python实现蒙特卡罗方法教程
蒙特卡罗方法是一种统计模拟方法,由冯·诺依曼和乌拉姆提出,在大量的随机数下,根据概率估计结果,随机数据越多,获得的结果越精确。下面我们将用python实现蒙特卡罗方法。
1.首先我们做一个简单的圆周率的近似计算,在这个过程中我们要用到随机数,因此需要先使用import numpy as np导入numpy库。
2.代码实现:
import numpy as np total = 8000000 count = 0 for i in range(total): x = np.random.rand() y = np.random.rand() dis = (x**2+y**2)**0.5 if dis <= 1: count = count+1 PI = 4*count/total print(PI)
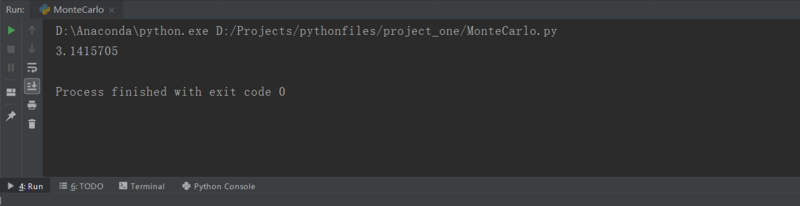
3.在上面的程序中我们用8000000个随机数进行投放,这样得到的结果会更精确一些,运行程序需要一定的时间,最终得到的结果如下
4.下面我们进行一项简单的应用,下图为我在画图工具中随便画的一个图,我们可以用蒙特卡罗方法来估算图中黑色部分的面积。

5.上面的图形是不规则的,我们只需知道在投放大量随机数的情况下,随机数在黑色部分出现的概率,再用总面积相乘即可估算黑色部分的面积。我们知道,黑色的rgb编码为(0,0,0),所以需要统计rgb编码为(0,0,0)时随机数的投放概率即可。
6.代码实现:
from PIL import Image
import numpy as np
im = Image.open("C:/Users/21974/Desktop/handwrite2.PNG")
total = 9000000
count = 0
defin = 0
width = im.size[0]
height = im.size[1]
for i in range(total): #用蒙特卡罗方法获得估计值
x = np.random.randint(0, width-1)
y = np.random.randint(0, height-1)
k = im.getpixel((x, y))
if k[0]+k[1]+k[2] == 0:
count += 1
print(int(width*height*count/total))
for i in range(width): #用遍历获得准确值
for j in range(height):
k = im.getpixel((i, j))
if k[0] + k[1] + k[2] == 0:
defin += 1
print(defin)
上面的代码可分为两部分,第一个for后面是用蒙特卡罗方法获得的面积的估计值,第二个for后面是用遍历所有像素点的方法获得的面积的精确值,获得两个输出后进行对比。

我们在上面的程序中采用了9000000个随机数,可以看出两个输出结果相差并不大。
相关推荐
-

python买卖股票的最佳时机(基于贪心/蛮力算法)
开始刷leetcode算法题 今天做的是"买卖股票的最佳时机" 题目要求 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格. 设计一个算法来计算你所能获取的最大利润.你可以尽可能地完成更多的交易(多次买卖一支股票). 注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票). 看到这个题目 最初的想法是蛮力法 通过两层循环 不断计算不同天之间的利润及利润和 下面上代码 class Solution(object): def maxProfit(self, pri
-
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心. 3.对每个点确定其聚类中心点. 4.再计算其聚类新中心. 5.重复以上步骤直到满足收敛要求.(通常就是确定的中心点不再改变. 优点: 1.是解决聚类问题的一种经典算法,简单.快速 2.对处理大数据集,该算法保持可伸缩性和高效率 3.当结果簇是密集的,它的效果较好 缺点 1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用 2.必须事先给出k(要生成的簇的数
