详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰。
希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式。
比如这里给出
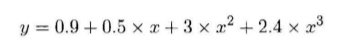
很显然,这里我们只需要假定
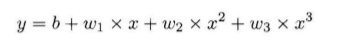
这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可。
但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢?
只将一个x作为输入合理吗?显然是不合理的,因为每一个神经元其实模拟的是wx+b的计算过程,无法模拟幂运算,所以显然我们需要将x,x的平方,x的三次方,x的四次方组合成一个向量作为输入,假设有n个不同的x值,我们就可以将n个组合向量合在一起组成输入矩阵。
这一步代码如下:
def make_features(x): x = x.unsqueeze(1) return torch.cat([x ** i for i in range(1,4)] , 1)
我们需要生成一些随机数作为网络输入:
def get_batch(batch_size=32): random = torch.randn(batch_size) x = make_features(random) '''Compute the actual results''' y = f(x) if torch.cuda.is_available(): return Variable(x).cuda(), Variable(y).cuda() else: return Variable(x), Variable(y)
其中的f(x)定义如下:
w_target = torch.FloatTensor([0.5,3,2.4]).unsqueeze(1) b_target = torch.FloatTensor([0.9]) def f(x): return x.mm(w_target)+b_target[0]
接下来定义模型:
class poly_model(nn.Module): def __init__(self): super(poly_model, self).__init__() self.poly = nn.Linear(3,1) def forward(self, x): out = self.poly(x) return out
if torch.cuda.is_available(): model = poly_model().cuda() else: model = poly_model()
接下来我们定义损失函数和优化器:
criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr = 1e-3)
网络部件定义完后,开始训练:
epoch = 0 while True: batch_x,batch_y = get_batch() output = model(batch_x) loss = criterion(output,batch_y) print_loss = loss.data[0] optimizer.zero_grad() loss.backward() optimizer.step() epoch+=1 if print_loss < 1e-3: break
到此我们的所有代码就敲完了,接下来我们开始详细了解一下其中的一些代码。
在make_features()定义中,torch.cat是将计算出的向量拼接成矩阵。unsqueeze是作一个维度上的变化。
get_batch中,torch.randn是产生指定维度的随机数,如果你的机器支持GPU加速,可以将Variable放在GPU上进行运算,类似语句含义相通。
x.mm是作矩阵乘法。
模型定义是重中之重,其实当你掌握Pytorch之后,你会发现模型定义是十分简单的,各种基本的层结构都已经为你封装好了。所有的层结构和损失函数都来自torch.nn,所有的模型构建都是从这个基类 nn.Module继承的。模型定义中,__init__与forward是有模板的,大家可以自己体会。
nn.Linear是做一个线性的运算,参数的含义代表了输入层与输出层的结构,即3*1;在训练阶段,有几行是Pytorch不同于别的框架的,首先loss是一个Variable,通过loss.data可以取出一个Tensor,再通过data[0]可以得到一个int或者float类型的值,我们才可以进行基本运算或者显示。每次计算梯度之前,都需要将梯度归零,否则梯度会叠加。个人觉得别的语句还是比较好懂的,如果有疑问可以在下方评论。
下面是我们的拟合结果

其实效果肯定会很好,因为只是一个非常简单的全连接网络,希望大家通过这个小例子可以学到Pytorch的一些基本操作。往后我们会继续更新,完整代码请戳,https://github.com/ZhichaoDuan/PytorchCourse
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pytorch 在网络中添加可训练参数,修改预训练权重文件的方法
实践中,针对不同的任务需求,我们经常会在现成的网络结构上做一定的修改来实现特定的目的. 假如我们现在有一个简单的两层感知机网络: # -*- coding: utf-8 -*- import torch from torch.autograd import Variable import torch.optim as optim x = Variable(torch.FloatTensor([1, 2, 3])).cuda() y = Variable(torch.FloatTensor([4,
-
关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇. TensorFlow: 228--->266 Keras: 42--->56 Pytorch: 87--->252 在使用pytorch中,自己有一些思考,如下: 1. loss计算和反向传播 import torch.nn as nn
