Python分析学校四六级过关情况
这段时间看了数据分析方面的内容,对Python中的numpy和pandas有了最基础的了解。我知道如果我不用这些技能做些什么的话,很快我就会忘记。想起之前群里发过一个学校的四六级成绩表,正好可以用来熟悉一下pandas中的一些用法。
1.数据介绍。
成绩表中包含的字段十分详细,里面有年级、性别、姓名、分数等等的一系列内容,我只想简单的分析一下我们学校的四六级过关率而已,所以去除了一些不必要的字段。留下的有如下几个字段:
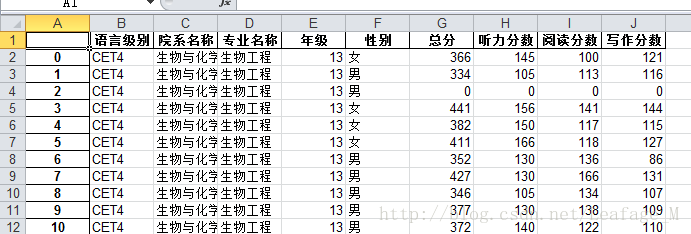
第一列是自增的序号,没有什么实际意义。
第二列就是代表着该学生参加的是四级还是六级。
第三列是我们学校的院系名称。
第四列是学校院系的各个专业。
第五列是年级,13代表着2013年入学。
第六列是性别。
后面的三列分别是总分、听力、阅读、写作等。
其中总分为0的都是缺考的。一共有接近9000条数据(没有报名的不在其中)。
2.预期结果。
我想利用这些数据最终通过图标的形式展示出以下几点:
1.各个学院的四六级平均分。
2.各个学院的四六级过关人数。
3.各个学院的各个年级过关人数。
4.各个年级的过关人数。
5.男生女生分别过关人数。
最终结果:
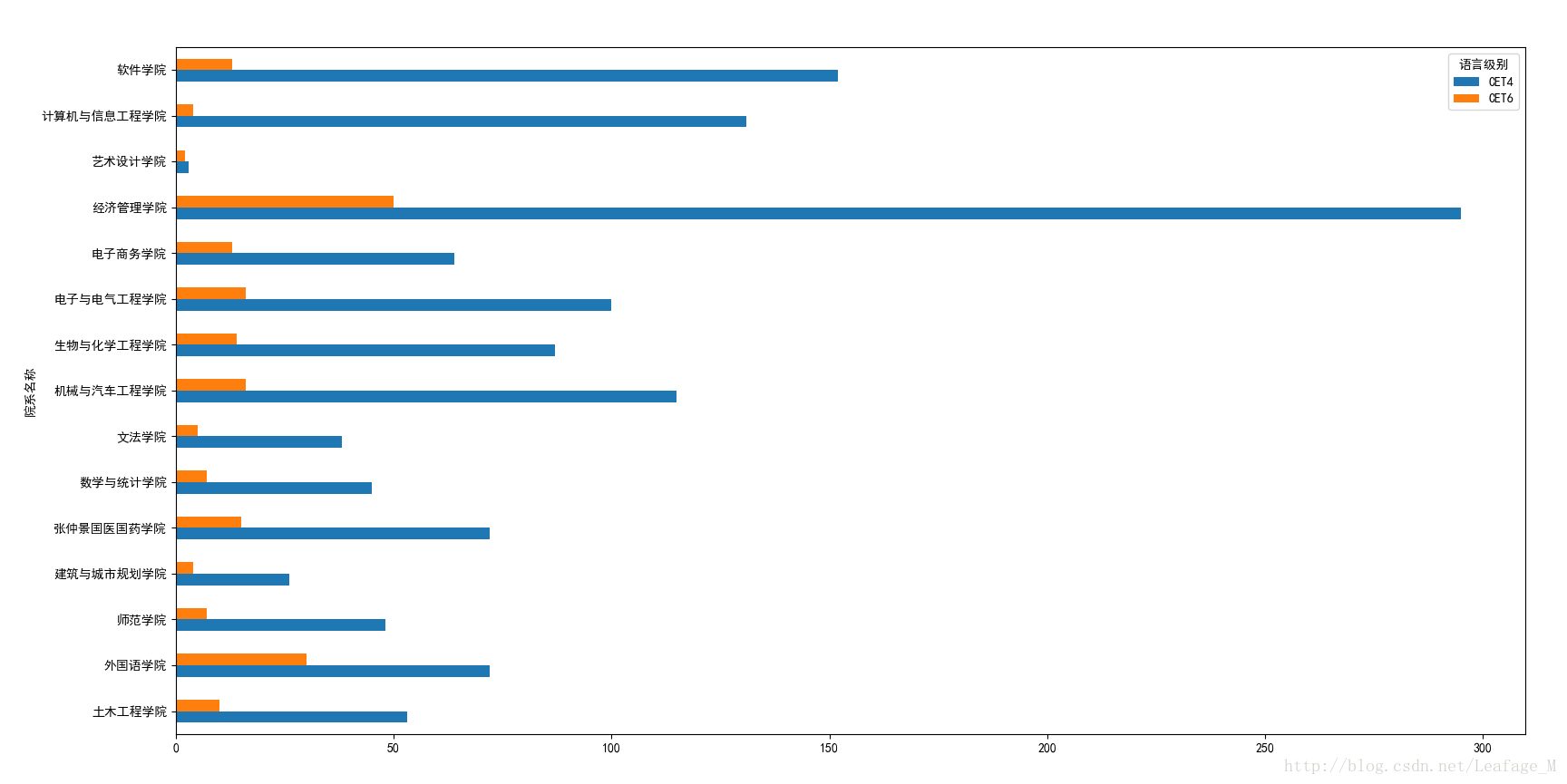
各个学院的四六级过关人数:
3.实现过程。
(1)导入依赖包。
程序分别使用了pandas进行分组转换,和matplotlib提供的绘图功能。
import pandas as pd import matplotlib.pylab as plt
(2)加载数据。
想要分析数据自然要得到数据了,我将整理的数据存放在sj.xls中,是一个Excel类型的数据。
