Vue源码解析之Template转化为AST的实现方法
什么是AST
在Vue的mount过程中,template会被编译成AST语法树,AST是指抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式。
Virtual Dom
Vue的一个厉害之处就是利用Virtual DOM模拟DOM对象树来优化DOM操作的一种技术或思路。
Vue源码中虚拟DOM构建经历 template编译成AST语法树 -> 再转换为render函数 最终返回一个VNode(VNode就是Vue的虚拟DOM节点)
本文通过对源码中AST转化部分进行简单提取,因为源码中转化过程还需要进行各种兼容判断,非常复杂,所以笔者对主要功能代码进行提取,用了300-400行代码完成对template转化为AST这个功能。下面用具体代码进行分析。
function parse(template) {
var currentParent; //当前父节点
var root; //最终返回出去的AST树根节点
var stack = [];
parseHTML(template, {
start: function start(tag, attrs, unary) {
......
},
end: function end() {
......
},
chars: function chars(text) {
......
}
})
return root
}
第一步就是调用parse这个方法,把template传进来,这里假设template为 <div id="app"><span>{{message}}</span></div>
然后声明3个变量
currentParent -> 存放当前父元素,root -> 最终返回出去的AST树根节点,stack -> 一个栈用来辅助树的建立
接着调用parseHTML函数进行转化,传入template和options(包含3个方法 start,end,chars 等下用到这3个函数再进行解释)接下来先看parseHTML这个方法
function parseHTML(html, options) {
var stack = []; //这里和上面的parse函数一样用到stack这个数组 不过这里的stack只是为了简单存放标签名 为了和结束标签进行匹配的作用
var isUnaryTag$$1 = isUnaryTag; //判断是否为自闭合标签
var index = 0;
var last;
while (html) {
// 第一次进入while循环时,由于字符串以<开头,所以进入startTag条件,并进行AST转换,最后将对象弹入stack数组中
last = html;
var textEnd = html.indexOf('<');
if (textEnd === 0) { // 此时字符串是不是以<开头
// End tag:
var endTagMatch = html.match(endTag);
if (endTagMatch) {
var curIndex = index;
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1], curIndex, index);
continue
}
// Start tag: // 匹配起始标签
var startTagMatch = parseStartTag(); //处理后得到match
if (startTagMatch) {
handleStartTag(startTagMatch);
continue
}
}
// 初始化为undefined 这样安全且字符数少一点
var text = (void 0), rest = (void 0), next = (void 0);
if (textEnd >= 0) { // 截取<字符索引 => </div> 这里截取到闭合的<
rest = html.slice(textEnd); //截取闭合标签
// 处理文本中的<字符
// 获取中间的字符串 => {{message}}
text = html.substring(0, textEnd); //截取到闭合标签前面部分
advance(textEnd); //切除闭合标签前面部分
}
// 当字符串没有<时
if (textEnd < 0) {
text = html;
html = '';
}
// // 处理文本
if (options.chars && text) {
options.chars(text);
}
}
}
函数进入while循环对html进行获取<标签索引 var textEnd = html.indexOf('<');如果textEnd === 0 说明当前是标签<xxx>或者</xxx> 再用正则匹配是否当前是结束标签</xxx>。var endTagMatch = html.match(endTag); 匹配不到那么就是开始标签,调用parseStartTag()函数解析。
function parseStartTag() { //返回匹配对象
var start = html.match(startTagOpen); // 正则匹配
if (start) {
var match = {
tagName: start[1], // 标签名(div)
attrs: [], // 属性
start: index // 游标索引(初始为0)
};
advance(start[0].length);
var end, attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length);
match.attrs.push(attr);
}
if (end) {
advance(end[0].length); // 标记结束位置
match.end = index; //这里的index 是在 parseHTML就定义 在advance里面相加
return match // 返回匹配对象 起始位置 结束位置 tagName attrs
}
}
}
