python正则表达中的re库常用方法总结
元字符 :

预定义字符集:
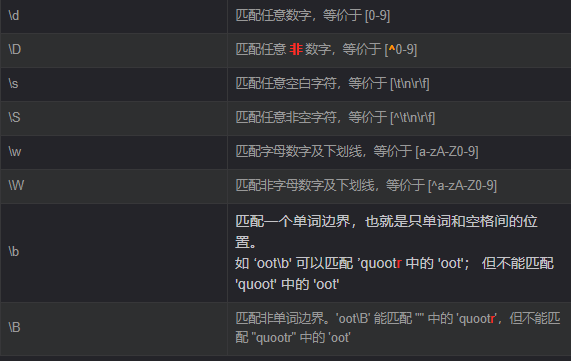
我进行组合一些复杂的正则表达式的时候是为了快捷去晚上找一些现成的模式,然后再自己进行修改,变成符合自己需要的一些正则表达式。
import re
# 正则表达式中的一些使用的符号
# 匹配出现符合条件的 0 次的或者是 多次
str1 = 'qwertyuio1ui3oo467j398k'
# 关键词: * 下面的句子就是进行匹配 零次 或者是 多次(多个字符) 符合是数字的意思
pattern = re.compile(r'\d*')
res = re.findall(pattern, str1)
print(res)
""""
显示的结果:
['', '', '', '', '', '', '', '', '', '1', '', '', '3', '', '', '467', '', '398', '', '']
"""
# 关键词: + 匹配一次或者是多次的结果
pattern = re.compile(r'\d+')
res = re.findall(pattern, str1)
print(res)
"""
显示结果:
['1', '3', '467', '398']
"""
# 关键词: ? 匹配0次或者是1次的结果
pattern = re.compile(r'\d?')
res = re.findall(pattern, str1)
print(res)
"""
['', '', '', '', '', '', '', '', '', '1',
'', '', '3', '', '', '4', '6', '7', '',
'3', '9', '8', '', '']
"""
# {m}精确匹配m次 (比如写进去的3,那么他就是匹配到是3个数字字符串的所有小字符串)
pattern = re.compile(r'\d{3}')
res = re.findall(pattern, str1)
print(res)
# 结果:['467', '398']
# {m, n} 最少匹配m次,最多匹配n次
# 记住在{}里面是不能随便加上空格的?
pattern = re.compile(r'\d{1,3}')
res = re.findall(pattern, str1)
print(res)
# 结果:['1', '3', '467', '398']
match()函数只检测 目标字符(串) 是不是在string的开始位置匹配,search()会扫描整个string查找匹配, match()只有在0位置匹配成功才会有返回,如果不是开始位置匹配成功,match()就会返回None
代码解释:
import re
m = re.match('lsp','hhttlsp')
if m is not None:
print(m.group())
else:
print('noneFine')
显示结果:
noneFine
n = re.search('lsp','hhttlsp')
if n is not None:
print(n.group())
else:
print(noneFine')
显示结果:
lsp
import re
n = re.search('lsp','hhttlsp')
if n:
print(n.group())
else:
print('noneFine')
# 显示结果:
# lsp
m = re.match('lsp','hhttlsp')
if m:
print(m.group())
else:
print('noneFine')
# 显示结果:
# noneFine
python的re库有两个函数/方法用于实现搜索和替换功能: sub()和subn().两者几乎一样,都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换.用来替换的部分通常是一个字符串,但它也可能是一个函数,该函数返回一个用来替换的字符串.subn()和 sub()一样,但subn()还返回一个表示替换的总数,替换后的字符串和表示替换总数的数字一起作为一个拥有两个元素的元组返回.