这一步使用pandas的read_excel即可,生成一个DataFrame对象。
#加载全部数据 sj = pd.read_excel(r'F:\DataAnalysis\sj.xls')
加载完之后输出一下看看内容:
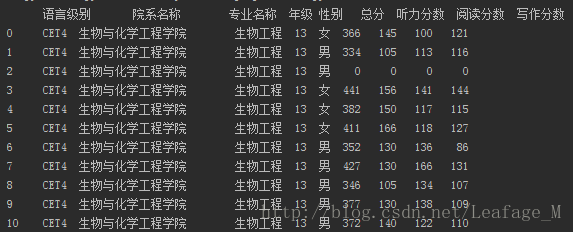
除了排版没有对齐之外其他都一样。
(3)统计各个学院平均分。
在这里就可以完成我们预期的第一个结果:
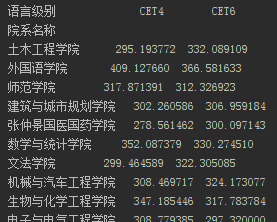
各个学院的四六级平均分:
想要各个学院的情况当然是要根据学院来进行分组了,同时也需要分出“CET4”和“CET6”两组。使用groupby即可,这样会生成一个SeriesGroupBy对象,然后再调用mean函数(默认是轴0计算,也就是我们想要的结果)即可统计出平均分情况。
#按照各个学院进行分组 xymean = sj['总分'].groupby([sj['院系名称'],sj['语言级别']]) #计算各个学院的平均分数 xymean = xymean.mean()
这个时候将其输出的话会得到如下结果:
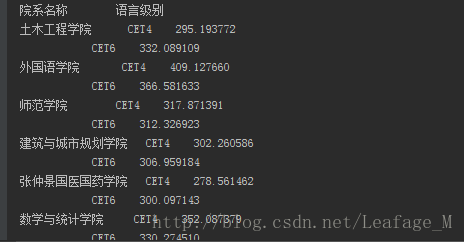
由于院系名称和语言级别是层次化索引的缘故,看起来并不是十分的友好,因此使用unstack将语言级别转从行转换为列。
xymean = xymean.unstack(level='语言级别')
再次输出的话结果就比较清晰了
使用pandas的绘图功能进行绘图:
#使用横向柱状图显示 xymean.plot(kind='barh') #在PyCharm中需要使用,在Ipython环境中如果以--pylab形式打开就不需要 plt.show()
运行一下看看结果:
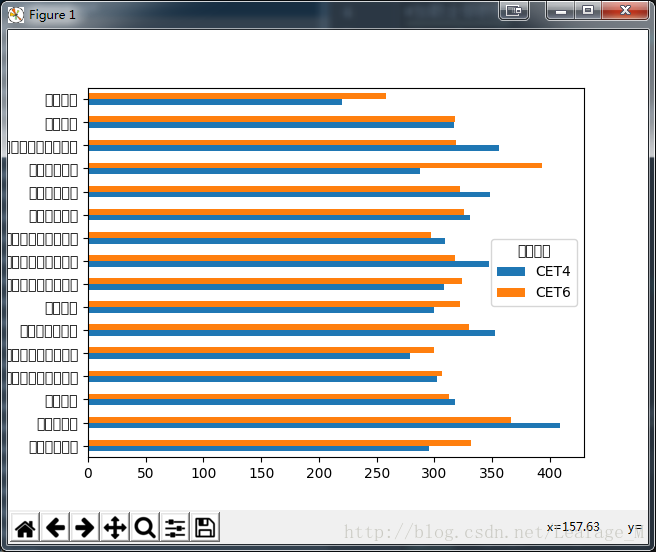
可以看到这时候数据的结果都能够显示出来了,但是中文部分出现了问题,不过不要紧,科学上网一查就解决了:https://github.com/mwaskom/seaborn/issues/1009
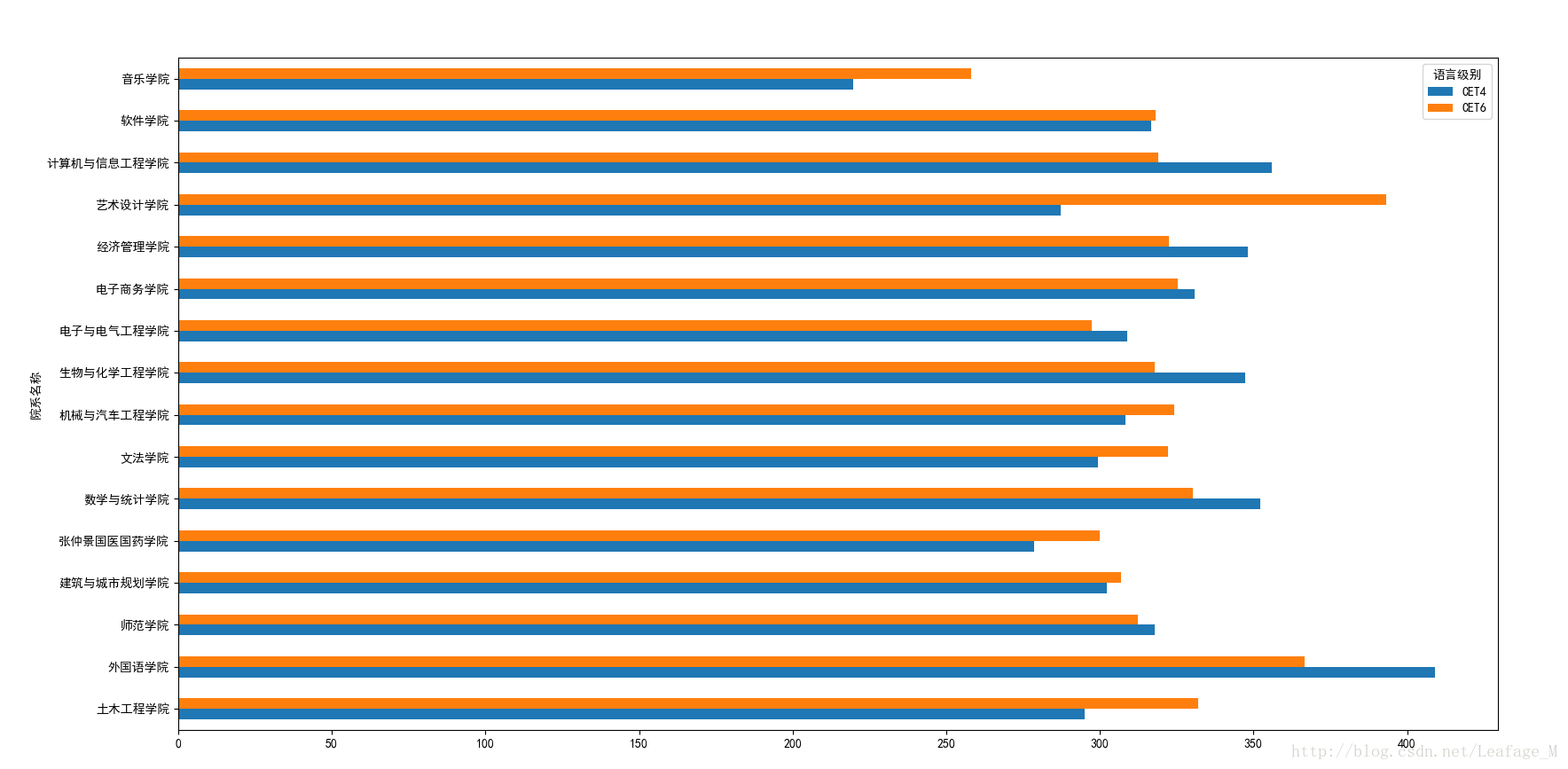
添加一下代码即可:
import matplotlib as mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['font.serif'] = ['SimHei']
再次运行就OK了。
接下来要分析过关的情况了。
(4)筛选数据。
既然已经有了所有的数据内容了,下一步就是筛选出所有过关的人数了。
#过滤出过关人数 sjpass = sj[sj['总分'] >= 425]
这时候sjpass存放的就是所有的过关人数了。
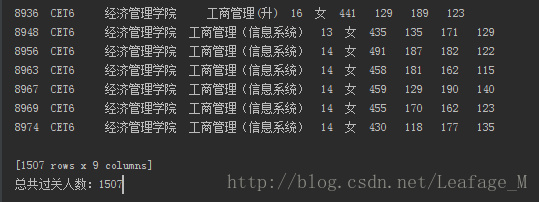
在输出结果的最下面就可以看到一共有1507行数据,当然也可以使用len()或者shape[0]查看共有多少行。
(5)各个学院的四六级过关人数。
已经有了全部过关人的数据了,接下来根据预期结果进行分组即可。同样的根据“院系名称”和“语言级别”对总分进行分组,然后使用count函数进行求和最后再用unstack进行调整绘图展示。
#按照各个学院进行分组 xypass = sjpass['总分'].groupby([sjpass['院系名称'],sjpass['语言级别']]) #计算各个学院的过关总人数 xypass = xypass.count() #将语言级别作为columns xypass = xypass.unstack(level='语言级别') #进行绘图 xypass.plot(kind='barh') plt.show()
