基于SQL Server中如何比较两个表的各组数据 图解说明
开始
前一阵子,在项目中碰到这样一个SQL查询需求,有两个相同结构的表(table_left & table_right),如下:
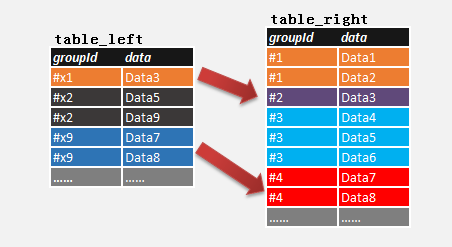
图1.
检查表table_left的各组(groupId),是否在表table_right中存在有一组(groupId)数据(data)与它的数据(data)完全相等.
如图1. 可以看出表table_left和table_right存在两组数据完整相等:

图2.
分析
从上面的两个表,可以知道它们存放的是一组一组的数据;那么,接下来我借助数学集合的列举法和运算进行分析。
先通过集合的列举法描述两个表的各组数据:
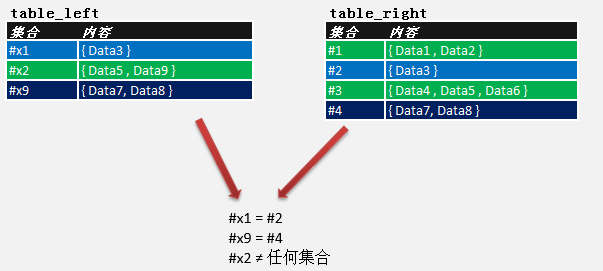
图3.
这里只有两种情况,相等和不相等。对于不相等,可再分为部分相等、包含、和完全不相等。使用集合描述,可使用交集,子集,并集。如下面图4.,我列举出这几种常见的情况:
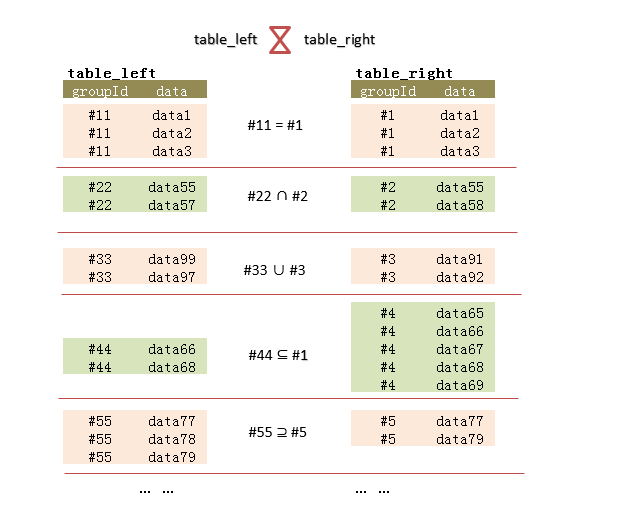
图4.
实现
在数据库中,要找出表table_left和表table_right存在相同数据的组,方法很多,这里我列出两种常用的方法。
(下面的SQL脚本,是以图4.的数据为基础参考)
方法1:
通过"Select … From …Order by … xml for path('') "把各组的data列数据连串起来(如,图4.把table_left的组#11的列data连串起来成"data1-data2-data3"),其他分组(包含表table_right)以此方法实现data列数据连串起来;然后通过比较两表的连串后字段是否存在相等,若是相等就说明这比较多两组数据相等,由此可以判断出表table_left的哪组数据在表table_right存在与它数据完全相等的组。
针对方法1,需要对原表增加一个字段dataPath,用于存储data列数据连串的结果,如:
alter table table_left add dataPath nvarchar(200)
alter table table_right add dataPath nvarchar(200)
分组连串data列数据并update至刚新增的列dataPath,如:
update a
set dataPath=b.dataPath
from table_left a
cross apply(select (select '-'+x.data from table_left x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
update a
set dataPath=b.dataPath
from table_right a
cross apply(select (select '-'+x.data from table_right x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
接下来就是查询了,如:
select distinct a.groupId
from table_left a
where exists(select 1 from table_right x where x.dataPath=a.dataPath)

完整代码:
View Code
use tempdb
go
if object_id('table_left') is not null drop table table_left
if object_id('table_right') is not null drop table table_right
go
create table table_left(groupId nvarchar(5),data nvarchar(10))
create table table_right(groupId nvarchar(5),data nvarchar(10))
go
alter table table_left add dataPath nvarchar(200)
alter table table_right add dataPath nvarchar(200)
go
create nonclustered index ix_left on table_left(dataPath)
create nonclustered index ix_right on table_right(dataPath)
go
set nocount on
go
insert into table_right(groupId,data)
select '#1','data1' union all
select '#1','data2' union all
select '#1','data3' union all
select '#2','data55' union all
select '#2','data55' union all