该函数主要是为了构建一个match对象,对象里面包含tagName(标签名),attrs(标签的属性),start(<左开始标签在template中的位置),end(>右开始标签在template中的位置) 如template = <div id="app"><div><span>{{message}}</span></div></div> 程序第一次进入该函数 匹配的是div标签 所以tagName就是div
start:0 end:14 如图:
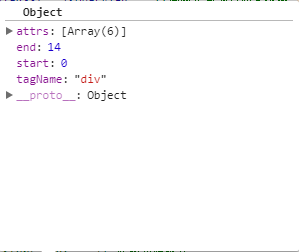
接着把match返回出去 作为调用handleStartTag的参数
var startTagMatch = parseStartTag(); //处理后得到match
if (startTagMatch) {
handleStartTag(startTagMatch);
continue
}
接下来看handleStartTag这个函数:
function handleStartTag(match) {
var tagName = match.tagName;
var unary = isUnaryTag$$1(tagName) //判断是否为闭合标签
var l = match.attrs.length;
var attrs = new Array(l);
for (var i = 0; i < l; i++) {
var args = match.attrs[i];
var value = args[3] || args[4] || args[5] || '';
attrs[i] = {
name: args[1],
value: value
};
}
if (!unary) {
stack.push({tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs});
lastTag = tagName;
}
if (options.start) {
options.start(tagName, attrs, unary, match.start, match.end);
}
}
函数中分为3部分 第一部分是for循环是对attrs进行转化,我们从上一步的parseStartTag()得到的match对象中的attrs属性如图
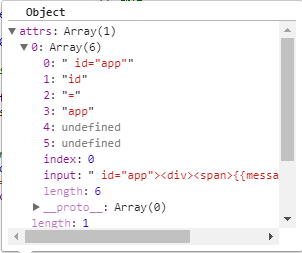
当时attrs是上面图这样子滴 我们通过这个循环把它转化为只带name 和 value这2个属性的对象 如图:
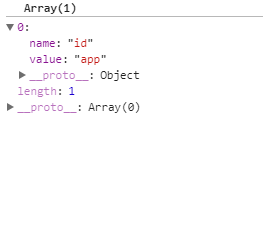
接着判断如果不是自闭合标签,把标签名和属性推入栈中(注意 这里的stack这个变量在parseHTML中定义,作用是为了存放标签名 为了和结束标签进行匹配的作用。)接着调用最后一步 options.start 这里的options就是我们在parse函数中 调用parseHTML是传进来第二个参数的那个对象(包含start end chars 3个方法函数) 这里开始看options.start这个函数的作用:
start: function start(tag, attrs, unary) {
var element = {
type: 1,
tag: tag,
attrsList: attrs,
attrsMap: makeAttrsMap(attrs),
parent: currentParent,
children: []
};
processAttrs(element);
if (!root) {
root = element;
}
if(currentParent){
currentParent.children.push(element);
element.parent = currentParent;
}
if (!unary) {
currentParent = element;
stack.push(element);
}
}
这个函数中 生成element对象 再连接元素的parent 和 children节点 最终push到栈中
此时栈中第一个元素生成 如图:
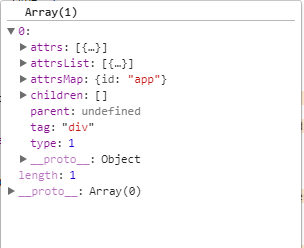
完成了while循环的第一次执行,进入第二次循环执行,这个时候html变成<span>{{message}}</span></div> 接着截取到<span> 处理过程和第一次一致 经过这次循环stack中元素如图:
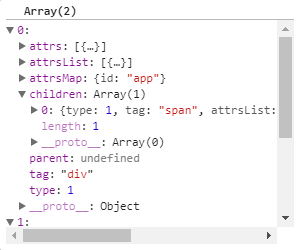
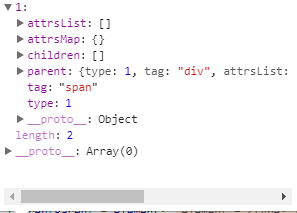
接着继续执行第三个循环 这个时候是处理文本节点了 {{message}}
// 初始化为undefined 这样安全且字符数少一点
var text = (void 0), rest = (void 0), next = (void 0);
if (textEnd >= 0) { // 截取<字符索引 => </div> 这里截取到闭合的<
rest = html.slice(textEnd); //截取闭合标签
// 处理文本中的<字符
// 获取中间的字符串 => {{message}}
text = html.substring(0, textEnd); //截取到闭合标签前面部分
advance(textEnd); //切除闭合标签前面部分
}
// 当字符串没有<时
if (textEnd < 0) {
text = html;
html = '';
}
// 另外一个函数
if (options.chars && text) {
options.chars(text);
}
这里的作用就是把文本提取出来 调用options.chars这个函数 接下来看options.chars
chars: function chars(text) {
if (!currentParent) { //如果没有父元素 只是文本
return
}
var children = currentParent.children; //取出children
// text => {{message}}
if (text) {
var expression;
