Python人工智能之路 之PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库
关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的
首先要先 pip 一个 PyAudio
pip install pyaudio
一.PyAudio 实现麦克风录音
然后建立一个py文件,复制如下代码
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
WAVE_OUTPUT_FILENAME = "Oldboy.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录音,请说话......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束,请闭嘴!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
尝试一下,在目录中出现了一个 Oldboy.wav 文件 , 听一听,还是很清晰的嘛
接下来,我们将这段录音代码,写在一个函数里面,如果要录音的话就调用
建立一个文件 pyrec.py 并将录音代码和函数写在内
# pyrec.py 文件内容
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
def rec(file_name):
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录音,请说话......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束,请闭嘴!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
rec 函数就是我们调用的录音函数,并且给他一个文件名,他就会自动将声音写入到文件中了
二.实现音频格式自动转换 并 调用语音识别
录音的问题解决了,赶快和百度语音识别接在一起使用一下:
不管你的录音有多么多么清晰,你发现百度给你返回的永远是:
{'err_msg': 'speech quality error.', 'err_no': 3301, 'sn': '6397933501529645284'} # 音质不清晰
其实不是没听清,而是百度支持的音频格式PCM搞的鬼
所以,我们要将录制的wav音频文件转换为pcm文件
写一个文件 wav2pcm.py 这个文件里面的函数是专门为我们转换wav文件的
使用 os 模块中的 os.system()方法 这个方法是执行系统命令用的, 在windows系统中的命令就是 cmd 里面写的东西,dir , cd 这类的命令
# wav2pcm.py 文件内容
import os
def wav_to_pcm(wav_file):
# 假设 wav_file = "音频文件.wav"
# wav_file.split(".") 得到["音频文件","wav"] 拿出第一个结果"音频文件" 与 ".pcm" 拼接 等到结果 "音频文件.pcm"
pcm_file = "%s.pcm" %(wav_file.split(".")[0])
# 就是此前我们在cmd窗口中输入命令,这里面就是在让Python帮我们在cmd中执行命令
os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file))
return pcm_file
这样我们就有了把wav转为pcm的函数了 , 再重新构建一次咱们的代码

这次的返回结果还挺让人满意的嘛
{'corpus_no': '6569869134617218414', 'err_msg': 'success.', 'err_no': 0, 'result': ['老男孩教育'], 'sn': '8116162981529666859'}
拿到语音识别的字符串了,接下来用这段字符串 语音合成, 学习咱们说出来的话
三.语音合成 与 FFmpeg 播放mp3 文件
拿到字符串了,直接调用synthesis方法去合成吧

这段代码衔接上一段代码,成功获得了 synth.mp3 音频文件,并且确定了实在学习我们说的话
接下来就是让我们的程序自动将 synth.mp3 音频文件播放了 其实PyAudio 有播放的功能,但是操作有点复杂
所以我们还是选择用简单的方式解决复杂的问题,就是这么简单粗暴,是否还记得FFmpeg 呢?
FFmpeg 这个系统工具中,有一个 ffplay 的工具用来打开并播放音频文件的,使用方法大概是: ffplay 音频文件.mp3
建立一个playmp3.py文件, 写一个 play_mp3 的函数用来播放已经合成的语音
# playmp3.py 文件内容
import os
def play_mp3(file_name):
os.system("ffplay %s"%(file_name))
回到主文件,调用playmp3.py文件中的 play_mp3 函数

执行代码,当你看到 : 开始录音,请说话......