select '#3','data91' union all
select '#3','data92' union all
select '#4','data65' union all
select '#4','data66' union all
select '#4','data67' union all
select '#4','data68' union all
select '#4','data69' union all
select '#5','data77' union all
select '#5','data79'
insert into table_left(groupId,data)
select '#11','data1' union all
select '#11','data2' union all
select '#11','data3' union all
select '#22','data55' union all
select '#22','data57' union all
select '#33','data99' union all
select '#33','data99' union all
select '#44','data66' union all
select '#44','data68' union all
select '#55','data77' union all
select '#55','data78' union all
select '#55','data79'
go
update a
set dataPath=b.dataPath
from table_left a
cross apply(select (select '-'+x.data from table_left x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
update a
set dataPath=b.dataPath
from table_right a
cross apply(select (select '-'+x.data from table_right x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
--
select distinct a.groupId
from table_left a
where exists(select 1 from table_right x where x.dataPath=a.dataPath)
方法2:
通过SQL Sever提供的集运算符"Except",判断两组非重复的数据。如果两组针对对方都不存在非重复的数据,就说明这两组数据完全相等。如,表table_left中的组#11和表 table_right中的组#1,对列data进行"Except"集运算,无任是(#11 à #1)进行Except集运算,还是(#1 à #11 )进行Except集合运算,都返回空结果,这就说明组#1 和#11的data数据完全相等,如:
select data from table_left where groupId='#11' except select data from table_right where groupId='#1'
select data from table_right where groupId='#1' except select data from table_left where groupId='#11'
同样道理,我们把表table_left中的组#11和表 table_right中的组#2,对列data进行"Except"集运算,如:
select data from table_left where groupId='#11' except select data from table_right where groupId='#2'
select data from table_right where groupId='#2' except select data from table_left where groupId='#11'

只要(#11 à #2 )或 (#2 à #11 )的"Except"集运算结果有记录,就说明两组的数据不相等。
两张表的所有组都进行比较,我们需要通过以下SQL脚本实现,如:
select distinct a.groupId
from table_left a
inner join table_right b on b.data=a.data
where not exists(select x.data from table_left x where x.groupId=a.groupId except select y.data from table_right y where y.groupId=b.groupId )
