零基础写Java知乎爬虫之进阶篇
说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnection还是不够的。
在这里我们可以使用HttpClient这个第三方jar包。
接下来我们使用HttpClient简单的写一个爬去百度的Demo:
import java.io.FileOutputStream;import java.io.InputStream;import java.io.OutputStream;import org.apache.commons.httpclient.HttpClient;import org.apache.commons.httpclient.HttpStatus;import org.apache.commons.httpclient.methods.GetMethod;/** * * @author CallMeWhy * */public class Spider { private static HttpClient httpClient = new HttpClient(); /** * @param path * 目标网页的链接 * @return 返回布尔值,表示是否正常下载目标页面 * @throws Exception * 读取网页流或写入本地文件流的IO异常 */ public static boolean downloadPage(String path) throws Exception { // 定义输入输出流 InputStream input = null; OutputStream output = null; // 得到 post 方法 GetMethod getMethod = new GetMethod(path); // 执行,返回状态码 int statusCode = httpClient.executeMethod(getMethod); // 针对状态码进行处理 // 简单起见,只处理返回值为 200 的状态码 if (statusCode == HttpStatus.SC_OK) { input = getMethod.getResponseBodyAsStream(); // 通过对URL的得到文件名 String filename = path.substring(path.lastIndexOf('/') + 1) + ".html"; // 获得文件输出流 output = new FileOutputStream(filename); // 输出到文件 int tempByte = -1; while ((tempByte = input.read()) > 0) { output.write(tempByte); } // 关闭输入流 if (input != null) { input.close(); } // 关闭输出流 if (output != null) { output.close(); } return true; } return false; } public static void main(String[] args) { try { // 抓取百度首页,输出 Spider.downloadPage("http://www.baidu.com"); } catch (Exception e) { e.printStackTrace(); } }}
但是这样基本的爬虫是不能满足各色各样的爬虫需求的。
先来介绍宽度优先爬虫。
宽度优先相信大家都不陌生,简单说来可以这样理解宽度优先爬虫。
我们把互联网看作一张超级大的有向图,每一个网页上的链接都是一个有向边,每一个文件或没有链接的纯页面则是图中的终点:
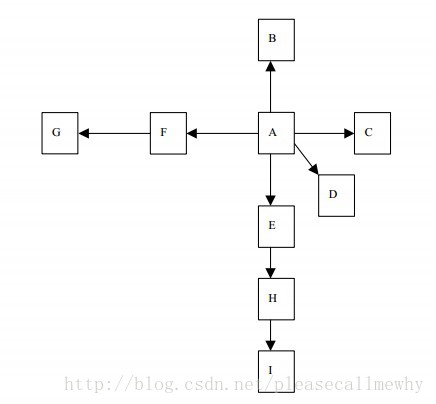
宽度优先爬虫就是这样一个爬虫,爬走在这个有向图上,从根节点开始一层一层往外爬取新的节点的数据。
宽度遍历算法如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col,转到步骤(5),若 V 的所有邻接顶点都已经被访问过,则转到步骤(2)。
按照宽度遍历算法,上图的遍历顺序为:A->B->C->D->E->F->H->G->I,这样一层一层的遍历下去。
而宽度优先爬虫其实爬取的是一系列的种子节点,和图的遍历基本相同。
我们可以把需要爬取页面的URL都放在一个TODO表中,将已经访问的页面放在一个Visited表中:

则宽度优先爬虫的基本流程如下:
(1) 把解析出的链接和 Visited 表中的链接进行比较,若 Visited 表中不存在此链接, 表示其未被访问过。
(2) 把链接放入 TODO 表中。
(3) 处理完毕后,从 TODO 表中取得一条链接,直接放入 Visited 表中。
(4) 针对这个链接所表示的网页,继续上述过程。如此循环往复。
下面我们就来一步一步制作一个宽度优先的爬虫。
首先,对于先设计一个数据结构用来存储TODO表, 考虑到需要先进先出所以采用队列,自定义一个Quere类:
import java.util.LinkedList;/** * 自定义队列类 保存TODO表 */public class Queue { /** * 定义一个队列,使用LinkedList实现 */ private LinkedList<Object> queue = new LinkedList<Object>(); // 入队列 /** * 将t加入到队列中 */ public void enQueue(Object t) { queue.addLast(t); } /** * 移除队列中的第一项并将其返回 */ public Object deQueue() { return queue.removeFirst(); } /** * 返回队列是否为空 */ public boolean isQueueEmpty() { return queue.isEmpty(); } /** * 判断并返回队列是否包含t */ public boolean contians(Object t) { return queue.contains(t); } /** * 判断并返回队列是否为空 */ public boolean empty() { return queue.isEmpty(); }}