if (text !== ' ' && (expression = parseText(text))) {
// 将解析后的text存进children数组
children.push({
type: 2,
expression: expression,
text: text
});
} else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
children.push({
type: 3,
text: text
});
}
}
}
})
这里的主要功能是判断文本是{{xxx}}还是简单的文本xxx,如果是简单的文本 push进父元素的children里面,type设置为3,如果是字符模板{{xxx}},调用parseText转化。如这里的{{message}}转化为 _s(message)(加上_s是为了AST的下一步转为render函数,本文中暂时不会用到。) 再把转化后的内容push进children。
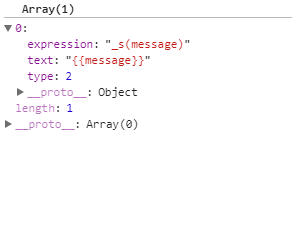
又走完一个循环了,这个时候html = </span></div> 剩下2个结束标签进行匹配了
var endTagMatch = html.match(endTag);
if (endTagMatch) {
var curIndex = index;
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1], curIndex, index);
continue
}
接下来看parseEndTag这个函数 传进来了标签名 开始索引和结束索引
function parseEndTag(tagName, start, end) {
var pos, lowerCasedTagName;
if (tagName) {
lowerCasedTagName = tagName.toLowerCase();
}
// Find the closest opened tag of the same type
if (tagName) { // 获取最近的匹配标签
for (pos = stack.length - 1; pos >= 0; pos--) {
// 提示没有匹配的标签
if (stack[pos].lowerCasedTag === lowerCasedTagName) {
break
}
}
} else {
// If no tag name is provided, clean shop
pos = 0;
}
if (pos >= 0) {
// Close all the open elements, up the stack
for (var i = stack.length - 1; i >= pos; i--) {
if (options.end) {
options.end(stack[i].tag, start, end);
}
}
// Remove the open elements from the stack
stack.length = pos;
lastTag = pos && stack[pos - 1].tag;
}
这里首先找到栈中对应的开始标签的索引pos,再从该索引开始到栈顶的所以元素调用options.end这个函数
end: function end() {
// pop stack
stack.length -= 1;
currentParent = stack[stack.length - 1];
},
把栈顶元素出栈,因为这个元素已经匹配到结束标签了,再把当前父元素更改。终于走完了,把html的内容循环完,最终return root 这个root就是我们所要得到的AST
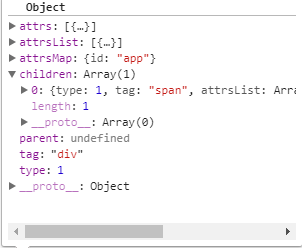
这只是Vue的冰山一角,文中有什么不对的地方请大家帮忙指正,本人最近也一直在学习Vue的源码,希望能够拿出来与大家一起分享经验,接下来会继续更新后续的源码,如果觉得有帮忙请给个Star哈
github地址为:https://github.com/zwStar/vue-ast欢迎各位star或issues
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Vue源码解析之Template转化为AST的实现方法
什么是AST 在Vue的mount过程中,template会被编译成AST语法树,AST是指抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式. Virtual Dom Vue的一个厉害之处就是利用Virtual DOM模拟DOM对象树来优化DOM操作的一种技术或思路. Vue源码中虚拟DOM构建经历 template编译成AST语法树 -> 再转换为render函数 最终返回一个VNode(VNod
-
vue 源码解析之虚拟Dom-render
vue 源码解析 --虚拟Dom-render instance/index.js function Vue (options) { if (process.env.NODE_ENV !== 'production' && !(this instanceof Vue) ) { warn('Vue is a constructor and should be called with the `new` keyword') } this._init(options) } renderMixin
-
从vue源码解析Vue.set()和this.$set()
前言 最近死磕了一段时间vue源码,想想觉得还是要输出点东西,我们先来从Vue提供的Vue.set()和this.$set()这两个api看看它内部是怎么实现的. Vue.set()和this.$set()应用的场景 平时做项目的时候难免不会对 数组或者对象 进行这样的骚操作操作,结果发现,咦~~,他喵的,怎么页面没有重新渲染. const vueInstance = new Vue({ data: { arr: [1, 2], obj1: { a: 3 } } }); vueInstance.
