《解剖PetShop》之二:PetShop数据访问层数之据库访问设计
二、PetShop数据访问层之数据库访问设计
在系列一中,我从整体上分析了PetShop的架构设计,并提及了分层的概念。从本部分开始,我将依次对各层进行代码级的分析,以求获得更加细致而深入的理解。在PetShop 4.0中,由于引入了ASP.Net 2.0的一些新特色,所以数据层的内容也更加的广泛和复杂,包括:数据库访问、Messaging、MemberShip、Profile四部分。在系列二中,我将介绍有关数据库访问的设计。
在PetShop中,系统需要处理的数据库对象分为两类:一是数据实体,对应数据库中相应的数据表。它们没有行为,仅用于表现对象的数据。这些实体类都被放到Model程序集中,例如数据表Order对应的实体类OrderInfo,其类图如下:
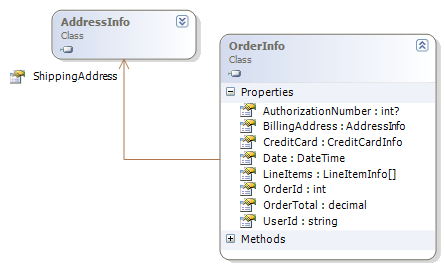
这些对象并不具有持久化的功能,简单地说,它们是作为数据的载体,便于业务逻辑针对相应数据表进行读/写操作。虽然这些类的属性分别映射了数据表的列,而每一个对象实例也恰恰对应于数据表的每一行,但这些实体类却并不具备对应的数据库访问能力。
由于数据访问层和业务逻辑层都将对这些数据实体进行操作,因此程序集Model会被这两层的模块所引用。
第二类数据库对象则是数据的业务逻辑对象。这里所指的业务逻辑,并非业务逻辑层意义上的领域(domain)业务逻辑(从这个意义上,我更倾向于将业务逻辑层称为“领域逻辑层”),一般意义上说,这些业务逻辑即为基本的数据库操作,包括Select,Insert,Update和Delete。由于这些业务逻辑对象,仅具有行为而与数据无关,因此它们均被抽象为一个单独的接口模块IDAL,例如数据表Order对应的接口IOrder:

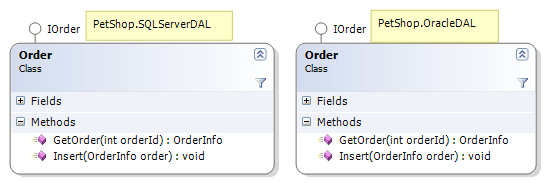
将数据实体与相关的数据库操作分离出来,符合面向对象的精神。首先,它体现了“职责分离”的原则。将数据实体与其行为分开,使得两者之间依赖减弱,当数据行为发生改变时,并不影响Model模块中的数据实体对象,避免了因一个类职责过多、过大,从而导致该类的引用者发生“灾难性”的影响。其次,它体现了“抽象”的精神,或者说是“面向接口编程”的最佳体现。抽象的接口模块IDAL,与具体的数据库访问实现完全隔离。这种与实现无关的设计,保证了系统的可扩展性,同时也保证了数据库的可移植性。在PetShop中,可以支持SQL Server和Oracle,那么它们具体的实现就分别放在两个不同的模块SQLServerDAL、OracleDAL中。
以Order为例,在SQLServerDAL、OracleDAL两个模块中,有不同的实现,但它们同时又都实现了IOrder接口,如图:
从数据库的实现来看,PetShop体现出了没有ORM框架的臃肿与丑陋。由于要对数据表进行Insert和Select操作,以SQL Server为例,就使用了SqlCommand,SqlParameter,SqlDataReader等对象,以完成这些操作。尤其复杂的是Parameter的传递,在PetShop中,使用了大量的字符串常量来保存参数的名称。此外,PetShop还专门为SQL Server和Oracle提供了抽象的Helper类,包装了一些常用的操作,如ExecuteNonQuery、ExecuteReader等方法。
在没有ORM的情况下,使用Helper类是一个比较好的策略,利用它来完成数据库基本操作的封装,可以减少很多和数据库操作有关的代码,这体现了对象复用的原则。PetShop将这些Helper类统一放到DBUtility模块中,不同数据库的Helper类暴露的方法基本相同,只除了一些特殊的要求,例如Oracle中处理bool类型的方式就和SQL Server不同,从而专门提供了OraBit和OraBool方法。此外,Helper类中的方法均为static方法,以利于调用。OracleHelper的类图如下:

对于数据访问层来说,最头疼的是SQL语句的处理。在早期的CS结构中,由于未采用三层式架构设计,数据访问层和业务逻辑层是紧密糅合在一起的,因此,SQL语句遍布与系统的每一个角落。这给程序的维护带来极大的困难。此外,由于Oracle使用的是PL-SQL,而SQL Server和Sybase等使用的是T-SQL,两者虽然都遵循了标准SQL的语法,但在很多细节上仍有区别,如果将SQL语句大量的使用到程序中,无疑为可能的数据库移植也带来了困难。
最好的方法是采用存储过程。这种方法使得程序更加整洁,此外,由于存储过程可以以数据库脚本的形式存在,也便于移植和修改。但这种方式仍然有缺陷。一是存储过程的测试相对困难。虽然有相应的调试工具,但比起对代码的调试而言,仍然比较复杂且不方便。二是对系统的更新带来障碍。如果数据库访问是由程序完成,在.Net平台下,我们仅需要在修改程序后,将重新编译的程序集xcopy到部署的服务器上即可。如果使用了存储过程,出于安全的考虑,必须有专门的DBA重新运行存储过程的脚本,部署的方式受到了限制。