-
python编程通过蒙特卡洛法计算定积分详解
想当初,考研的时候要是知道有这么个好东西,计算定积分...开玩笑,那时候计算定积分根本没有这么简单的.但这确实给我打开了一种思路,用编程语言去解决更多更复杂的数学问题.下面进入正题. 如上图所示,计算区间[a b]上f(x)的积分即求曲线与X轴围成红色区域的面积.下面使用蒙特卡洛法计算区间[2 3]上的定积分:∫(x2+4*x*sin(x))dx # -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt
-
Python实现蒙特卡洛算法小实验过程详解
蒙特卡洛算法思想 蒙特卡洛(Monte Carlo)法是一类随机算法的统称,提出者是大名鼎鼎的数学家冯·诺伊曼,他在20世纪40年代中期用驰名世界的赌城-摩纳哥的蒙特卡洛来命名这种方法. 通俗的解释一下蒙特卡洛算法的思想.假如篮子里有1000个苹果,让你每次闭着眼睛拿1个,挑出最大的.于是你闭着眼睛随机拿了一个,然后再随机拿一个与第一个比,留下大的,再随机拿一个,与前次留下的比较,又可以留下大的--你每拿一次,留下的苹果至少是当前最大的,循环往复这样,拿的次数越多,挑出最大苹果的可能性也就越大,
-
python 随机森林算法及其优化详解
前言 优化随机森林算法,正确率提高1%~5%(已经有90%+的正确率,再调高会导致过拟合) 论文当然是参考的,毕竟出现早的算法都被人研究烂了,什么优化基本都做过.而人类最高明之处就是懂得利用前人总结的经验和制造的工具(说了这么多就是为偷懒找借口.hhhh) 优化思路 1. 计算传统模型准确率 2. 计算设定树木颗数时最佳树深度,以最佳深度重新生成随机森林 3. 计算新生成森林中每棵树的AUC,选取AUC靠前的一定百分比的树 4. 通过计算各个树的数据相似度,排除相似度超过设定值且AUC较小的树
-
python TF-IDF算法实现文本关键词提取
TF(Term Frequency)词频,在文章中出现次数最多的词,然而文章中出现次数较多的词并不一定就是关键词,比如常见的对文章本身并没有多大意义的停用词.所以我们需要一个重要性调整系数来衡量一个词是不是常见词.该权重为IDF(Inverse Document Frequency)逆文档频率,它的大小与一个词的常见程度成反比.在我们得到词频(TF)和逆文档频率(IDF)以后,将两个值相乘,即可得到一个词的TF-IDF值,某个词对文章的重要性越高,其TF-IDF值就越大,所以排在最前面的几个词就
-
python实现蒙特卡罗方法教程
蒙特卡罗方法是一种统计模拟方法,由冯·诺依曼和乌拉姆提出,在大量的随机数下,根据概率估计结果,随机数据越多,获得的结果越精确.下面我们将用python实现蒙特卡罗方法. 1.首先我们做一个简单的圆周率的近似计算,在这个过程中我们要用到随机数,因此需要先使用import numpy as np导入numpy库. 2.代码实现: import numpy as np total = 8000000 count = 0 for i in range(total): x = np.random.rand
-
将 Ubuntu 16 和 18 上的 python 升级到最新 python3.8 的方法教程
1. 概述 本文记录在 Ubuntu 16.04 上将 python 升级为 3.8 版本,并配置为系统默认 python3 的过程. 在 Ubuntu 16.04 中,python3 的默认版本为 3.5: $ python3 -V Python 3.5.2 本文以在 Ubuntu 16.04 中安装为例,方法同样适用于 Ubuntu 18.04 . 2. 通过 Apt 安装 Ubuntu 官方 apt 库中还未收录 python 3.8,这里使用 deadsnakes PPA 库安装. 2.