绘图结果:
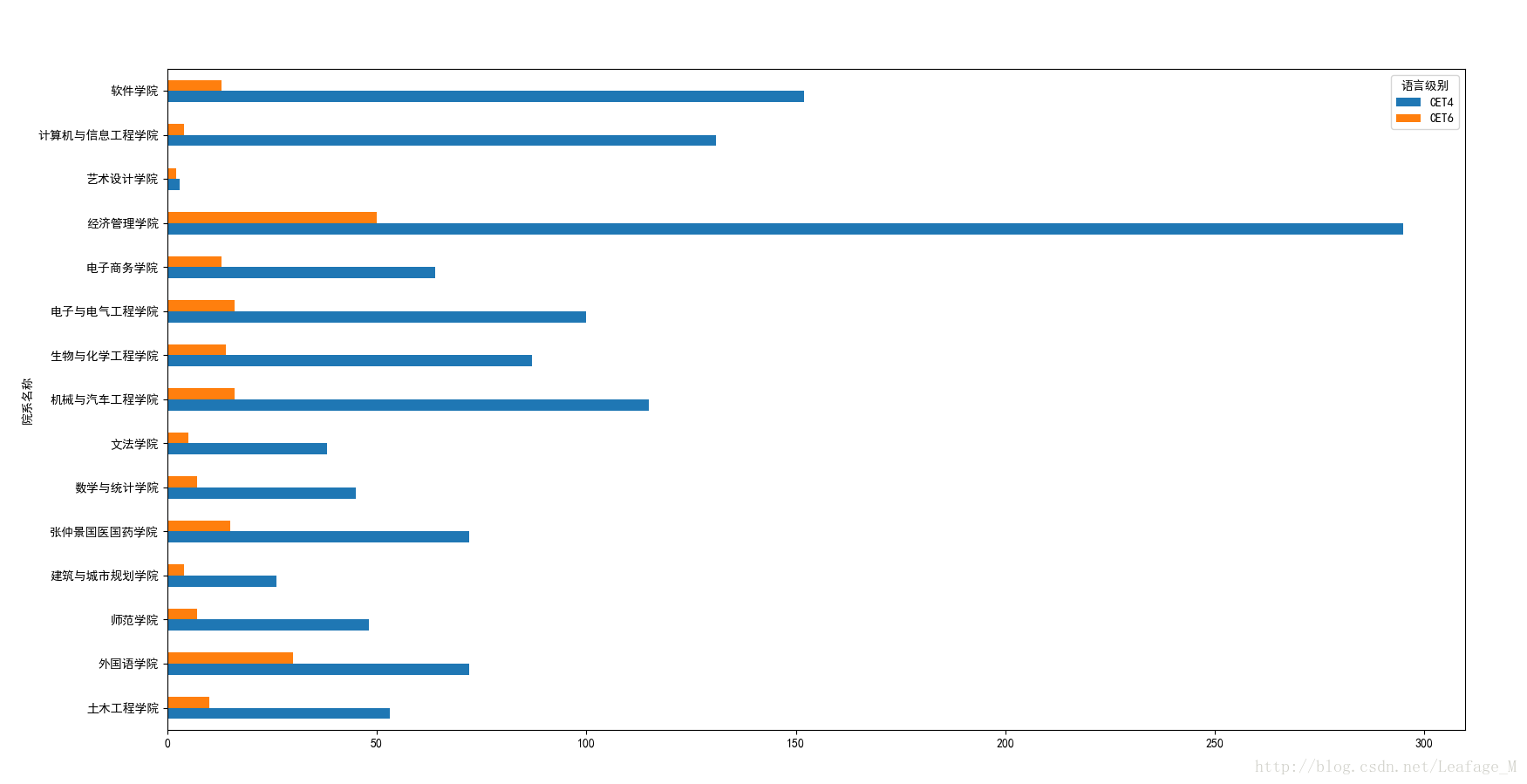
(6)各个学院的各个年级过关人数。。
这次分组的时候加上年级即可,并且为了绘图比较好看一点,这次可以将“年纪”转换为列,并且像12年这种的有些学员已经没有人参加了,所以需要将缺失值用0填充:
#按照各个学院和年级进行分组 xypass = sjpass['总分'].groupby([sjpass['院系名称'],sjpass['语言级别'],sjpass['年级']]) #计算各个学院的过关总人数 xypass = xypass.count() #将语言级别作为columns,并且将缺失值用0进行填充 xypass = xypass.unstack(level='年级').fillna(0) xypass.plot(kind='barh') plt.show()
绘图结果:
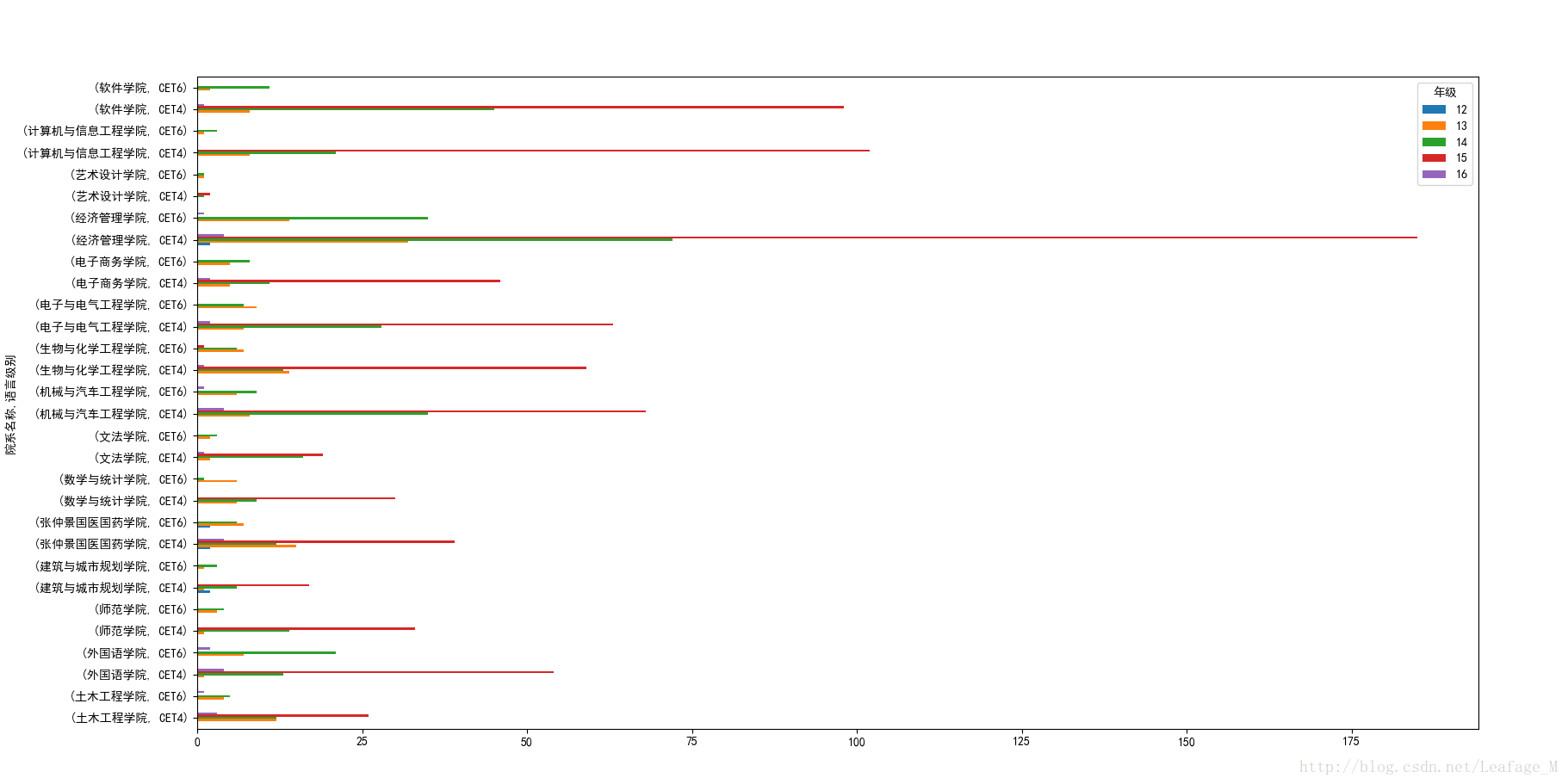
(7)各个年级的过关人数。
使用groupby对年级进行分组即可:
#-----------------各个年级过关人数------------------ njpass = sjpass['总分'].groupby([sjpass['年级'],sjpass['语言级别']]).count().unstack(level='语言级别') njpass.plot(kind='barh') plt.show()
绘图结果:
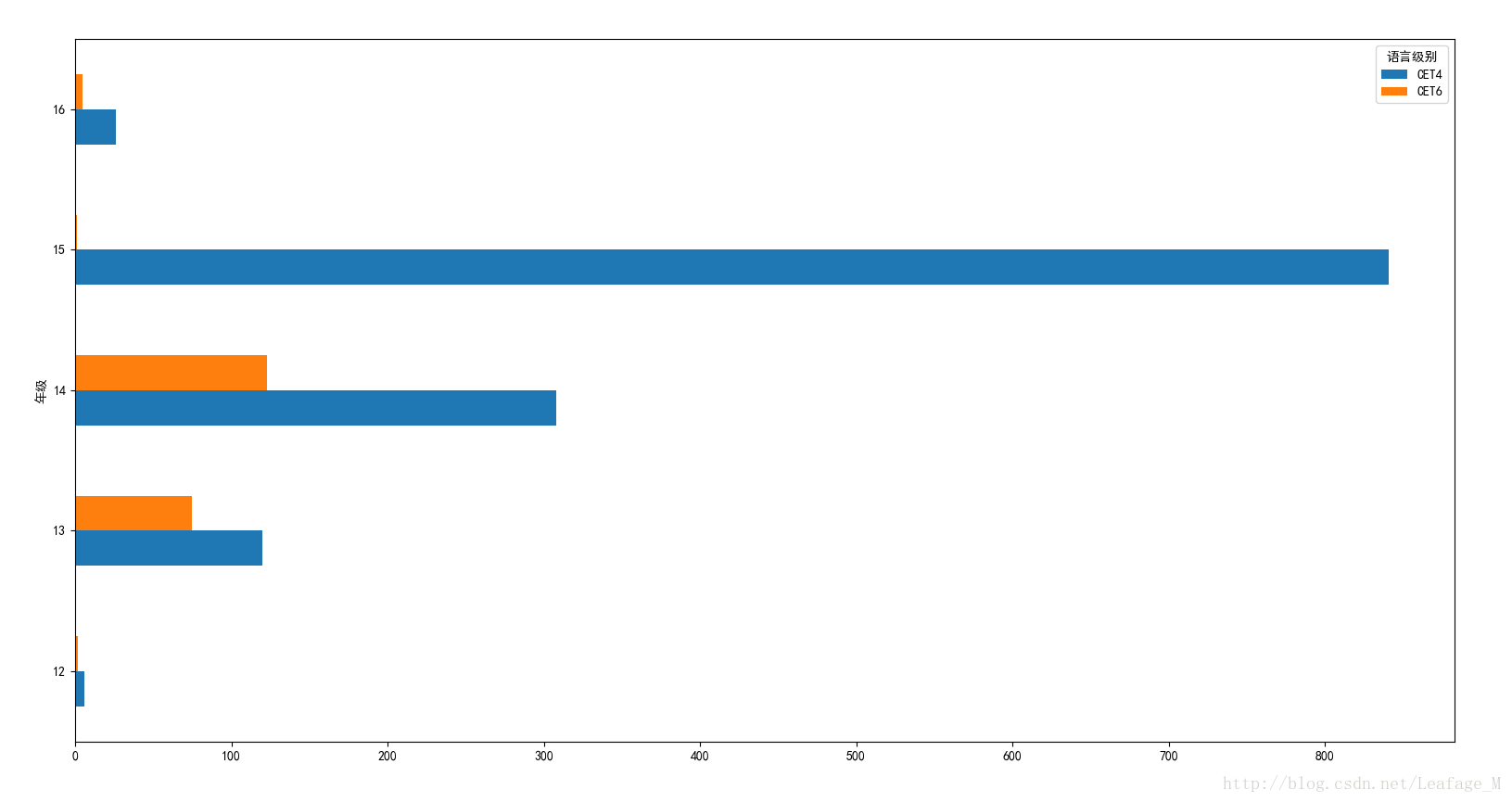
(8)男生女生分别过关人数。