# 可以使用sub()方法来进行查询和替换,sub方法的格式为: # sub(replacement, string[, count=0]) # replacement是被替换成的文本 # string是需要被替换的文本 # count是一个可选参数,指最大被替换的数量 # 下面进行将所有的数字给进行替换掉 pattern = re.compile(r'\d') res = re.sub(pattern, '替换掉的数字 ',str1) print(res) # 下文结果,为了方便大家看到换了多少个数字,我使用了换行将字符串给换行看出有几次换了数字 """ qwertyuio替换掉的数字 ui替换掉的数字 oo替换掉的数字 替换掉的数字 替换掉的数字 j替换掉的数字 替换掉的数字 替换掉的数字 k """
# 加上显示修改了多少次
res = re.subn(pattern, '替换掉的数字 ',str1)
print(res)
"""
结果:
('qwertyuio替换掉的数字
ui替换掉的数字
oo替换掉的数字
替换掉的数字
替换掉的数字
j替换掉的数字
替换掉的数字
替换掉的数字
k', 8)
"""
re.split(pattern, string, maxsplit=0, flags=0),如果匹配成功,则返回一个列表,否则返回原string列表;
- 第1个参数:正则表达式
- 第2个参数:要匹配查找的原始字符串;
- 第3个参数:可选参数,表示最大的拆分次数,默认为0,表示全部分割;
- 第4个参数:可选参数,标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等;
特别注意: 此方法并不是完全匹配。它仅仅决定在字符串开始的位置是否匹配。所以当pattern结束时若还有剩余字符,仍然成功。若想进行完全匹配,可以在表达式末尾加上边界匹配符'$'
str2 = '自然语言处理123机器学习456深度学习' pattern = re.compile(r'\d+') res = re.split(pattern, str2) print(res) # 结果: # ['自然语言处理', '机器学习', '深度学习']
Python的re模块是第一个提出解决方案的模块:命名捕获组和命名后向引用。(?P <name> group)将组的匹配捕获到后向引用“名称”中。
str2 = '自然语言处理123机器学习456深度学习'
pattern = re.compile(r'(?P<dota>\d+)(?P<lsp>\D+)')
m = re.search(pattern, str2)
print(m.group('lsp'))
# 结果为:
# 机器学习
str2 = '自然语言处理123机器学习456深度学习'
pattern = re.compile(r'(?P<dota>\d+)(?P<lsp>\D+)')
m = re.search(pattern, str2)
print(m.group('dota'))
# 结果为:
# 123
进行号码的筛选,小尝试:
# 筛选号码 str3 = 'number 132-3209-*******' pattern = re.compile(r'(\d\d\d-\d\d)') res = re.search(pattern, str3) print(res.group()) # 显示结果: # 132-32
全部代码:
# -*- coding:utf-8 -*-
# @Author : DaFuChen
# @File : demo1.py
# @software: PyCharm
import re
# 正则表达式中的一些使用的符号
# 匹配出现符合条件的 0 次的或者是 多次
str1 = 'qwertyuio1ui3oo467j398k'
# 关键词: * 下面的句子就是进行匹配 零次 或者是 多次(多个字符) 符合是数字的意思
pattern = re.compile(r'\d*')
res = re.findall(pattern, str1)
print(res)
""""
显示的结果:
['', '', '', '', '', '', '', '', '', '1', '', '', '3', '', '', '467', '', '398', '', '']
"""
# 关键词: + 匹配一次或者是多次的结果
pattern = re.compile(r'\d+')
res = re.findall(pattern, str1)
print(res)
"""
显示结果:
['1', '3', '467', '398']
"""
# 关键词: ? 匹配0次或者是1次的结果
pattern = re.compile(r'\d?')
res = re.findall(pattern, str1)
print(res)
"""
['', '', '', '', '', '', '', '', '', '1',
'', '', '3', '', '', '4', '6', '7', '',
'3', '9', '8', '', '']
"""
# {m}精确匹配m次 (比如写进去的3,那么他就是匹配到是3个数字字符串的所有小字符串)
pattern = re.compile(r'\d{3}')
res = re.findall(pattern, str1)
print(res)
