Python爬虫获取基金净值信息详情
目录
- 1 前言
- 2 获取基金净值
- 3 数据库结构设计
- 4 如何进行数据存储
- 5 总结
1 前言
前面的文章中我们已经获取到了基金的阶段变动信息和ETF信息的获取,那么在本章中,我们将继续前面的内容,获取基金的价格信息,并且把之前的抓取到的数据存入到数据库中,方便我们进行后续的分析操作。
2 获取基金净值
获取基金的净值信息,也就是基金的最近一个交易日的价格,如下图所示,展示了单位净值更新的日期,价格以及涨跌幅度信息。顺便我们也获取一下基金的规模信息,后续选择到同类基金不知道怎么去选择的时候,可以选择按照基金规模进行倒排序,选取规模比较大的进行投资,大概率能够保证投资收益的稳定性和可靠性。

过分分析,我们可以知道,基金的价格信息需要先获取 class="dataItem0" 的 dl 标签,基金规模信息的获取方式也如上图,可以知道规模信息在 <div class="infoOfFund">标签中的table 中的第二个td 中 :
单位净值日期获取方式:
dt>p 标签内容
基金净值和变动信息获取方式:
- dd.dataNums>span[0] 标签为单位净值
- dd.dataNums>span[1] 标签为变动百分比
基金规模信息的获取方式:
div>table>td[2]
基于以上的分析,我们最终实现的代码如下图所示,通过以上方式我们就获取到了基金的价格信息数据:
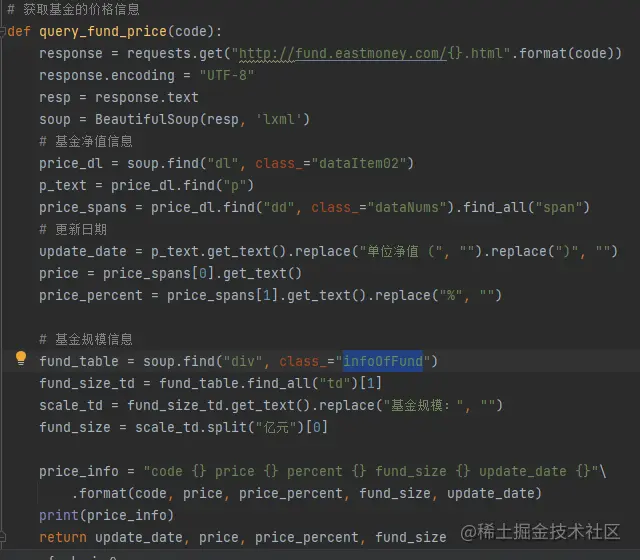
打印的结果如下图所示:
code 159779 price 1.0007 percent 0.07 fund_size 3.55 update_date 2021-11-19
3 数据库结构设计
在获取到数据之后,需要将数据进行结构化存储

4 如何进行数据存储
需要进行存储,就需要使用数据库。在java中存储数据有各种各样的orm框架进行操作,但是Python中没有这么重的操作,需要自己书写sql进行操作。首先我们需要安装操作数据库的类库。
# 安装 pymysql pip install pymysql
接下来我们需要配置数据库的连接信息,通过连接信息,编写两个方法,一个是查询数据库的信息,另外一个是修改数据库的信息(增/删/改)。修改数据的时候一定要记得commit()数据库信息,否则不会保存成功。