我曾经在一个项目中,利用一个专门的表来存放SQL语句。如要使用相关的SQL语句,就利用关键字搜索获得对应语句。这种做法近似于存储过程的调用,但却避免了部署上的问题。然而这种方式却在性能上无法得到保证。它仅适合于SQL语句较少的场景。不过,利用良好的设计,我们可以为各种业务提供不同的表来存放SQL语句。同样的道理,这些SQL语句也可以存放到XML文件中,更有利于系统的扩展或修改。不过前提是,我们需要为它提供专门的SQL语句管理工具。
SQL语句的使用无法避免,如何更好的应用SQL语句也无定论,但有一个原则值得我们遵守,就是“应该尽量让SQL语句尽存在于数据访问层的具体实现中”。
当然,如果应用ORM,那么一切就变得不同了。因为ORM框架已经为数据访问提供了基本的Select,Insert,Update和Delete操作了。例如在NHibernate中,我们可以直接调用ISession对象的Save方法,来Insert(或者说是Create)一个数据实体对象:
public void Insert(OrderInfo order)
{
ISession s = Sessions.GetSession();
ITransaction trans = null;
try
{
trans = s.BeginTransaction();
s.Save( order);
trans.Commit();
}
finally
{
s.Close();
}
}
没有SQL语句,也没有那些烦人的Parameters,甚至不需要专门去考虑事务。此外,这样的设计,也是与数据库无关的,NHibernate可以通过Dialect(方言)的机制支持不同的数据库。唯一要做的是,我们需要为OrderInfo定义hbm文件。
当然,ORM框架并非是万能的,面对纷繁复杂的业务逻辑,它并不能完全消灭SQL语句,以及替代复杂的数据库访问逻辑,但它却很好的体现了“80/20(或90/10)法则”(也被称为“帕累托法则”),也就是说:花比较少(10%-20%)的力气就可以解决大部分(80%-90%)的问题,而要解决剩下的少部分问题则需要多得多的努力。至少,那些在数据访问层中占据了绝大部分的CRUD操作,通过利用ORM框架,我们就仅需要付出极少数时间和精力来解决它们了。这无疑缩短了整个项目开发的周期。
还是回到对PetShop的讨论上来。现在我们已经有了数据实体,数据对象的抽象接口和实现,可以说有关数据库访问的主体就已经完成了。留待我们的还有两个问题需要解决:
1、数据对象创建的管理
2、利于数据库的移植
在PetShop中,要创建的数据对象包括Order,Product,Category,Inventory,Item。在前面的设计中,这些对象已经被抽象为对应的接口,而其实现则根据数据库的不同而有所不同。也就是说,创建的对象有多种类别,而每种类别又有不同的实现,这是典型的抽象工厂模式的应用场景。而上面所述的两个问题,也都可以通过抽象工厂模式来解决。标准的抽象工厂模式类图如下:

例如,创建SQL Server的Order对象如下:
PetShopFactory factory = new SQLServerFactory(); IOrder = factory.CreateOrder();
要考虑到数据库的可移植性,则factory必须作为一个全局变量,并在主程序运行时被实例化。但这样的设计虽然已经达到了“封装变化”的目的,但在创建PetShopFactory对象时,仍不可避免的出现了具体的类SQLServerFactory,也即是说,程序在这个层面上产生了与SQLServerFactory的强依赖。一旦整个系统要求支持Oracle,那么还需要修改这行代码为:
PetShopFactory factory = new OracleFactory();
修改代码的这种行为显然是不可接受的。解决的办法是“依赖注入”。“依赖注入”的功能通常是用专门的IoC容器提供的,在Java平台下,这样的容器包括Spring,PicoContainer等。而在.Net平台下,最常见的则是Spring.Net。不过,在PetShop系统中,并不需要专门的容器来实现“依赖注入”,简单的做法还是利用配置文件和反射功能来实现。也就是说,我们可以在web.config文件中,配置好具体的Factory对象的完整的类名。然而,当我们利用配置文件和反射功能时,具体工厂的创建就显得有些“画蛇添足”了,我们完全可以在配置文件中,直接指向具体的数据库对象实现类,例如PetShop.SQLServerDAL.IOrder。那么,抽象工厂模式中的相关工厂就可以简化为一个工厂类了,所以我将这种模式称之为“具有简单工厂特质的抽象工厂模式”,其类图如下:
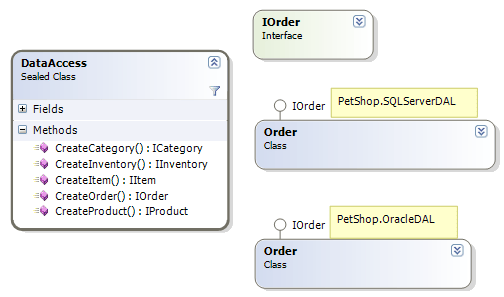