# 结果:['467', '398']
# {m, n} 最少匹配m次,最多匹配n次
# 记住在{}里面是不能随便加上空格的?
pattern = re.compile(r'\d{1,3}')
res = re.findall(pattern, str1)
print(res)
# 结果:['1', '3', '467', '398']
import re
n = re.search('lsp','hhttlsp')
if n:
print(n.group())
else:
print('noneFine')
# 显示结果:
# lsp
m = re.match('lsp','hhttlsp')
if m:
print(m.group())
else:
print('noneFine')
# 显示结果:
# noneFine
# 可以使用sub()方法来进行查询和替换,sub方法的格式为:
# sub(replacement, string[, count=0])
# replacement是被替换成的文本
# string是需要被替换的文本
# count是一个可选参数,指最大被替换的数量
# 下面进行将所有的数字给进行替换掉
pattern = re.compile(r'\d')
res = re.sub(pattern, '替换掉的数字 ',str1)
print(res)
# 下文结果,为了方便大家看到换了多少个数字,我使用了换行将字符串给换行看出有几次换了数字
"""
qwertyuio替换掉的数字
ui替换掉的数字
oo替换掉的数字
替换掉的数字
替换掉的数字
j替换掉的数字
替换掉的数字
替换掉的数字 k
"""
# 加上显示修改了多少次
res = re.subn(pattern, '替换掉的数字 ',str1)
print(res)
"""
结果:
('qwertyuio替换掉的数字
ui替换掉的数字
oo替换掉的数字
替换掉的数字
替换掉的数字
j替换掉的数字
替换掉的数字
替换掉的数字
k', 8)
"""
str2 = '自然语言处理123机器学习456深度学习'
pattern = re.compile(r'\d+')
res = re.split(pattern, str2)
print(res)
# 结果:
# ['自然语言处理', '机器学习', '深度学习']
str2 = '自然语言处理123机器学习456深度学习'
pattern = re.compile(r'(?P<dota>\d+)(?P<lsp>\D+)')
m = re.search(pattern, str2)
print(m.group('dota'))
# 结果为:
# 123
# 筛选号码
str3 = 'number 132-3209-*******'
pattern = re.compile(r'(\d\d\d-\d\d)')
res = re.search(pattern, str3)
print(res.group())
# 显示结果:
# 132-32
到此这篇关于python正则表达中的re库常用方法总结的文章就介绍到这了,更多相关python re库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python re库的正则表达式入门学习教程
简介 正则表达式本身是一种小型的.高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配.正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行. 下面话不多说了,来一起看看详细的介绍吧 1. 安装 默认已经安装好了python环境了 re库是python3的核心库,不需要pip install,直接import就行 2. 最简单的模式 字符本身就是最简单的模式 比如:'A', 'I love you', 'test' 然是注意在定义模式字
-

videocapture库制作python视频高速传输程序
1,首先是视频数据[摄像头图像]的采集,通常可以使用vfw在vc或者vb下实现,这个库我用的不好,所以一直不怎么会用.现在我们用到的是python的videocapture库,这个库用起来很简单,如下: 复制代码 代码如下: from VideoCapture import Devicecam = Device()cam.setResolution(320,240) #设置显示分辨率cam.saveSnapshot('demo.jpg') #抓取并保存图片 这样,你就得到了一张图片.当然,要
-
Python正则表达式和re库知识点总结
正则表达式是定义搜索模式的字符序列.通常这种模式被字符串搜索算法用于字符串上的"查找"或"查找和替换"操作,或者用于输入验证. 1. 正则表达式的语法 . 表示任何单个字符 [] 字符集,对单个字符给出取值范围 [^] 非字符集,对单个字符给出排除范围 *前一个字符0次或者无限次扩展 +前一个字符1次或无限次扩展 ?前一个字符0次或1次扩展 |左右表达式任意一个 {m}扩展前一个字符m次 {m,n}扩展前一个字符m至n次 ^匹配字符串开头 $匹配字符串结尾 ()分组
-
python正则表达中的re库常用方法总结