将性别和语言级别进行分组:
#---------------男生女生过关情况---------------------- nvpass = sjpass['总分'].groupby([sjpass['性别'],sjpass['语言级别']]).count().unstack(level='语言级别') nvpass.plot(kind='bar') plt.show()
绘图结果:

4.结果分析。
从绘图的结果上来看的话,各个学院之间音乐学院的平均分比较低,艺术设计和外国语学院的平均分都比较高,但是过关人数却没有那么的多,尤其是艺术设计的人数比较少,主要也是因为该学院的总人数比较少。
四级的过关人数明显比六级的人数多的多,而且因为15级是大二年级,在我们学校大二才可以参加四六级考试,所以过关的人数里面15级占有比较大的比分。
而且不得不承认,女生的过关率要比男生高的不止一点。
源码以及数据:https://github.com/jiajia0/DataAnalysis
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

利用python爬取软考试题之ip自动代理
前言 最近有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.cn网上的软考试题. 首先讲述一下我爬取软考试题的故(keng)事(shi).现在我已经能自动抓取某一个模块的所有题目了,如下图: 目前可以将信息系统监理师的30条试题记录全部抓取下来,结果如下图所示: 抓取下来的内容图片: 虽然可以将部分信息抓取下来,但是代码的质量并不高,以抓取信息系统监理师为例,因为目标明确,各项参数清晰,为了追求能在短时间内抓取到试卷信息,所以并没有做异常处理,昨天晚上填了很