-

详解如何使用Pytorch进行多卡训练
目录 1.DP 2.DDP 2.1Pytorch分布式基础 2.2Pytorch分布式训练DEMO 当一块GPU不够用时,我们就需要使用多卡进行并行训练.其中多卡并行可分为数据并行和模型并行.具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录.对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(DistributedDataParallel, DDP). 在多卡训练的实现上,DP与DDP的思路是相似的: 1.每张卡都复制
-
详解tensorflow之过拟合问题实战
过拟合问题实战 1.构建数据集 我们使用的数据集样本特性向量长度为 2,标签为 0 或 1,分别代表了 2 种类别.借助于 scikit-learn 库中提供的 make_moons 工具我们可以生成任意多数据的训练集. import matplotlib.pyplot as plt # 导入数据集生成工具 import numpy as np import seaborn as sns from sklearn.datasets import make_moons from sklearn.m
-
详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰. 希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式. 比如这里给出 很显然,这里我们只需要假定 这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可. 但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢? 只将一个x作为输入
-
PyTorch快速搭建神经网络及其保存提取方法详解
有时候我们训练了一个模型, 希望保存它下次直接使用,不需要下次再花时间去训练 ,本节我们来讲解一下PyTorch快速搭建神经网络及其保存提取方法详解 一.PyTorch快速搭建神经网络方法 先看实验代码: import torch import torch.nn.functional as F # 方法1,通过定义一个Net类来建立神经网络 class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output):
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
PyTorch: 梯度下降及反向传播的实例详解
线性模型 线性模型介绍 线性模型是很常见的机器学习模型,通常通过线性的公式来拟合训练数据集.训练集包括(x,y),x为特征,y为目标.如下图: 将真实值和预测值用于构建损失函数,训练的目标是最小化这个函数,从而更新w.当损失函数达到最小时(理想上,实际情况可能会陷入局部最优),此时的模型为最优模型,线性模型常见的的损失函数: 线性模型例子 下面通过一个例子可以观察不同权重(w)对模型损失函数的影响. #author:yuquanle #data:2018.2.5 #Study of Linear
-
Python编程pytorch深度卷积神经网络AlexNet详解
目录 容量控制和预处理 读取数据集 2012年,AlexNet横空出世.它首次证明了学习到的特征可以超越手工设计的特征.它一举打破了计算机视觉研究的现状.AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年的ImageNet图像识别挑战赛. 下图展示了从LeNet(左)到AlexNet(right)的架构. AlexNet和LeNet的设计理念非常相似,但也有如下区别: AlexNet比相对较小的LeNet5要深得多. AlexNet使用ReLU而不是sigmoid作为其激活函数
-
Pytorch自动求导函数详解流程以及与TensorFlow搭建网络的对比
一.定义新的自动求导函数 在底层,每个原始的自动求导运算实际上是两个在Tensor上运行的函数.其中,forward函数计算从输入Tensor获得的输出Tensors.而backward函数接收输出,Tensors对于某个标量值得梯度,并且计算输入Tensors相对于该相同标量值得梯度. 在Pytorch中,可以容易地通过定义torch.autograd.Function的子类实现forward和backward函数,来定义自动求导函数.之后就可以使用这个新的自动梯度运算符了.我们可以通过构造一
-
PyTorch中torch.nn.Linear实例详解
目录 前言 1. nn.Linear的原理: 2. nn.Linear的使用: 3. nn.Linear的源码定义: 补充:许多细节需要声明 总结 前言 在学习transformer时,遇到过非常频繁的nn.Linear()函数,这里对nn.Linear进行一个详解.参考:https://pytorch.org/docs/stable/_modules/torch/nn/modules/linear.html 1. nn.Linear的原理: 从名称就可以看出来,nn.Linear表示的是线性变
-
关于PyTorch 自动求导机制详解
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile.它们都允许从梯度计算中精细地排除子图,并可以提高效率. requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度.相反,只有所有输入都不需要梯度,输出才不需要.如果其中所有的变量都不需要梯度进行,后向计算不会在子图中执行. >>> x = Variable(torch.randn(5, 5)) >>> y = Variable(torch.rand