DataAccess类完全取代了前面创建的工厂类体系,它是一个sealed类,其中创建各种数据对象的方法,均为静态方法。之所以能用这个类达到抽象工厂的目的,是因为配置文件和反射的运用,如下的代码片断所示:
public sealed class DataAccess
{
// Look up the DAL implementation we should be using
private static readonly string path = ConfigurationManager.AppSettings["WebDAL"];
private static readonly string orderPath = ConfigurationManager.AppSettings["OrdersDAL"];
public static PetShop.IDAL.IOrder CreateOrder()
{
string className = orderPath + ".Order";
return (PetShop.IDAL.IOrder)Assembly.Load(orderPath).CreateInstance(className);
}
}
在PetShop中,这种依赖配置文件和反射创建对象的方式极其常见,包括IBLLStategy、CacheDependencyFactory等等。这些实现逻辑散布于整个PetShop系统中,在我看来,是可以在此基础上进行重构的。也就是说,我们可以为整个系统提供类似于“Service Locator”的实现:
public static class ServiceLocator
{
private static readonly string dalPath = ConfigurationManager.AppSettings["WebDAL"];
private static readonly string orderPath = ConfigurationManager.AppSettings["OrdersDAL"];
//……
private static readonly string orderStategyPath = ConfigurationManager.AppSettings["OrderStrategyAssembly"];
public static object LocateDALObject(string className)
{
string fullPath = dalPath + "." + className;
return Assembly.Load(dalPath).CreateInstance(fullPath);
}
public static object LocateDALOrderObject(string className)
{
string fullPath = orderPath + "." + className;
return Assembly.Load(orderPath).CreateInstance(fullPath);
}
public static object LocateOrderStrategyObject(string className)
{
string fullPath = orderStategyPath + "." + className;
return Assembly.Load(orderStategyPath).CreateInstance(fullPath);
}
//……
}
那么和所谓“依赖注入”相关的代码都可以利用ServiceLocator来完成。例如类DataAccess就可以简化为:
public sealed class DataAccess
{
public static PetShop.IDAL.IOrder CreateOrder()
{
return (PetShop.IDAL.IOrder)ServiceLocator. LocateDALOrderObject("Order");
}
}
通过ServiceLocator,将所有与配置文件相关的namespace值统一管理起来,这有利于各种动态创建对象的管理和未来的维护。
以上就是PetShop数据访问设计的全部内容,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

《解剖PetShop》之四:PetShop之ASP.NET缓存
四 PetShop之ASP.NET缓存 如果对微型计算机硬件系统有足够的了解,那么我们对于Cache这个名词一定是耳熟能详的.在CPU以及主板的芯片中,都引入了这种名为高速缓冲存储器(Cache)的技术.因为Cache的存取速度比内存快,因而引入Cache能够有效的解决CPU与内存之间的速度不匹配问题.硬件系统可以利用Cache存储CPU访问概率高的那些数据,当CPU需要访问这些数据时,可以直接从Cache中读取,而不必访问存取速度相对较慢的内存,从而提高了CPU的工作效率.软件设计借鉴了硬件设