还需要一个数据结构来记录已经访问过的 URL,即Visited表。
考虑到这个表的作用,每当要访问一个 URL 的时候,首先在这个数据结构中进行查找,如果当前的 URL 已经存在,则丢弃这个URL任务。
这个数据结构需要不重复并且能快速查找,所以选择HashSet来存储。
综上,我们另建一个SpiderQueue类来保存Visited表和TODO表:
import java.util.HashSet;import java.util.Set;/** * 自定义类 保存Visited表和unVisited表 */public class SpiderQueue { /** * 已访问的url集合,即Visited表 */ private static Set<Object> visitedUrl = new HashSet<>(); /** * 添加到访问过的 URL 队列中 */ public static void addVisitedUrl(String url) { visitedUrl.add(url); } /** * 移除访问过的 URL */ public static void removeVisitedUrl(String url) { visitedUrl.remove(url); } /** * 获得已经访问的 URL 数目 */ public static int getVisitedUrlNum() { return visitedUrl.size(); } /** * 待访问的url集合,即unVisited表 */ private static Queue unVisitedUrl = new Queue(); /** * 获得UnVisited队列 */ public static Queue getUnVisitedUrl() { return unVisitedUrl; } /** * 未访问的unVisitedUrl出队列 */ public static Object unVisitedUrlDeQueue() { return unVisitedUrl.deQueue(); } /** * 保证添加url到unVisitedUrl的时候每个 URL只被访问一次 */ public static void addUnvisitedUrl(String url) { if (url != null && !url.trim().equals("") && !visitedUrl.contains(url) && !unVisitedUrl.contians(url)) unVisitedUrl.enQueue(url); } /** * 判断未访问的 URL队列中是否为空 */ public static boolean unVisitedUrlsEmpty() { return unVisitedUrl.empty(); }}
上面是一些自定义类的封装,接下来就是一个定义一个用来下载网页的工具类,我们将其定义为DownTool类:
package controller;import java.io.*;import org.apache.commons.httpclient.*;import org.apache.commons.httpclient.methods.*;import org.apache.commons.httpclient.params.*;public class DownTool { /** * 根据 URL 和网页类型生成需要保存的网页的文件名,去除 URL 中的非文件名字符 */ private String getFileNameByUrl(String url, String contentType) { // 移除 "http://" 这七个字符 url = url.substring(7); // 确认抓取到的页面为 text/html 类型 if (contentType.indexOf("html") != -1) { // 把所有的url中的特殊符号转化成下划线 url = url.replaceAll("[\\?/:*|<>\"]", "_") + ".html"; } else { url = url.replaceAll("[\\?/:*|<>\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1); } return url; } /** * 保存网页字节数组到本地文件,filePath 为要保存的文件的相对地址 */ private void saveToLocal(byte[] data, String filePath) { try { DataOutputStream out = new DataOutputStream(new FileOutputStream( new File(filePath))); for (int i = 0; i < data.length; i++) out.write(data[i]); out.flush(); out.close(); } catch (IOException e) { e.printStackTrace(); } } // 下载 URL 指向的网页 public String downloadFile(String url) { String filePath = null; // 1.生成 HttpClinet对象并设置参数 HttpClient httpClient = new HttpClient(); // 设置 HTTP连接超时 5s httpClient.getHttpConnectionManager().getParams() .setConnectionTimeout(5000); // 2.