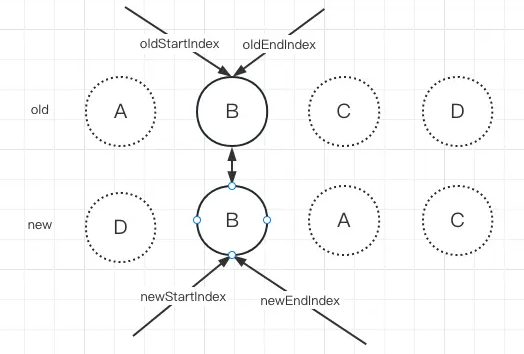
这里就只需要通过patchVnode更新新旧子节点的内容,发现内容一样什么都不做,然后更新oldEndIdx和newStartIdx,让它们各自朝正确的方向前进一步,并指向下一个节点,这就退出了循环。
以上是理想情况下的处理方式,当然还有非理想情况下的处理方式
非理想情况的处理方式
比如:
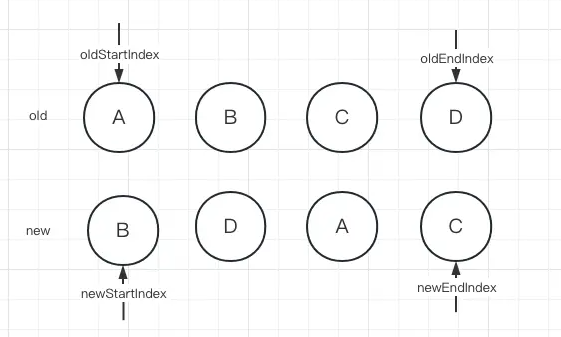
此时我们发现之前说的情况都无法命中,所以我们只能通过增加额外的步骤去处理。由于我们都是对比的头部和尾部,既然都无法命中,那就试试非头部、非尾部节点能否复用。此时我们可以发现新子节点中头部节点和旧子节点中的第二个节点是可以复用的,所以只需要将旧子节点中的第二个节点移动到当前旧子节点的头部即可。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 老的开始节点 和 新的开始节点一样
···
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 老的结束节点 和 新的结束节点一样
···
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
// 老的开始节点 和 新的结束节点一样
···
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
// 老的结束节点 和 新的开始节点一样
···
} else { // 非理想状态下的处理方式
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
// 新的一组子节点的头部 去 旧的一组节点中寻找
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) { // New element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
} else {
// 拿到新节点头部 在旧的一组节点中对应的节点
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) { // 如果是相同的节点 则patch
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
// 将老的节点中对应的设置为undefined
oldCh[idxInOld] = undefined
// 移动节点
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// same key but different element. treat as new element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
}
首先那新的子节点的头部去旧的一组子节点中寻找,如果没有找到,说明这个节点是一个新的节点,则直接创建节点。如果找到了,通过索引去获取对应的旧节点的信息,如果节点可复用,则需要将当前旧节点移动到头部即可。最后更新新节点的开始节点的索引位置。

到此这篇关于深入了解Vue2中的的双端diff算法的文章就介绍到这了,更多相关Vue双端diff算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Vue3 diff算法之双端diff算法详解
目录 双端Diff算法 双端比较的原理 简单Diff的不足 双端Diff介绍 Diff流程 第一次diff 第二次diff 第三次diff 第四次diff 双端Diff的优势 非理想情况的处理方式 添加新元素 移除不存在得节点 双端Diff完整代码 双端Diff算法 双端Diff在可以解决更多简单Diff算法处理不了的场景,且比简单Diff算法性能更好.本篇是以简单Diff算法的案例来展开的,不过没有了解简单Diff算法直接看双端Diff算法也是可以看明白的. 双端比较的原理 引用简单Diff算
-

一文详解Vue 的双端 diff 算法
目录 前言 diff 算法 简单 diff 双端 diff 总结 前言 Vue 和 React 都是基于 vdom 的前端框架,组件渲染会返回 vdom,渲染器再把 vdom 通过增删改的 api 同步到 dom. 当再次渲染时,会产生新的 vdom,渲染器会对比两棵 vdom 树,对有差异的部分通过增删改的 api 更新到 dom. 这里对比两棵 vdom 树,找到有差异的部分的算法,就叫做 diff 算法. diff 算法 我们知道,两棵树做 diff,复杂度是 O(n^3) 的,因为每个节
-
React Diff算法不采用Vue的双端对比原因详解
目录 前言 React 官方的解析 Fiber 的结构 Fiber 链表的生成 React 的 Diff 算法 第一轮,常见情况的比对 第二轮,不常见的情况的比对 重点如何协调更新位置信息 小结 图文解释 React Diff 算法 最简单的 Diff 场景 复杂的 Diff 场景 Vue3 的 Diff 算法 第一轮,常见情况的比对 第二轮,复杂情况的比对 Vue2 的 Diff 算法 第一轮,简单情况的比对 第二轮,不常见的情况的比对 React.Vue3.Vue2 的 Diff 算法对比
-
深入了解Vue2中的的双端diff算法
目录 简单diff算法 更新文本节点 key的作用 如何移动呢 双端diff算法 比较方式 非理想情况的处理方式 今天又重读了vue2的核心源码,主要之前读vue2源码的时候纯属的硬记,或者说纯粹的为了应付面试,导致我们并没有去细品源码中的精妙之处.如果回头在重读源码的时候,发现其中有很多地方是值得我们深入了解的.比如我们今天要看的“双端diff”.还记得之前就记得双端diff对比的口诀”头头.尾尾.头尾.尾头“,具体对比做了啥事,这种对比有什么好处,可以说是一无所知.今天我们就来好好的看看.