and not exists(select x.data from table_right x where x.groupId=b.groupId except select y.data from table_left y where y.groupId=a.groupId )

完整代码:
View Code
use tempdb
go
if object_id('table_left') is not null drop table table_left
if object_id('table_right') is not null drop table table_right
go
create table table_left(groupId nvarchar(5),data nvarchar(10))
create table table_right(groupId nvarchar(5),data nvarchar(10))
go
create nonclustered index ix_left on table_left(data)
create nonclustered index ix_right on table_right(data)
go
set nocount on
go
insert into table_right(groupId,data)
select '#1','data1' union all
select '#1','data2' union all
select '#1','data3' union all
select '#2','data55' union all
select '#2','data55' union all
select '#3','data91' union all
select '#3','data92' union all
select '#4','data65' union all
select '#4','data66' union all
select '#4','data67' union all
select '#4','data68' union all
select '#4','data69' union all
select '#5','data77' union all
select '#5','data79'
insert into table_left(groupId,data)
select '#11','data1' union all
select '#11','data2' union all
select '#11','data3' union all
select '#22','data55' union all
select '#22','data57' union all
select '#33','data99' union all
select '#33','data99' union all
select '#44','data66' union all
select '#44','data68' union all
select '#55','data77' union all
select '#55','data78' union all
select '#55','data79'
go
--select
select distinct a.groupId
from table_left a
inner join table_right b on b.data=a.data
where not exists(select x.data from table_left x where x.groupId=a.groupId except select y.data from table_right y where y.groupId=b.groupId )
and not exists(select x.data from table_right x where x.groupId=b.groupId except select y.data from table_left y where y.groupId=a.groupId )
方法1 Vs. 方法2 :
方法1和方法2都能找出表table_left在table_right存在数据完全相等的组#11。但性能角度上,方法2比方法1略胜一筹,可以看它们执行过程的统计信息:
方法1:
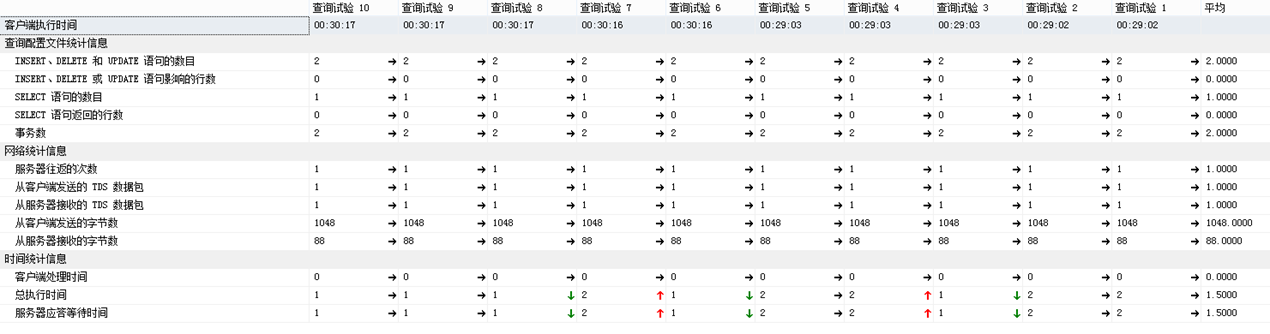
图5.
方法2:
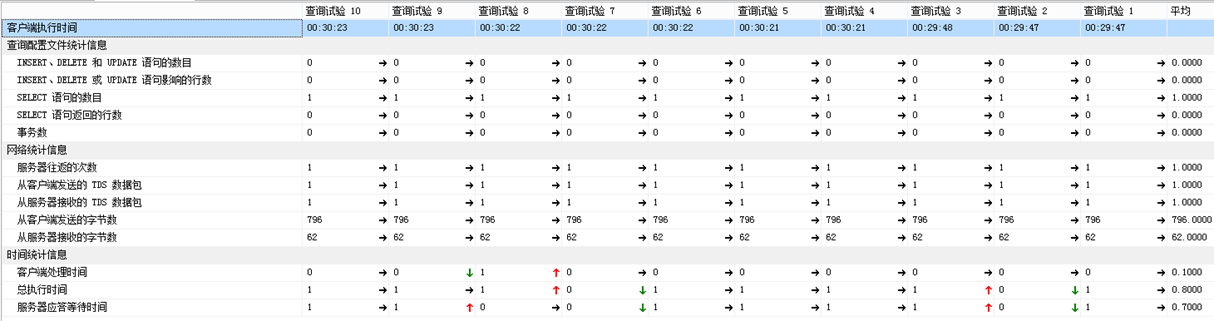
图6.
如果,数据量大情况下,那么方法2比方法1更具有明显的优点。因为方法1,多两个更新dataPath的部分,数据量随着增加,这里位置的更新就耗很多的资源;如果dataPath列数据大小超过900字节,会导致无法在dataPath创建索引,影响后面的Select查询性能。
扩展
这里说扩展,主要是针对上面的方法2来说。在当列data的数据大小超过900字节,或者含有多个数据列要进行比较,看是否存在两组(groupId)的各对应列数据一一相等。
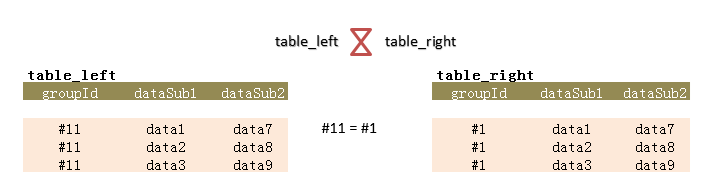
图7.