生成 GetMethod对象并设置参数 GetMethod getMethod = new GetMethod(url); // 设置 get请求超时 5s getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000); // 设置请求重试处理 getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler()); // 3.执行GET请求 try { int statusCode = httpClient.executeMethod(getMethod); // 判断访问的状态码 if (statusCode != HttpStatus.SC_OK) { System.err.println("Method failed: " + getMethod.getStatusLine()); filePath = null; } // 4.处理 HTTP 响应内容 byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组 // 根据网页 url 生成保存时的文件名 filePath = "temp\\" + getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type") .getValue()); saveToLocal(responseBody, filePath); } catch (HttpException e) { // 发生致命的异常,可能是协议不对或者返回的内容有问题 System.out.println("请检查你的http地址是否正确"); e.printStackTrace(); } catch (IOException e) { // 发生网络异常 e.printStackTrace(); } finally { // 释放连接 getMethod.releaseConnection(); } return filePath; }}
在这里我们需要一个HtmlParserTool类来处理Html标记:
package controller;import java.util.HashSet;import java.util.Set;import org.htmlparser.Node;import org.htmlparser.NodeFilter;import org.htmlparser.Parser;import org.htmlparser.filters.NodeClassFilter;import org.htmlparser.filters.OrFilter;import org.htmlparser.tags.LinkTag;import org.htmlparser.util.NodeList;import org.htmlparser.util.ParserException;import model.LinkFilter;public class HtmlParserTool { // 获取一个网站上的链接,filter 用来过滤链接 public static Set<String> extracLinks(String url, LinkFilter filter) { Set<String> links = new HashSet<String>(); try { Parser parser = new Parser(url); parser.setEncoding("gb2312"); // 过滤 <frame >标签的 filter,用来提取 frame 标签里的 src 属性 NodeFilter frameFilter = new NodeFilter() { private static final long serialVersionUID = 1L; @Override public boolean accept(Node node) { if (node.getText().startsWith("frame src=")) { return true; } else { return false; } } }; // OrFilter 来设置过滤 <a> 标签和 <frame> 标签 OrFilter linkFilter = new OrFilter(new NodeClassFilter( LinkTag.class), frameFilter); // 得到所有经过过滤的标签 NodeList list = parser.extractAllNodesThatMatch(linkFilter); for (int i = 0; i < list.size(); i++) { Node tag = list.elementAt(i); if (tag instanceof LinkTag)// <a> 标签 { LinkTag link = (LinkTag) tag; String linkUrl = link.getLink();// URL if (filter.accept(linkUrl)) links.add(linkUrl); } else// <frame> 标签 { // 提取 frame 里 src 属性的链接, 如 <frame src="test.html"/> String frame = tag.getText(); int start = frame.indexOf("src="); frame = frame.substring(start); int end = frame.indexOf(" "); if (end == -1) end = frame.indexOf(">"); String frameUrl = frame.substring(5, end - 1); if (filter.accept(frameUrl)) links.add(frameUrl); } } } catch (ParserException e) { e.printStackTrace(); } return links; }}