元字符 : 预定义字符集: 我进行组合一些复杂的正则表达式的时候是为了快捷去晚上找一些现成的模式,然后再自己进行修改,变成符合自己需要的一些正则表达式. import re # 正则表达式中的一些使用的符号 # 匹配出现符合条件的 0 次的或者是 多次 str1 = 'qwertyuio1ui3oo467j398k' # 关键词: * 下面的句子就是进行匹配 零次 或者是 多次(多个字符) 符合是数字的意思 pattern = re.compile(r'\d*') res = re.findal
-
Python正则表达re模块之findall()函数详解
一.re.findall函数介绍 它在re.py中有定义: def findall(pattern, string, flags=0): """Return a list of all non-overlapping matches in the string. If one or more capturing groups are present in the pattern, return a list of groups; this will be a list of
-
python爬虫之urllib库常用方法用法总结大全
Urllib 官方文档地址:https://docs.python.org/3/library/urllib.html urllib提供了一系列用于操作URL的功能. 本文主要介绍的是关于python urllib库常用方法用法的相关内容,下面话不多说了,来一起看看详细的介绍吧 1.读取cookies import http.cookiejar as cj,urllib.request as request cookie = cj.CookieJar() handler = request.HT
-
python中altair可视化库实例用法
作为六大python可视化库,基本上学会都是可以通吃任何领域的存在,本章要给大家介绍的Altair就是其中之一的可视化库,能够将数据转化为非常直观的图片,让我们更加清晰的认知数据之前直观的联系,俨然已经成为可视化库中的新星,好啦,下面就让我们详细了解下这个荣获众多粉丝的可视化库的使用技巧吧. 安装Altair: 依赖JupyterLab $ pip install -U altair vega_datasets jupyterlab 导入Altair: import altair as alt
-
Python基础之常用库常用方法整理
一.os __file__ 获取当前运行的.py文件所在的路径(D:\PycharmProjects\My_WEB_UI\ConfigFiles\ConfigPath.py) os.path.dirname(__file__) 上面正在运行的.py文件的上一级(D:\PycharmProjects\My_WEB_UI\ConfigFiles) os.path.join(xxx,u'ConfigFiles\elementLocation.ini') 在已获得的路径xxx上加上\ConfigFile
-
超详细的Python安装第三方库常用方法汇总
目录 前言 安装方法 1. 通过pychram安装 2. pip安装大法 3. 下载whl文件到本地离线安装 3.1 补充 4.其他方法 4.1 Python官方的Pypi菜单 4.2 国内镜像源解决pip安装过慢的问题 小结 总结 前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题,这个问题对于很多初学者而言头疼不已.这里我做一些简单的总结,如何正确高效地安装第三方库,少走弯路(毕竟都是我亲自踩过的坑,所以特地来总结一下,方便以后回顾和总结)! 安装方法 1. 通过pychr
-
python中的json模块常用方法汇总
目录 一.概述 二.方法详解 1.dump() 2.dumps 3.load 4.loads 三.代码实战 1.dumps() 2.dump() 4.loads() 一.概述 推荐使用参考网站:json 在python中,json模块可以实现json数据的序列化和反序列化 序列化:将可存放在内存中的python 对象转换成可物理存储和传递的形式 实现方法:load() loads() 反序列化:将可物理存储和传递的json数据形式转换为在内存中表示的python对象 实现方法:dump() du
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
详解在Python的Django框架中创建模板库的方法
不管是写自定义标签还是过滤器,第一件要做的事是创建模板库(Django能够导入的基本结构). 创建一个模板库分两步走: 第一,决定模板库应该放在哪个Django应用下. 如果你通过 manage.py startapp 创建了一个应用,你可以把它放在那里,或者你可以为模板库单独创建一个应用. 我们更推荐使用后者,因为你的filter可能在后来的工程中有用. 无论你采用何种方式,请确保把你的应用添加到 INSTALLED_APPS 中. 我们稍后会解释这一点. 第二,在适当的Django应用包里创
-
Python中使用PDB库调试程序
Python自带的pdb库,发现用pdb来调试程序还是很方便的,当然了,什么远程调试,多线程之类,pdb是搞不定的. 用pdb调试有多种方式可选: 1. 命令行启动目标程序,加上-m参数,这样调用myscript.py的话断点就是程序的执行第一行之前 复制代码 代码如下: python -m pdb myscript.py 2. 在Python交互环境中启用调试 复制代码 代码如下: >>> import pdb >>> import mymodule >>