-
Vue源码解析之数组变异的实现
力有不逮的对象 众所周知,在 Vue 中,直接修改对象属性的值无法触发响应式.当你直接修改了对象属性的值,你会发现,只有数据改了,但是页面内容并没有改变. 这是什么原因? 原因在于: Vue 的响应式系统是基于Object.defineProperty这个方法的,该方法可以监听对象中某个元素的获取或修改,经过了该方法处理的数据,我们称其为响应式数据.但是,该方法有一个很大的缺点,新增属性或者删除属性不会触发监听,举个栗子: var vm = new Vue({ data () { return
-
vue源码解析之事件机制原理
上一章没什么经验.直接写了组件机制.感觉涉及到的东西非常的多,不是很方便讲.今天看了下vue的关于事件的机制.有一些些体会.写出来.大家一起纠正,分享.源码都是基于最新的Vue.js v2.3.0.下面我们来看看vue中的事件机制: 老样子还是先上一段贯穿全局的代码,常见的事件机制demo都会包含在这段代码中: <div id="app"> <div id="test1" @click="click1">click1<
-
Vue源码解析之数据响应系统的使用
接下来重点来看Vue的数据响应系统.我看很多文章在讲数据响应的时候先用一个简单的例子介绍了数据双向绑定的思路,然后再看源码.这里也借鉴了这种方式,感觉这样的确更有利于理解. 数据双向绑定的思路 1. 对象 先来看元素是对象的情况.假设我们有一个对象和一个监测方法: const data = { a: 1 }; /** * exp[String, Function]: 被观测的字段 * fn[Function]: 被观测对象改变后执行的方法 */ function watch (exp, fn)
-
java源码解析之String类的compareTo(String otherString)方法
一. 前言 最近我发现了一个事情,那就是在面试笔试中,好多公司都喜欢在String字符串上出问题,涉及到方方面面的知识,包括其中的一些常用方法. String 类代表字符串.Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现. 字符串是常量:它们的值在创建之后不能更改.字符串缓冲区支持可变的字符串.因为 String 对象是不可变的,所以可以共享. 近日研究了一下String类的一些方法, 通过查看源码, 对一些常用的方法也有了更透彻的认识, 也让我更加理解了设
-

微信跳一跳python辅助软件思路及图像识别源码解析
本文将梳理github上最火的wechat_jump_game的实现思路,并解析其图像处理部分源码 首先废话少说先看效果 核心思想 获取棋子到下一个方块的中心点的距离 计算触摸屏幕的时间 点击屏幕 重要方法 计算棋子到下一个方块中心点的距离 使用 adb shell screencap -p 命令获取手机当前屏幕画面 再通过图像上的信息找出棋子的坐标和下一个方块中心点的坐标 然后通过两点间距离公式计算出距离 计算触摸屏幕的时间 T=A * S 其中S为上步算出的像素距离,T为按压时间(ms),A
-
Tomcat的类加载机制流程及源码解析
目录 前言 1.Tomcat 的类加载器结构图: 2.Tomcat 的类加载流程说明: 3.源码解析: 4.为什么tomcat要实现自己的类加载机制: 前言 在前面 Java虚拟机:对象创建过程与类加载机制.双亲委派模型 文章中,我们介绍了 JVM 的类加载机制以及双亲委派模型,双亲委派模型的类加载过程主要分为以下几个步骤: (1)初始化 ClassLoader 时需要指定自己的 parent 是谁 (2)先检查类是否已经被加载过,如果类已经被加载了,直接返回 (3)若没有加载则调用父加载器 p
-
深入解析Vue源码实例挂载与编译流程实现思路详解
在正文开始之前,先了解vue基于源码构建的两个版本,一个是 runtime only ,另一个是 runtime加compiler 的版本,两个版本的主要区别在于后者的源码包括了一个编译器. 什么是编译器,百度百科上面的解释是 简单讲,编译器就是将"一种语言(通常为高级语言)"翻译为"另一种语言(通常为低级语言)"的程序.一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) →