-
Python分析学校四六级过关情况
这段时间看了数据分析方面的内容,对Python中的numpy和pandas有了最基础的了解.我知道如果我不用这些技能做些什么的话,很快我就会忘记.想起之前群里发过一个学校的四六级成绩表,正好可以用来熟悉一下pandas中的一些用法. 1.数据介绍. 成绩表中包含的字段十分详细,里面有年级.性别.姓名.分数等等的一系列内容,我只想简单的分析一下我们学校的四六级过关率而已,所以去除了一些不必要的字段.留下的有如下几个字段: 第一列是自增的序号,没有什么实际意义. 第二列就是代表着该学生参加的是四级还
-
python分析作业提交情况
这次做一个比较贴近我实际的东西:python分析作业提交情况. 要求: 将服务器中交作业的学生(根据文件的名字进行提取)和统计成绩的表格中的学生的信息进行比对,输出所有没有交作业的同学的信息(学号和姓名),并输出所交的作业中命名格式有问题的文件名的信息(如1627406012_E03....). 提示: 提示: 1.根据服务器文件可以拿到所有交了作业的同学的信息. 2.根据表格可以拿到所有上课学生的信息 3.对1和2中的信息进行比对,找出想要得到的信息 注意:提取服务器中学生交的作业的信息的时候
-
Python 分析Nginx访问日志并保存到MySQL数据库实例
使用Python 分析Nginx access 日志,根据Nginx日志格式进行分割并存入MySQL数据库.一.Nginx access日志格式如下: 复制代码 代码如下: $remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_f
-
Python实现学校管理系统