请大声的说出: 学IT 找老男孩教育
然后你就会听到,一个娇滴滴声音重复你说的话
四.简单问答
首先我们要把代码重新梳理一下:
把语音合成 语音识别部分的代码独立成函数放到baidu_ai.py文件中
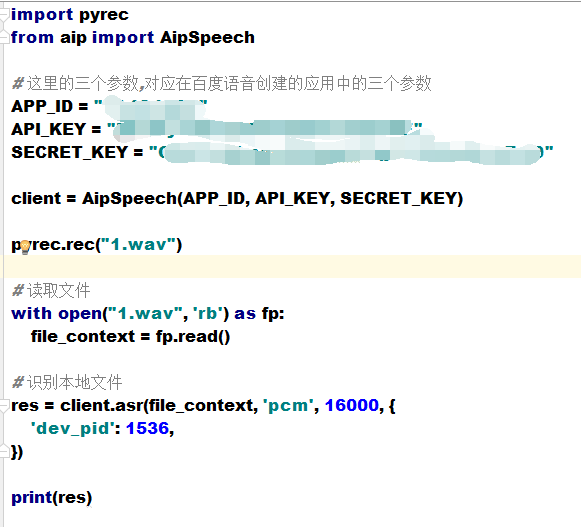
# baidu_ai.py 文件内容
from aip import AipSpeech
# 这里的三个参数,对应在百度语音创建的应用中的三个参数
APP_ID = "xxxxx"
API_KEY = "xxxxxxx"
SECRET_KEY = "xxxxxxxx"
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def audio_to_text(pcm_file):
# 读取文件 , 终于得到了PCM文件
with open(pcm_file, 'rb') as fp:
file_context = fp.read()
# 识别本地文件
res = client.asr(file_context, 'pcm', 16000, {
'dev_pid': 1536,
})
# 从字典里面获取"result"的value 列表中第1个元素,就是识别出来的字符串"老男孩教育"
res_str = res.get("result")[0]
return res_str
def text_to_audio(res_str):
synth_file = "synth.mp3"
synth_context = client.synthesis(res_str, "zh", 1, {
"vol": 5,
"spd": 4,
"pit": 9,
"per": 4
})
with open(synth_file, "wb") as f:
f.write(synth_context)
return synth_file
然后把我们的主文件进行一下修改
import pyrec # 录音函数文件
import wav2pcm # wav转换pcm 函数文件
import baidu_ai # 语音合成函数,语音识别函数 文件
import playmp3 # 播放mp3 函数 文件
pyrec.rec("1.wav") # 录音并生成wav文件,使用方式传入文件名
pcm_file = wav2pcm.wav_to_pcm("1.wav") # 将wav文件 转换成pcm文件 返回 pcm的文件名
res_str = baidu_ai.audio_to_text(pcm_file) # 将转换后的pcm音频文件识别成 文字 res_str
synth_file = baidu_ai.text_to_audio(res_str) # 将res_str 字符串 合成语音 返回文件名 synth_file
playmp3.play_mp3(synth_file) # 播放 synth_file
然后就是大展宏图的时候了,展开你们的想象力:
res_str 是字符串,如果字符串等于"你叫什么名字"的时候,我们就要给他一个回答:我的名字叫老男孩教育
新建一个FAQ.py的文件然后建立一个函数faq:
# FAQ.py 文件内容
def faq(Q):
if Q == "你叫什么名字": # 问题
return "我的名字是老男孩教育" # 答案
return "我不知道你在说什么" #问题没有答案时返
在主文件中导入这个函数,并将语音识别后的字符串传入函数中

现在来尝试一下:"你叫什么名字","你今年几岁了"
成功了,现在你可以对 FAQ.py 这个文件进行更多的问题匹配了
还是那句话,别玩儿坏了
思考题:
1.如何实现一直问答不用问一次停一次?
2.问题那么多,是不是要写这么多问题呢?
3.如果我问你是谁,是不是要重复也一次 我的名字叫老男孩教育 的答案呢?