这样的情况,可对字段dataSub1 & dataSub2 创建一个哈希索引,如:
alter table table_left add dataChecksum as checksum(dataSub1,dataSub2)
alter table table_right add dataChecksum as checksum(dataSub1,dataSub2)
go
create nonclustered index ix_table_left_cs on table_right(dataChecksum)
create nonclustered index table_right_cs on table_right(dataChecksum)
后面的select查询语句,在Inner Join 部分稍改动下即可,如:
select distinct a.groupId
from table_left a
inner join table_right b on b.dataChecksum=a.dataChecksum
and b.dataSub1=a.dataSub1
and b.dataSub2=a.dataSub2
where not exists(select x.dataSub1,x.dataSub2 from table_left x where x.groupId=a.groupId except select y.dataSub1,y.dataSub2 from table_right y where y.groupId=b.groupId )
and not exists(select x.dataSub1,x.dataSub2 from table_right x where x.groupId=b.groupId except select y.dataSub1,y.dataSub2 from table_left y where y.groupId=a.groupId )
完整代码:
View Code
use tempdb
go
if object_id('table_left') is not null drop table table_left
if object_id('table_right') is not null drop table table_right
go
create table table_left(groupId nvarchar(5),dataSub1 nvarchar(10),dataSub2 nvarchar(10))
create table table_right(groupId nvarchar(5),dataSub1 nvarchar(10),dataSub2 nvarchar(10))
go
alter table table_left add dataChecksum as checksum(dataSub1,dataSub2)
alter table table_right add dataChecksum as checksum(dataSub1,dataSub2)
go
create nonclustered index ix_table_left_cs on table_left(dataChecksum)
create nonclustered index table_right_cs on table_right(dataChecksum)
go
set nocount on
go
insert into table_right(groupId,dataSub1,dataSub2)
select '#1','data1','data7' union all
select '#1','data2','data8' union all
select '#1','data3','data9' union all
select '#2','data55','data4' union all
select '#2','data55','data5'
insert into table_left(groupId,dataSub1,dataSub2)
select '#11','data1','data7' union all
select '#11','data2','data8' union all
select '#11','data3','data9' union all
select '#22','data55','data0' union all
select '#22','data57','data2' union all
select '#33','data99','data4' union all
select '#33','data99','data6'
go
--select
select distinct a.groupId
from table_left a
inner join table_right b on b.dataChecksum=a.dataChecksum
and b.dataSub1=a.dataSub1
and b.dataSub2=a.dataSub2
where not exists(select x.dataSub1,x.dataSub2 from table_left x where x.groupId=a.groupId except select y.dataSub1,y.dataSub2 from table_right y where y.groupId=b.groupId )
and not exists(select x.dataSub1,x.dataSub2 from table_right x where x.groupId=b.groupId except select y.dataSub1,y.dataSub2 from table_left y where y.groupId=a.groupId )
小结
对于这个问题,可能还有其他的或更优的解决方法.而且在实际的生产环境中,可能碰到的情况会有所不同,无论如何,需要多分析,多动手多实验,找到最优的解决方法。
相关推荐
-

基于SQL Server中如何比较两个表的各组数据 图解说明
