利用Sharding-Jdbc组件实现分表
看到了当当开源的Sharding-JDBC组件,它可以在几乎不修改代码的情况下完成分库分表的实现。摘抄其中一段介绍:
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
- 可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等。
- 理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle,SQLServer,DB2等数据库的计划。
先做一个最简单的试用,不做分库,仅做分表。选择数据表bead_information,首先复制成三个表:bead_information_0、bead_information_1、bead_information_2

测试实现过程
前提:已经实现srping+mybatis对单库单表做增删改查的项目。
1、修改pom.xml增加dependency
<dependency> <groupId>com.dangdang</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>1.4.2</version> </dependency> <dependency> <groupId>com.dangdang</groupId> <artifactId>sharding-jdbc-config-spring</artifactId> <version>1.4.0</version> </dependency>
2、新建一个sharding-jdbc.xml文件,实现分库分表的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:rdb="http://www.dangdang.com/schema/ddframe/rdb"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.dangdang.com/schema/ddframe/rdb
http://www.dangdang.com/schema/ddframe/rdb/rdb.xsd">
<!-- 配置数据源 -->
<bean name="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="jdbc:mysql://localhost:3306/beadhouse" />
<property name="username" value="root" />
<property name="password" value="123456" />
</bean>
<rdb:strategy id="tableShardingStrategy" sharding-columns="id" algorithm-class="com.springdemo.utill.MemberSingleKeyTableShardingAlgorithm"/>
<rdb:data-source id="shardingDataSource">
<rdb:sharding-rule data-sources="dataSource">
<rdb:table-rules>
<rdb:table-rule logic-table="bead_information" actual-tables="bead_information_${0..2}" table-strategy="tableShardingStrategy"/>
</rdb:table-rules>
</rdb:sharding-rule>
</rdb:data-source>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="shardingDataSource" />
</bean>
</beans>
3、将文件引入spring配置文件中。
需要修改几个地方,把sqlSessionFactory和transactionManager原来关联的dataSource统一修改为shardingDataSource(这一步作用就是把数据源全部托管给sharding去管理)
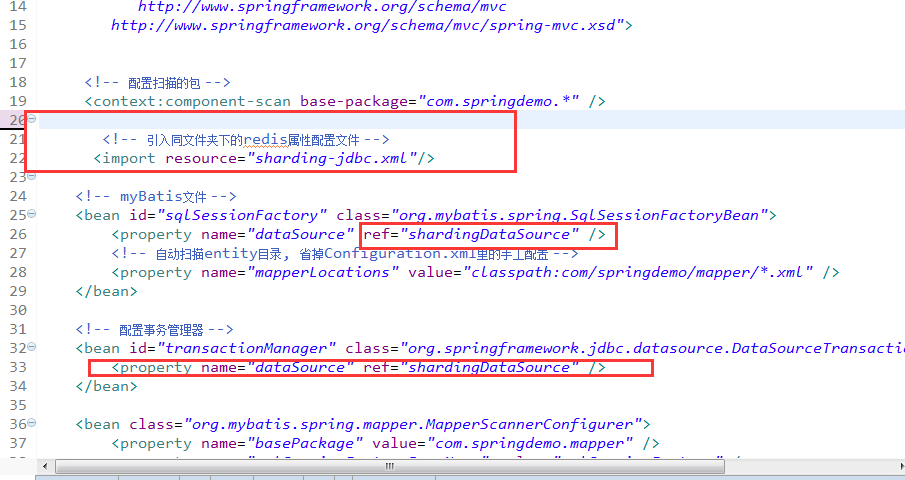
4、实现分表(分库)逻辑,我们的分表逻辑类需要实现SingleKeyTableShardingAlgorithm接口的三个方法doBetweenSharding、doEqualSharding、doInSharding
(取模除数需要按照自己需求改变,我这里分3个表,所以除以3)
import java.util.Collection;
import java.util.LinkedHashSet;
import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm;
import com.google.common.collect.Range;
public class MemberSingleKeyTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Integer> {
@Override
public Collection<String> doBetweenSharding(Collection<String> tableNames, ShardingValue<Integer> shardingValue) {
Collection<String> result = new LinkedHashSet<String>(tableNames.size());
Range<Integer> range = (Range<Integer>) shardingValue.getValueRange();
for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
Integer modValue = i % 3;
String modStr = modValue < 3 ? "" + modValue : modValue.toString();
for (String each : tableNames) {