总结
以上所述是小编给大家介绍的Python人工智能之路 之PyAudio 实现录音 自动化交互实现问答 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

AI人工智能 Python实现人机对话
在人工智能进展的如火如荼的今天,我们如果不尝试去接触新鲜事物,马上就要被世界淘汰啦~ 本文拟使用Python开发语言实现类似于WIndows平台的"小娜",或者是IOS下的"Siri".最终达到人机对话的效果. [实现功能] 这篇文章将要介绍的主要内容如下: 1.搭建人工智能--人机对话服务端平台 2.实现调用服务端平台进行人机对话交互 [实现思路] AIML AIML由Richard Wallace发明.他设计了一个名为 A.L.I.C.E. (Artificia
-
python实现播放音频和录音功能示例代码
音频预处理 这一讲主要介绍些音频基本处理方式,为接下来的语音识别打基础. 三种播放音频的方式 使用 python 播放音频有以下几种方式: os.system() os.system(file) 调用系统应用来打开文件,file 可为图片或者音频文件. 缺点:要打开具体的应用,不能在后台播放音频. pyaudio 安装:pip install pyaudio 官方提供了播放音频与录音的 api ,使用十分方便,只要把Filename更改为你的音频文件的文字,就可以播放音频了. ""&q
-
解读! Python在人工智能中的作用
人工智能是一种未来性的技术,目前正在致力于研究自己的一套工具.一系列的进展在过去的几年中发生了:无事故驾驶超过300000英里并在三个州合法行驶迎来了自动驾驶的一个里程碑:IBM Waston击败了Jeopardy两届冠军;统计学习技术从对消费者兴趣到以万亿记的图像的复杂数据集进行模式识别. 这些发展必然提高了科学家和巨匠们对人工智能的兴趣,这也使得开发者们了解创建人工智能应用的真实本质.开发这些需要注意的第一件事是: 哪一种编程语言适合人工智能? 你所熟练掌握的每一种编程语言都可以是人工智能的
-
python实现录音小程序
本文为大家分享了python实现录音小程序的具体代码,供大家参考,具体内容如下 学习目标:掌握python的pyaudio扩展包和Wave模块录制语音的方法 Wav音频:声道数,采样频率,量化位数 python Wav包是自带的,pyaudio需要下载 pip3 install pyaudio python读Wav文件: fp=wave.open('','rb') nf=fp.getnframes()#获取文件的采样点数量 print('sampwidth:',fp.getsampwidth()
-
Python+树莓派+YOLO打造一款人工智能照相机
不久之前,亚马逊刚刚推出了DeepLens.这是一款专门面向开发人员的全球首个支持深度学习的摄像机,它所使用的机器学习算法不仅可以检测物体活动和面部表情,而且还可以检测类似弹吉他等复杂的活动.虽然DeepLens还未正式上市,但智能摄像机的概念已经诞生了. 今天,我们将自己动手打造出一款基于深度学习的照相机,当小鸟出现在摄像头画面中时,它将能检测到小鸟并自动进行拍照.最终成品所拍摄的画面如下所示: 相机不傻,它可以很机智 我们不打算将一个深度学习模块整合到相机中,相反,我们准备将树莓派"挂钩&q
-
python、java等哪一门编程语言适合人工智能?
谷歌的AI击败了一位围棋大师,是一种衡量人工智能突然的快速发展的方式,也揭示了这些技术如何发展而来和将来可以如何发展. 人工智能是一种未来性的技术,目前正在致力于研究自己的一套工具.一系列的进展在过去的几年中发生了:无事故驾驶超过300000英里并在三个州合法行驶迎来了自动驾驶的一个里程碑:IBM Waston击败了Jeopardy两届冠军;统计学习技术从对消费者兴趣到以万亿记的图像的复杂数据集进行模式识别.这些发展必然提高了科学家和巨匠们对人工智能的兴趣,这也使得开发者们了解创建人工智能应用的
-
python 通过麦克风录音 生成wav文件的方法
如下所示: #!/usr/bin/env python # -*- coding: utf-8 -*- ######################################################################## # # Copyright (c) 2017 aibot.me, Inc. All Rights Reserved # ###############################################################
-
Python人工智能之路 之PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库 关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的 首先要先 pip 一个 PyAudio pip install pyaudio 一.PyAudio 实现麦克风录音 然后建立一个py文件,复制如下代码 import pyaudio import wave CHUNK = 1024 FORMAT = py
-
Python人工智能之路 jieba gensim 最好别分家之最简单的相似度实现