-
《解剖PetShop》之三:PetShop数据访问层之消息处理
三.PetShop数据访问层之消息处理 在进行系统设计时,除了对安全.事务等问题给与足够的重视外,性能也是一个不可避免的问题所在,尤其是一个B/S结构的软件系统,必须充分地考虑访问量.数据流量.服务器负荷的问题.解决性能的瓶颈,除了对硬件系统进行升级外,软件设计的合理性尤为重要. 在前面我曾提到,分层式结构设计可能会在一定程度上影响数据访问的性能,然而与它给设计人员带来的好处相比,几乎可以忽略.要提供整个系统的性能,还可以从数据库的优化着手,例如连接池的使用.建立索引.优化查询策略等等,例如在P
-
《解剖PetShop》之一:PetShop的系统架构设计
前言:PetShop是一个范例,微软用它来展示.Net企业系统开发的能力.业界有许多.Net与J2EE之争,许多数据是从微软的PetShop和Sun的PetStore而来.这种争论不可避免带有浓厚的商业色彩,对于我们开发人员而言,没有必要过多关注.然而PetShop随着版本的不断更新,至现在基于.Net 2.0的PetShop4.0为止,整个设计逐渐变得成熟而优雅,却又很多可以借鉴之处.PetShop是一个小型的项目,系统架构与代码都比较简单,却也凸现了许多颇有价值的设计与开发理念.本系列试图对
-
学会sql数据库关系图(Petshop)
很久以前就知道微软的Petshop的很经典,昨天抽出时间去学习,一开始还真的不适应,什么成员资格,还真的看不太懂,运行petshop想从登陆学起,但是用户名和密码都不知道,后来发现有更注册的页面,自己注册了一个页面,才发现还得从数据库出发.花了这么多时间最终还是回到了数据库,但是数据库中一张一张的表格找不到脚本,也不是自己设计的数据库,完全没有一点头绪,后来突然想起来sql有个数据库关系图,可以很快的适合数据库程序员很快的掌握数据库表之间的关系.于是开始了我的百度之旅,关于数据库的关系图的文章还
-
《解剖PetShop》之六:PetShop之表示层设计
六 PetShop之表示层设计 表示层(Presentation Layer)的设计可以给系统客户最直接的体验和最十足的信心.正如人与人的相交相识一样,初次见面的感觉总是永难忘怀的.一件交付给客户使用的产品,如果在用户界面(User Interface,UI)上缺乏吸引人的特色,界面不友好,操作不够体贴,即使这件产品性能非常优异,架构设计合理,业务逻辑都满足了客户的需求,却仍然难以讨得客户的欢心.俗语云:"佛要金装,人要衣装",特别是对于Web应用程序而言,Web网页就好比人的衣装,代
-
《解剖PetShop》之五:PetShop之业务逻辑层设计
五 PetShop之业务逻辑层设计 业务逻辑层(Business Logic Layer)无疑是系统架构中体现核心价值的部分.它的关注点主要集中在业务规则的制定.业务流程的实现等与业务需求有关的系统设计,也即是说它是与系统所应对的领域(Domain)逻辑有关,很多时候,我们也将业务逻辑层称为领域层.例如Martin Fowler在<Patterns of Enterprise Application Architecture>一书中,将整个架构分为三个主要的层:表示层.领域层和数据源层.作为领
-
《解剖PetShop》之二:PetShop数据访问层数之据库访问设计
二.PetShop数据访问层之数据库访问设计 在系列一中,我从整体上分析了PetShop的架构设计,并提及了分层的概念.从本部分开始,我将依次对各层进行代码级的分析,以求获得更加细致而深入的理解.在PetShop 4.0中,由于引入了ASP.Net 2.0的一些新特色,所以数据层的内容也更加的广泛和复杂,包括:数据库访问.Messaging.MemberShip.Profile四部分.在系列二中,我将介绍有关数据库访问的设计. 在PetShop中,系统需要处理的数据库对象分为两类:一是数据实体,
-
基于MVC5和Bootstrap的jQuery TreeView树形控件(二)之数据支持json字符串、list集合
在上篇给大家介绍了基于MVC5和Bootstrap的jQuery TreeView树形控件(一)之数据支持json字符串.list集合. 这种方式其实还是利用list集合的方式传给前台,只不过在前台做了一些小小的变化,而控制器代码也进行了部分的优化,值的一提的是:没用的ajax前后台交互舍弃掉了. 控制器代码如下: //实例化公共静态字典表集合 public static List<TC_DictionaryInfo> DInfo = new List<TC_DictionaryInfo
-
Python使用min、max函数查找二维数据矩阵中最小、最大值的方法