-
JS中队列和双端队列实现及应用详解
队列 队列 双端队列数据结构 应用 用击鼓传花游戏模拟循环队列 用双端对列检查一个词是否构成回文 生成 1 到 n 的二进制数 队列和双端队列 队列遵循先进后出(FIFO, 也称为先来先服务) 原则的. 日常有很多这样场景: 排队购票.银行排队等. 由对列的特性,银行排队为例, 队列应该包含如下基本操作: 加入队列(取号) enqueue 从队列中移除(办理业务离开) dequeue 当前排队号码(呼叫下一个人) peek 当前队列长度(当前排队人数) size 判断队列是不是空 isEmpty
-
react中的虚拟dom和diff算法详解
虚拟DOM的作用 首先我们要知道虚拟dom的出现是为了解决什么问题的,他解决我们平时频繁的直接操作DOM效率低下的问题.那么为什么我们直接操作DOM效率会低下呢? 比如我们创建一个div,我们可以在控制台查看一下这个div上自带或者继承了很多属性,尤其是我们使用js操作DOM的时候,我们的DOM本身就很复杂,js的操作也会占用很多时间,但是我们控制不了DOM元素本身,因此虚拟DOM解决的是js操作DOM这一层面,其实解决的是减少了操作dom的次数 简单实现虚拟DOM 虚拟DOM,见名知意,就是假
-
详解Python的collections模块中的deque双端队列结构
deque 是 double-ended queue的缩写,类似于 list,不过提供了在两端插入和删除的操作. appendleft 在列表左侧插入 popleft 弹出列表左侧的值 extendleft 在左侧扩展 例如: queue = deque() # append values to wait for processing queue.appendleft("first") queue.appendleft("second") queue.appendl
-
详解Vue2的diff算法
前言 双端比较算法是vue2.x采用的diff算法,本篇文章只是对双端比较算法粗略的过程进行了一下分析,具体细节还是得Vue源码,Vue的源码在这 过程 假设当前有两个数组arr1和arr2 let arr1 = [1,2,3,4,5] let arr2 = [4,3,5,1,2] 那么其过程有五步 arr1[0] 和 arr2[0]比较 arr1[ arr1.length-1 ] 和 arr2[ arr2.length-1 ] 比较 arr1[0] 和 arr2[ arr2.length-1
-
Java数据结构之双端链表原理与实现方法
本文实例讲述了Java数据结构之双端链表原理与实现方法.分享给大家供大家参考,具体如下: 一.概述: 1.什么时双端链表: 链表中保持这对最后一个连点引用的链表 2.从头部插入 要对链表进行判断,如果为空则设置尾节点为新添加的节点 3.从尾部进行插入 如果链表为空,则直接设置头节点为新添加的节点,否则设置尾节点的后一个节点为新添加的节点 4.从头部删除 判断节点是否有下个节点,如果没有则设置节点为null 二.具体实现 /** * @描述 头尾相接的链表 * @项目名称 Java_DataStr
-
Java模拟单链表和双端链表数据结构的实例讲解
模拟单链表 线性表: 线性表(亦作顺序表)是最基本.最简单.也是最常用的一种数据结构. 线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的. 线性表的逻辑结构简单,便于实现和操作. 在实际应用中,线性表都是以栈.队列.字符串等特殊线性表的形式来使用的. 线性结构的基本特征为: 1.集合中必存在唯一的一个"第一元素": 2.集合中必存在唯一的一个 "最后元素" : 3.除最后一个元素之外,均有 唯一的后继(后件):