简单的问答已经实现了,那么问题也跟着出现了,我不能确定问题一定是"你叫什么名字",也有可能是"你是谁","你叫啥"之类的,这就引出了人工智能中的另一项技术: 自然语言处理(NLP) : 大概意思就是 让计算机明白一句话要表达的意思,NLP就相当于计算机在思考你说的话,让计算机知道"你是谁","你叫啥","你叫什么名字"是一个意思 这就要做 : 语义相似度 接下来我们用Python大法来实
-
Python使用PyAudio制作录音工具的实现代码
目录 应用平台 音频录制部分 音频播放部分 GUI窗口所需属性值代码部分 pynput监听键盘 总结 最近有在使用屏幕录制软件录制桌面,在用的过程中突发奇想,使用python能不能做屏幕录制工具,也锻炼下自己的动手能力.接下准备写使用python如何做屏幕录制工具的系列文章: 录制屏幕制作视频 录制音频 合成视频,音频 基于pyqt5制作可视化窗口 大概上述四个部分,希望自己能够尽快完善,上一篇文章利用opencv制作了屏幕录制部分,接下继续更新系列,使用python录制音频. 应用平台 win
-
python人工智能使用RepVgg实现图像分类示例详解
目录 摘要 安装包 安装timm 数据增强Cutout和Mixup EMA 项目结构 计算mean和std 生成数据集 摘要 RepVgg通过结构重参数化让VGG再次伟大. 所谓“VGG式”指的是: 没有任何分支结构.即通常所说的plain或feed-forward架构. 仅使用3x3卷积. 仅使用ReLU作为激活函数. RepVGG的更深版本达到了84.16%正确率!反超若干transformer! RepVgg是如何到的呢?简单地说就是: 首先, 训练一个多分支模型 然后,将多分支模型等价转
-
Python学习之路之pycharm的第一个项目搭建过程
简介: 上文中已经介绍如何安装Pycharm已经环境变量的配置.现在软件已经安装成功,现在就开始动手做第一个Python项目.第一个"Hello World"项目. 第一步:打开Pycharm软件 1.双击,桌面图标,运行软件,进入软件后,点击"Create NewProject" 2.在弹出的窗口中,在工程路径Location处选择存放路径以及为建立的新工程命个名,如:MyFristProject.这个文件名必须在工程路径下是不存在的文件夹. 第二步:添加解释器
-
Python学习之路安装pycharm的教程详解
简介:pycharm 是一款功能强大的 Python 编辑器,具有跨平台性.下载地址 第一步:下载pycharm 软件 下载时会有两个版本供选择.Professional版(专业版)和Community版(社区版).建议安装Community版本,因为免费使用. 第二步:安装pycharm软件 1.找到下载的 .exe文件,双击运行安装.建议修改安装位置,软件不要总是安装在默认C盘,如下,我选择E盘. 2.接下来 3.接下来 4.Install 然后就是静静的等待安装了.如果我们之前没有下载有P
-
Python人工智能之波士顿房价数据分析
目录 1.数据概览分析 1.1 数据概览 1.2 数据分析 2. 项目总体思路 2.1 数据读取 2.2 模型预处理 (1)数据离群点处理 (2)数据归一化处理 2.3. 特征工程 2.4. 模型选择 2.5. 模型评价 2.6. 模型调参 3. 项目总结 [人工智能项目]机器学习热门项目-波士顿房价 1.数据概览分析 1.1 数据概览 本次提供: train.csv,训练集: test.csv,测试集: submission.csv 真实房价文件: 训练集404行数据,14列,每行数据表示房屋
-
Python人工智能之sg2im文字转图像
[人工智能项目]sg2im文字转图像 本次主要对github上的sg2im源码进行执行训练,得到结果. 1.从github上下载源码 !git clone https://github.com/google/sg2im.git Cloning into 'sg2im'... remote: Enumerating objects: 85, done.[K remote: Total 85 (delta 0), reused 0 (delta 0), pack-reused 85[K Unpack
-
Python人工智能之混合高斯模型运动目标检测详解分析
[人工智能项目]混合高斯模型运动目标检测 本次工作主要对视频中运动中的人或物的边缘背景进行检测. 那么走起来瓷!!! 原视频 高斯算法提取工作 import cv2 import numpy as np # 高斯算法 class gaussian: def __init__(self): self.mean = np.zeros((1, 3)) self.covariance = 0 self.weight = 0; self.Next = None self.Previous = None c
-
python人工智能TensorFlow自定义层及模型保存
目录 一.自定义层和网络 1.自定义层 2.自定义网络 二.模型的保存和加载 1.保存参数 2.保存整个模型 一.自定义层和网络 1.自定义层 ①必须继承自layers.layer ②必须实现两个方法,__init__和call 这个层,实现的就是创建参数,以及一层的前向传播. 添加参数使用self.add_weight,直接调用即可,因为已经在母类中实现. 在call方法中,实现前向传播并返回结果即可. 2.自定义网络 ①必须继承自keras.Model ②必须实现两个方法,__init__和