-
Python基于域相关实现图像增强的方法教程
目录 介绍 昆虫增强 使用针的增强 实验结果 介绍 当在图像上训练深度神经网络模型时,通过对由数据增强生成的更多图像进行训练,可以使模型更好地泛化.常用的增强包括水平和垂直翻转/移位.以一定角度和方向(顺时针/逆时针)随机旋转.亮度.饱和度.对比度和缩放增强. Python中一个非常流行的图像增强库是albumentations(https://albumentations.ai/),通过直观的函数和优秀的文档,可以轻松地增强图像.它也可以与PyTorch和TensorFlow等流行的深度学习框
-
python打印日志方法的使用教程(logging模块)
目录 一.必备技能 1.logging模块的使用 二.logging 1.logging的基本使用 1.1.日志的五个等级(DEBUG/INFO/WARNING/ERROR/CRITICAL) 1.2.打印不同日志等级的方法: 2.自定义日志收集器 2.1.创建日志收集器 总结 一.必备技能 1.logging模块的使用 (1)5个日志等级/以及5个输出日志的内置函数 (2)日志收集器.日志输出渠道的概念 (3)如何自定义日志收集器 (4)如何封装自定义的日志收集器 二.logging pyth
-
python安装Scrapy图文教程
安装方法 pip install Scrapy 如果顺利的话不用管直接一路下来就OK 验证是否安装成功 安装成功 不顺利的情况 1)lxml安装不成功 使用whl进行安装,不过需要先安装whl pip install wheel 安装完成后下载lxml的whl文件 网址: http://www.lfd.uci.edu/~gohlke/pythonlibs/ whl版本挑选 进入cmd-->import pip-->print pip.pep425tags.get_supported(),按照截
-
Python画图学习入门教程
本文实例讲述了Python画图的基本方法.分享给大家供大家参考,具体如下: Python:使用matplotlib绘制图表 python绘制图表的方法,有个强大的类库matplotlib,可以制作出高质量的2D和3D图形,先记录一下,以后慢慢学习. matplotlib下载及API手册地址:http://sourceforge.net/projects/matplotlib/files/matplotlib/ 数学库numpy下载及API手册地址:http://www.scipy.org/Dow
-
Python编程实现双击更新所有已安装python模块的方法
本文实例讲述了Python编程实现双击更新所有已安装python模块的方法.分享给大家供大家参考,具体如下: 首先声明我是一个升级控.几乎每天会查看一下手机.电脑是否有新的应用需要更新. 同样,我的python模块也是这样.百度了一下,发现目前还没有人将更新所有模块做成一件命令,但是查到了指引,主要就是两个命令. pip list --outdated pip install -U xxxx 当然,如果你只是安装了几个python模块,重复执行几次命令也是可以的,也不会太烦,也不会浪费时间. 有
-
Python数组定义方法
本文实例讲述了Python数组定义方法.分享给大家供大家参考,具体如下: Python中没有数组的数据结构,但列表很像数组,如: a=[0,1,2] 这时:a[0]=0, a[1]=1, a[[2]=2,但引出一个问题,即如果数组a想定义为0到999怎么办?这时可能通过a = range(0, 1000)实现.或省略为a = range(1000).如果想定义1000长度的a,初始值全为0,则 a = [0 for x in range(0, 1000)] 下面是二维数组的定义: 直接定义: a
-
Python sqlite3事务处理方法实例分析
本文实例讲述了Python sqlite3事务处理方法.分享给大家供大家参考,具体如下: sqlite3事务总结: 在connect()中不传入 isolation_level 事务处理: 使用connection.commit() #!/usr/bin/env python # -*- coding:utf-8 -*- '''sqlite3事务总结: 在connect()中不传入 isolation_level 事务处理: 使用connection.commit() 分析: 智能commit状
-
python字符串连接方法分析
本文实例分析了python字符串连接方法.分享给大家供大家参考,具体如下: python字符串连接有几种方法,把大家可能用到的列出来,第一个方法效率是最低的,另外给大家介绍后面的 2种效率高的方法,希望对大家有帮助. 先介绍下效率比较低的,有些新手朋友就会犯这个错误: a = ['a','b','c','d'] content = '' for i in a: content = content + i print content 说下为什么效率会低呢? 原因:在循环连接字符串的时候,他每次连接