本文实例为大家分享了Python实现学校管理系统的具体代码,供大家参考,具体内容如下 一.功能分析 此学校管理系统应该可以实现学校的师资力量的调配,学生的入学.学习以及修学或者退学的情况 二.程序解读 1.下面的程序实现了学校管理系统的基本功能,包括: 1)学校的招生 2)讲师的招聘 3)课程的增加 4)等等 2.未实现的功能也有很多,比如: 1)学生类中有一个方法是缴费,也有一个方法是注册,这两个方法应该关联起来,缴费成功后,才可以进行注册 2)每个老师应该可以通过各种方式来查看自己学生的信息
-
Python机器学习入门(四)选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 总结 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习
-
利用Python分析一下最近的股票市场
目录 一.数据获取 二.合并数据 三.绘制股票每日百分比变化 四.箱线图 五.计算月化夏普比率 六.结论 一.数据获取 数据获取范围为2022年一月一日到2022年2月25日,获取的数据为俄罗斯黄金,白银,石油,银行,天然气: # 导入模块 import numpy as np import pandas as pd import yfinance as yf # GC=F黄金,SI=F白银,ROSN.ME俄罗斯石油,SBER.ME俄罗斯银行,天然气 tickerSymbols = ['GC=F
-
Python机器学习入门(四)之Python选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习算法时
-
Python利用memory_profiler查看内存占用情况
目录 简介 安装 使用方法 1.通过装饰器运行 2.通过命令行运行 补充 简介 memory_profiler是第三方模块,用于监视进程的内存消耗以及python程序内存消耗的逐行分析.它是一个纯python模块,依赖于psutil模块. 安装 pip install memory_profiler 使用方法 1.通过装饰器运行 @profile def func1(): 2.通过命令行运行 python -m memory_profiler test_code.py 案例源码: # -*- c
-
python分析网页上所有超链接的方法
本文实例讲述了python分析网页上所有超链接的方法.分享给大家供大家参考.具体实现方法如下: import urllib, htmllib, formatter website = urllib.urlopen("http://yourweb.com") data = website.read() website.close() format = formatter.AbstractFormatter(formatter.NullWriter()) ptext = htmllib.H
-
使用python分析统计自己微信朋友的信息
首先,你得安装itchat,命令为pip install itchat,其余的较为简单,我不再说明,直接看注释吧. 以下的代码我在Win7+Python3.7里面调试通过 __author__ = 'Yue Qingxuan' # -*- coding: utf-8 -*- import itchat # hotReload=True可不用每次都去扫描二维码,只需要手机上确认下 itchat.auto_login(hotReload=True) # 获取好友列表 friends = itchat