最后我们来写个爬虫类调用前面的封装类和函数:
package controller;import java.util.Set;import model.LinkFilter;import model.SpiderQueue;public class BfsSpider { /** * 使用种子初始化URL队列 */ private void initCrawlerWithSeeds(String[] seeds) { for (int i = 0; i < seeds.length; i++) SpiderQueue.addUnvisitedUrl(seeds[i]); } // 定义过滤器,提取以 http://www.xxxx.com开头的链接 public void crawling(String[] seeds) { LinkFilter filter = new LinkFilter() { public boolean accept(String url) { if (url.startsWith("http://www.baidu.com")) return true; else return false; } }; // 初始化 URL 队列 initCrawlerWithSeeds(seeds); // 循环条件:待抓取的链接不空且抓取的网页不多于 1000 while (!SpiderQueue.unVisitedUrlsEmpty() && SpiderQueue.getVisitedUrlNum() <= 1000) { // 队头 URL 出队列 String visitUrl = (String) SpiderQueue.unVisitedUrlDeQueue(); if (visitUrl == null) continue; DownTool downLoader = new DownTool(); // 下载网页 downLoader.downloadFile(visitUrl); // 该 URL 放入已访问的 URL 中 SpiderQueue.addVisitedUrl(visitUrl); // 提取出下载网页中的 URL Set<String> links = HtmlParserTool.extracLinks(visitUrl, filter); // 新的未访问的 URL 入队 for (String link : links) { SpiderQueue.addUnvisitedUrl(link); } } } // main 方法入口 public static void main(String[] args) { BfsSpider crawler = new BfsSpider(); crawler.crawling(new String[] { "http://www.baidu.com" }); }}
运行可以看到,爬虫已经把百度网页下所有的页面都抓取出来了:

以上就是java使用HttpClient工具包和宽度爬虫进行抓取内容的操作的全部内容,稍微复杂点,小伙伴们要仔细琢磨下哦,希望对大家能有所帮助
相关推荐
-
java实现简单的爬虫之今日头条
前言 需要提前说下的是,由于今日头条的文章的特殊性,所以无法直接获取文章的地址,需要获取文章的id然后在拼接成url再访问.下面话不多说了,直接上代码. 示例代码如下 public class Demo2 { public static void main(String[] args) { // 需要爬的网页的文章列表 String url = "http://www.toutiao.com/news_finance/"; //文章详情页的前缀(由于今日头条的文章都是在group这个目
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-

Java爬虫抓取视频网站下载链接
本篇文章抓取目标网站的链接的基础上,进一步提高难度,抓取目标页面上我们所需要的内容并保存在数据库中.这里的测试案例选用了一个我常用的电影下载网站(http://www.80s.la/).本来是想抓取网站上的所有电影的下载链接,后来感觉需要的时间太长,因此改成了抓取2015年电影的下载链接. 一 原理简介 其实原理都跟第一篇文章差不多,不同的是鉴于这个网站的分类列表实在太多,如果不对这些标签加以取舍的话,需要花费的时间难以想象. 分类链接和标签链接都不要,不通过这些链接去爬取其他页面,只通过页底的
-
Java爬虫实战抓取一个网站上的全部链接
前言:写这篇文章之前,主要是我看了几篇类似的爬虫写法,有的是用的队列来写,感觉不是很直观,还有的只有一个请求然后进行页面解析,根本就没有自动爬起来这也叫爬虫?因此我结合自己的思路写了一下简单的爬虫. 一 算法简介 程序在思路上采用了广度优先算法,对未遍历过的链接逐次发起GET请求,然后对返回来的页面用正则表达式进行解析,取出其中未被发现的新链接,加入集合中,待下一次循环时遍历. 具体实现上使用了Map<String, Boolean>,键值对分别是链接和是否被遍历标志.程序中使用了两个Map集
-
Java 从互联网上爬邮箱代码示例
网页爬虫:其实就是一个程序用于在互联网中获取符合指定规则的数据. package day05; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URL; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; impor
-
基于Java HttpClient和Htmlparser实现网络爬虫代码