本文实例讲述了Python使用min.max函数查找二维数据矩阵中最小.最大值的方法.分享给大家供大家参考,具体如下: 简单使用min.max函数来得到二维数据矩阵中的最大最小值,很简单,这是因为工作需要用到一个东西所以先简单来写了一下: #!usr/bin/env python #encoding:utf-8 ''''' __Author__:沂水寒城 功能:找出来随机生成矩阵中的最大.最小值 ''' import time import random def random_matrix_ge
-
Python 实现使用dict 创建二维数据、DataFrame
Python 实现使用 dict 创建二维数据 dict 的 keys.values 分别作为二维数据的两列 In [16]: d = {1:'aa', 2:'bb', 3:'cc'} In [17]: arr = list(d.items()) # 关键的一步 In [18]: narr = np.array(arr) In [19]: narr Out[19]: array([['1', 'aa'], ['2', 'bb'], ['3', 'cc']], dtype='<U11') Pyth
-
Python二维列表的创建、转换以及访问详解
目录 一.概念 二.创建二维列表 1.追加一维列标来生成二维列标 2.直接赋值生成二维列表 三.一维列标与二维列表的转换 1.一维列表转换成二维列表 2.二维列表转换成一维列表 3.利用NumPy实现数组的变维操作 四.访问二维列表 1.访问行 2.访问元素 3.NumPy二维数组的访问 补充:二维列表的实战应用 总结 一.概念 二维列表的元素还是列表(列表的嵌套),称之为二维列表. 需要通过行标和列标来访问二维列表的元素 二.创建二维列表 1.追加一维列标来生成二维列标 生成一个4行3列的二维
-
PostgreSQL数据库中跨库访问解决方案
PostgreSQL跨库访问有3种方法:Schema,dblink,postgres_fdw. 方法A:在PG上建立不同SCHEMA,将数据和存储过程分别放到不同的schema上,经过权限管理后进行访问. 方法A的示例如下: 测试1(测试postgres超级用户对不同schema下对象的访问) 查看当前数据库中的schema postgres=# \dn List of schemas Name | Owner -------------------+--------- dbms_job_pro
-
将MySQL的表数据全量导入clichhouse库中
目录 一.环境 二.创建测试库表写入测试数据 一.环境 tidb06 mysql5.7.32 tidb05 clickhouse20.8.3.18 二.创建测试库表写入测试数据 tidb06库创建复制账户: GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'click_rep'@'172.16.0.246' identified by 'jwts996';flush privileges; Query OK, 0 row
-
用python生成(动态彩色)二维码的方法(使用myqr库实现)
最近真的感觉到了python生态的强大(倒吸一口凉气) 现在介绍一个可以生成动态二维码的库(myqr) 效果如图: 第一步要安装myqr库 在cmd中直接用pip安装 pip install myqr 第二步 from MyQR import myqr import os version, level, qr_name = myqr.run( words="https://www.baidu.com", # 可以是字符串,也可以是网址(前面要加http(s)://) version=1
-
Nginx如何限制IP访问只允许特定域名访问
目录 1.找到 nginx 的配置文件 2.添加新的 server 3.修改 server 4.访问测试 总结 为了我们的服务器安全,我们需要禁止直接使用 IP 访问我们的服务器,我们可以借助 Nginx 完成 1.找到 nginx 的配置文件 cd /usr/local/nginx/conf/ 找到 nginx.conf 文件 编辑它 2.添加新的 server # 禁止ip访问 server { listen 80 default_server; listen 443 ssl default
-
在ASP.NET 2.0中操作数据之三十二:数据控件的嵌套
导言 除了静态HTML和数据绑定语法,template也可以包含Web控件和用户控件.这些控件的属性可以通过声明语法,数据绑定语法或在服务器端通过事件处理编程来设置. 通过将控件嵌入到template里,可以自定义界面,提升用户体验.例如,在在GridView控件中使用TemplateField 里,我们学习了如何通过在GridView的TemplateField里加一个Calendar控件来表示员工的雇佣日期.在给编辑和新增界面增加验证控件 和定制数据修改界面 里,我们学习了如何通过添加验证控