开始 前一阵子,在项目中碰到这样一个SQL查询需求,有两个相同结构的表(table_left & table_right),如下: 图1. 检查表table_left的各组(groupId),是否在表table_right中存在有一组(groupId)数据(data)与它的数据(data)完全相等. 如图1. 可以看出表table_left和table_right存在两组数据完整相等: 图2. 分析 从上面的两个表,可以知道它们存放的是一组一组的数据:那么,接下来我借助数学集合的列举法和运算进行
-
基于SQL Server中char,nchar,varchar,nvarchar的使用区别
对于程序中的一般字符串类型的字段,SQL Server中有char.varchar.nchar.nvarchar四种类型来对应,那么这四种类型有什么区别呢,这里做一下对比. 1.定长或变长 所谓定长就是长度固定,当要保存的数据长度不够时将自动在其后面填充英文空格,使长度达到相应的长度:有var前缀的,表示是实际存储空间是动态变化的,比如varchar,nvarchar变长字符数据则不会以空格填充. 2.Unicode或非Unicode 数据库中,英文字符只需要一个字节存储就足够了,但汉字和其他众
-
SQL Server中的数据类型详解
目录 哪些对象需要数据类型 一. 整数数据类型 1.bit 2.tinyint 3.smallint 4.int (integer) 5.bigint 二. 浮点数据类型 1.real: 近似数值型 2.float[(n)]:近似数值型 3.decimal[p [s] ] 4.numeric[p [s] ] 5.smallMoney货币型 6.money货币型 三.字符数据类型 1.char[(n)] 2.nchar[(n)] 3.varchar[(n| max )] 4.nvarchar[(n
-
sql server中错误日志errorlog的深入讲解
一 .概述 SQL Server 将某些系统事件和用户定义事件记录到 SQL Server 错误日志和 Microsoft Windows 应用程序日志中. 这两种日志都会自动给所有记录事件加上时间戳. 使用 SQL Server 错误日志中的信息可以解决SQL Server的相关问题. 查看 SQL Server 错误日志可以确保进程(例如,备份和还原操作.批处理命令或其他脚本和进程)成功完成. 此功能可用于帮助检测任何当前或潜在的问题领域,包括自动恢复消息(尤其是在 SQL Server 实
-
SQL Server中的执行引擎入门 图解
本文旨在分类讲述执行计划中每一种操作的相关信息. 数据访问操作 首先最基本的操作就是访问数据.这既可以通过直接访问表,也可以通过访问索引来进行.表内数据的组织方式分为堆(Heap)和B树,其中表中没有建立聚集索引时数据是通过堆进行组织的,这个是无序的,表中建立聚集索引后和非聚集索引的数据都是以B树方式进行组织,这种方式数据是有序存储的.通常来说,非聚集索引仅仅包含整个表的部分列,对于过滤索引,还仅仅包含部分行. 除去数据的组织方式不同外,访问数据也分为两种方式,扫描(Scan)和查找(Seek)
-
SQL Server中数据行批量插入脚本的存储实现
无意中看到朋友写的一篇文章"将表里的数据批量生成INSERT语句的存储过程的实现".我仔细看文中的两个存储代码,自我感觉两个都不太满意,都是生成的单行模式的插入,数据行稍微大些性能会受影响的.所在公司本来就存在第二个版本的类似实现,但是是基于多行模式的,还是需要手工添加UNAION ALL来满足多行模式的插入.看到这篇博文和基于公司数据行批量脚本的存储的缺点,这次改写和增强该存储的功能. 本存储运行于SQL Server 2005或以上版本,T-SQL代码如下: IF OBJECT_I
-
浅析SQL Server中的执行计划缓存(下)
在上篇文章给大家介绍了SQL Server中的执行计划缓存(上),本文继续给大家介绍sqlserver执行计划缓存相关知识,小伙伴们一起学习吧. 简介 在上篇文章中我们谈到了查询优化器和执行计划缓存的关系,以及其二者之间的冲突.本篇文章中,我们会主要阐述执行计划缓存常见的问题以及一些解决办法. 将执行缓存考虑在内时的流程 上篇文章中提到了查询优化器解析语句的过程,当将计划缓存考虑在内时,首先需要查看计划缓存中是否已经有语句的缓存,如果没有,才会执行编译过程,如果存在则直接利用编译好的执行计划.因
-
浅析SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询优化(Optimization,有时候也被称为简化).执行(Execution).除去执行步骤外,前三个步骤之后就生成了执行计划,也就是SQL Server按照该计划获取物理数据方式,最后执行步骤按照执行计划执行查询从而获得结果.但查询优化器不是本篇的重点,本篇文章主要讲述查询优化器在生成执行计划之
-
基于SQL Server OS的任务调度机制详解
简介 SQL Server OS是在Windows之上,用于服务SQL Server的一个用户级别的操作系统层次.它将操作系统部分的功能从整个SQL Server引擎中抽象出来,单独形成一层,以便为存储引擎提供服务.SQL Server OS主要提供了任务调度.内存分配.死锁检测.资源检测.锁管理.Buffer Pool管理等多种功能.本篇文章主要是谈一谈SQL OS中所提供的任务调度机制. 抢占式(Preemptive)调度与非抢占式(non-Preemptive)调度 数据库层面的任务调度的
-
详解SQL Server中的事务与锁问题
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章试图采用图文的方式来与大家一起探讨. "浅谈SQL Server 事务与锁"这个专题共分两篇,上篇主讲事务及事务一致性问题,并简略的提及一下锁的种类和锁的控制级别. 下篇主讲SQL Server中的锁机制,锁控制级别和死锁的若干问题. 二 事务 1 何为事务 预览众多书籍,对于事务的定义,不同文献不同作者对其虽有细微差别却大致统一,我们将其抽象概括为: 事务:指封装且执行单个或多个操作的