开发环境的搭建,在工程的 Build Path 中导入下载的Commons-httpClient3.1.Jar,htmllexer.jar 以及 htmlparser.jar 文件. 图 1. 开发环境搭建 HttpClient 基本类库使用 HttpClinet 提供了几个类来支持 HTTP 访问.下面我们通过一些示例代码来熟悉和说明这些类的功能和使用. HttpClient 提供的 HTTP 的访问主要是通过 GetMethod 类和 PostMethod 类来实现的,他们分别对应了 HTT
-
零基础写Java知乎爬虫之进阶篇
说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnection还是不够的. 在这里我们可以使用HttpClient这个第三方jar包. 接下来我们使用HttpClient简单的写一个爬去百度的Demo: import java.io.FileOutputStream;import java.io.InputStream;import java.io.OutputStr
-
零基础写Java知乎爬虫之将抓取的内容存储到本地
说到Java的本地存储,肯定使用IO流进行操作. 首先,我们需要一个创建文件的函数createNewFile: 复制代码 代码如下: public static boolean createNewFile(String filePath) { boolean isSuccess = true; // 如有则将"\\"转为"/",没有则不产生任何变化 String filePathTurn = filePath.r
-
零基础写Java知乎爬虫之先拿百度首页练练手
上一集中我们说到需要用Java来制作一个知乎爬虫,那么这一次,我们就来研究一下如何使用代码获取到网页的内容. 首先,没有HTML和CSS和JS和AJAX经验的建议先去W3C(点我点我)小小的了解一下. 说到HTML,这里就涉及到一个GET访问和POST访问的问题. 如果对这个方面缺乏了解可以阅读W3C的这篇:<GET对比POST>. 啊哈,在此不再赘述. 然后咧,接下来我们需要用Java来爬取一个网页的内容. 这时候,我们的百度就要派上用场了. 没错,他不再是那个默默无闻的网速测试器了,他即将
-
零基础写Java知乎爬虫之获取知乎编辑推荐内容
知乎是一个真实的网络问答社区,社区氛围友好.理性.认真,连接各行各业的精英.他们分享着彼此的专业知识.经验和见解,为中文互联网源源不断地提供高质量的信息. 首先花个三五分钟设计一个Logo=.=作为一个程序员我一直有一颗做美工的心! 好吧做的有点小凑合,就先凑合着用咯. 接下来呢,我们开始制作知乎的爬虫. 首先,确定第一个目标:编辑推荐. 网页链接:http://www.zhihu.com/explore/recommendations 我们对上次的代码稍作修改,先实现能够获取该页面内容: im
-
零基础写Java知乎爬虫之准备工作
开篇我们还是和原来一样,讲一讲做爬虫的思路以及需要准备的知识吧,高手们请直接忽略. 首先我们来缕一缕思绪,想想到底要做什么,列个简单的需求. 需求如下: 1.模拟访问知乎官网(http://www.zhihu.com/) 2.下载指定的页面内容,包括:今日最热,本月最热,编辑推荐 3.下载指定分类中的所有问答,比如:投资,编程,挂科 4.下载指定回答者的所有回答 5.最好有个一键点赞的变态功能(这样我就可以一下子给雷伦的所有回答都点赞了我真是太机智了!) 那么需要解决的技术问题简单罗列如下: 1
-
零基础写Java知乎爬虫之抓取知乎答案
前期我们抓取标题是在该链接下: http://www.zhihu.com/explore/recommendations 但是显然这个页面是无法获取答案的. 一个完整问题的页面应该是这样的链接: http://www.zhihu.com/question/22355264 仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述: import java.util.ArrayList;public class Zhihu { public St
-
零基础学Java:Java开发工具 Eclipse 安装过程创建第一个Java项目及Eclipse的一些基础使用技巧
一.下载https://www.eclipse.org/downloads/download.php?file=/oomph/epp/2020-06/R/eclipse-inst-win64.exe&mirror_id=1142 二.安装Eclipse 三.开始使用Eclipse,并创建第一个Java项目 src 鼠标右键 -- New --Class 四.一些基础操作 1.字体大小修改(咋一看感觉这字体太小了,看起来不舒服) Window -- Preferences 2.项目运行 3.当一些
-
零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
零基础写python爬虫之神器正则表达式
接下来准备用糗百做一个爬虫的小例子. 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容. 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器. 一. 正则表达式基础 1.1.概念介绍 正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下
-
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件. 项目内容: 用Python写的百度贴吧的网络爬虫. 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行. 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地. 原理解释: 首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了: http://tieba.baidu.com/p/2296712428?see_lz=1&pn=