5 总结
本文介绍了如何获取基金的价格信息,同时也进行了数据库结构的设计以及数据存储的操作方法,由于代码和表结构会占用大量的文案,文章就贴图展示
到此这篇关于Python爬虫获取基金净值信息详情的文章就介绍到这了,更多相关Python获取信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫获取基金变动信息
目录 1 前言 2 抓取变动信息 2.1 基金的变动信息获取 2.2 基金阶段信息的抓取 3 最终结果展现 1 前言 前面文章Python爬虫获取基金列表.Python爬虫获取基金基本信息我们已经介绍了怎么获取基金列表以及怎么获取基金基本信息,本文我们继续前面的内容,获取基金的变动信息.这次获取信息的方式将组合使用页面数据解析和api接口调用的方式进行. 2 抓取变动信息 我们通过观察基金基本信息页面,我们可以发现有关基金变动信息的页面可以包含以下4个部分: 接下来说一下我们抓取数据的思路,在第
-
Python爬虫获取基金基本信息
目录 1 前言 2 如何抓取基本信息 3 xpath 获取数据 4 bs4 获取数据 5 最终结果展现 1 前言 上篇文章Python爬虫获取基金列表我们已经讲述了如何从基金网站上获取基金的列表信息.这一骗我们延续上一篇,继续分享如何抓取基金的基本信息做展示.展示的内容包括基金的基本信息,诸如基金公司,基金经理,创建时间以及追踪标.持仓明细等信息. 2 如何抓取基本信息 # 在这里我就直接贴地址了,这个地址的获取是从基金列表跳转,然后点基金概况就可以获取到了. http://fundf10.ea
-
python爬虫之基金信息存储
目录 1 前言 2 信息存储 2.1 基金基本信息存储 2.2 基金变动信息获取 3 需要改进的地方 3.1 基金类型 3.2 基金的更新顺序 4 总结 1 前言 前面已经讲了很多次要进行数据存储,终于在上一篇中完成了数据库的设计,在这一篇就开始数据的存储操作,在数据存储的这个部分,会将之前抓取到的基金列表,基金基本信息和基金变动信息以及ETF信息进行存储. 2 信息存储 2.1 基金基本信息存储 在这里获取基金信息包括两个部分,一部分是场外基金另外一部分是场外基金信息.之在前的文章中,我们已经
-
Python3爬虫学习之MySQL数据库存储爬取的信息详解
本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息.分享给大家供大家参考,具体如下: 数据库存储爬取的信息(MySQL) 爬取到的数据为了更好地进行分析利用,而之前将爬取得数据存放在txt文件中后期处理起来会比较麻烦,很不方便,如果数据量比较大的情况下,查找更加麻烦,所以我们通常会把爬取的数据存储到数据库中便于后期分析利用. 这里,数据库选择MySQL,采用pymysql 这个第三方库来处理python和mysql数据库的存取,python连接mysql数据库的配置信息 db_
-
Python实现简易信息分类存储软件
时间紧任务重,女神提出的要求有模棱两可,只能自己考虑各种情况,除了用python还有谁能这么短的时间搞出来. 程序界面,增删改查不能少,后悔药也需要给女神准备上,由于最后需要打包给女神用,所以选择了python的自带库,tkinter编写界面,我觉得也不是那么丑,数据存储用sqlite3数据库,可以导出成csv文件,完全用python自带库解决,这样打包起来兼容性会好一点. 查询界面,可以根据每个表的各个项目分类查询,如果不输入查询关键字,则当前类别全部输出. 汇总信息展示,这里也是程序初始界面
-
python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中
爬取TOP500的音乐信息,包括排名情况.歌曲名.歌曲时间. 网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL: http://www.kugou.com/yy/rank/home/1-8888.html 这里尝试将1改为2,再进行浏览,恰好是第二页的信息,再改为3,恰好是第三页的信息,多次尝试发现不同的数字即为不同的页面.因此只需更改home/后面的数字即可.由于每页显示的为22首歌曲,所以总共需要23个URL. import requests from bs4 import B
-
详解如何使用Python网络爬虫获取招聘信息
目录 前言 项目目标 项目准备 反爬措施 项目实现 效果展示 小结 前言 现在在疫情阶段,想找一份不错的工作变得更为困难,很多人会选择去网上看招聘信息.可是招聘信息有一些是错综复杂的.而且不能把全部的信息全部罗列出来,以外卖的58招聘网站来看,资料整理的不清晰. 项目目标 获取招聘信息,并批量把地点. 公司名.工资 .下载保存在txt文档. 项目准备 软件:PyCharm 需要的库:requests.lxml.fake_useragent 网站如下: https://gz.58.com/job/
-
python爬虫获取百度首页内容教学
由传智播客教程整理,我们这里使用的是python2.7.x版本,就是2.7之后的版本,因为python3的改动略大,我们这里不用它.现在我们尝试一下url和网络爬虫配合的关系,爬浏览器首页信息. 1.首先我们创建一个urllib2_test01.py,然后输入以下代码: 2.最简单的获取一个url的信息代码居然只需要4行,执行写的python代码: 3.之后我们会看到一下的结果 4. 实际上,如果我们在浏览器上打开网页主页的话,右键选择"查看源代码",你会发现,跟我们刚打印出来的是一模
-
python爬虫获取淘宝天猫商品详细参数
首先我是从淘宝进去,爬取了按销量排序的所有(100页)女装的列表信息按综合.销量分别爬取淘宝女装列表信息,然后导出前100商品的 link,爬取其详细信息.这些商品有淘宝的,也有天猫的,这两个平台有些区别,处理的时候要注意.比如,有的说"面料".有的说"材质成分",其实是一个意思,等等.可以取不同的链接做一下测试. import re from collections import OrderedDict from bs4 import BeautifulSoup
-
Python爬虫获取数据保存到数据库中的超详细教程(一看就会)
目录 1.简介介绍 2.Xpath获取页面信息 3.通过Xpath爬虫实操 3-1.获取xpath 完整代码展示: 总结 1.简介介绍 -网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫.-一般在浏览器上可以获取到的,通过爬虫也可以获取到,常见的爬虫语言有PHP,JAVA,C#,C++,Python,为啥我们经常听到说的都是Python爬虫,这是
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文实例讲述了Python爬虫实现网页信息抓取功能.分享给大家供大家参考,具体如下: 首先实现关于网页解析.读取等操作我们要用到以下几个模块 import urllib import urllib2 import re 我们可以尝试一下用readline方法读某个网站,比如说百度 def test(): f=urllib.urlopen('http://www.baidu.com') while True: firstLine=f.readline() print firstLine 下面我们说
-
使用python爬虫获取黄金价格的核心代码
继续练手,根据之前获取汽油价格的方式获取了金价,暂时没钱投资,看看而已 #!/usr/bin/env python # -*- coding: utf-8 -*- """ 获取每天黄金价格 @author: yufei @site: http://www.antuan.com 2017-05-11 """ import re import urllib2,urllib import random import threading import t
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
python爬虫判断招聘信息是否存在的实例代码
在找工作的时候,我们会选择上网查询招聘的信息,或者是通过一些招聘会进行现场面试.但由于信息更新不及时,有一些岗位会出现下架的情况,如果我们不注意的话,可能就扑了空.在时间上耽误了不说,面试的信息也会受到一点点打击.今天小编就教大家python爬虫来判断招聘信息是否存在. 首先这里需要一个判断某条招聘是否还挂在网站上的方法,这个暂时想到了还没弄,然后对于发布时间在两个月之前的数据,就不进行统计计算. 以下是完成代码: { "_id" : ObjectId("5a30ad2068