if (each.endsWith(modStr)) {
result.add(each);
}
}
}
return result;
}
@Override
public String doEqualSharding(Collection<String> tableNames, ShardingValue<Integer> shardingValue) {
Integer modValue = shardingValue.getValue() % 3;
String modStr = modValue < 3 ? "" + modValue : modValue.toString();
for (String each : tableNames) {
if (each.endsWith(modStr)) {
return each;
}
}
throw new IllegalArgumentException();
}
@Override
public Collection<String> doInSharding(Collection<String> tableNames, ShardingValue<Integer> shardingValue) {
Collection<String> result = new LinkedHashSet<String>(tableNames.size());
for (Integer value : shardingValue.getValues()) {
Integer modValue = value % 3;
String modStr = modValue < 3 ? "" + modValue : modValue.toString();
for (String tableName : tableNames) {
if (tableName.endsWith(modStr)) {
result.add(tableName);
}
}
}
return result;
}
}
5、配置完成,可以实现增删改查测试。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
spring hibernate实现动态替换表名(分表)的方法
1.概述 其实最简单的办法就是使用原生sql,如 session.createSQLQuery("sql"),或者使用jdbcTemplate.但是项目中已经使用了hql的方式查询,修改起来又累,风险又大!所以,必须找到一种比较好的解决方案,实在不行再改写吧!经过3天的时间的研究,终于找到一种不错的方法,下面讲述之. 2.步骤 2.1 新建hibernate interceptor类 /** * Created by hdwang on 2017/8/7. * * hibernate拦
-

SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多
-
利用Sharding-Jdbc组件实现分表
看到了当当开源的Sharding-JDBC组件,它可以在几乎不修改代码的情况下完成分库分表的实现.摘抄其中一段介绍: Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零: 可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC. 可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等. 理论上可支持任意实现JDB
-
SpringBoot集成Sharding Jdbc使用复合分片的实践
目录 1.Sharing JDBC 简介 2.系统改造 2.1 对接外部系统的系统 2.2 内部系统间的调用 3.解决方案 4.代码实现 4.1 Sharding JDBC 配置 4.2 数据源操作类 4.3 分片测试类 4.4 测试结果 参考文章: 最近主要的工作重心是数据库的容量规划. 随着业务的逐渐增大,原有保存在单表的数据量也日益增强.数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大.再加上物理服务器的资源有限(CPU.磁盘.内存.IO 等).最终数据库所
-
SpringBoot整合sharding-jdbc实现自定义分库分表的实践
目录 一.前言 二.简介 1.分片键 2.分片算法 三.程序实现 一.前言 SpringBoot整合sharding-jdbc实现分库分表与读写分离 本文将通过自定义算法来实现定制化的分库分表来扩展相应业务 二.简介 1.分片键 用于数据库/表拆分的关键字段 ex: 用户表根据user_id取模拆分到不同的数据库中 2.分片算法 可参考:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere
-
C#中efcore-ShardingCore呈现“完美”分表
目录 efcore支持情况 数据库支持情况 如何开始使用 自定义分表键,自定义分表规则 默认路由 动态添加分表信息 支持select,join,group by等连表聚合函数 分页 无感知使用 读写分离的支持 如果您对分表有以下痛点那么不妨试试我这边开源的框架sharding-core,是否需要无感知使用分表组件,是否需要支持abp,是否需要支持自定义分表规则,是否需要支持自定义分表键,是否需要支持特定的efcore版本,是否希望框架不带任何三方框架干净,是否需要支持读写分离,是否需要动态添加表
-
利用Sharding-Jdbc进行分库分表的操作代码
目录 1. Sharding-Jdbc介绍 2. Sharding-Jdbc引入使用 3. 配置广播表 4. 配置绑定表 5. 读写分离配置 1. Sharding-Jdbc介绍 https://shardingsphere.apache.org/ sharding-jdbc是一个分布式的关系型数据库中间件 客户端代理模式,不需要搭建服务器,只需要后端数据库即可,有个IDE就行了 定位于轻量级的Java框架,以jar的方式提供服务 可以理解为增强版的jdbc驱动 完全兼容主流的ORM框架 sha
-
Java基于ShardingSphere实现分库分表的实例详解
目录 一.简介 二.项目使用 1.引入依赖 2.数据库 3.实体类 4.mapper 5.yml配置 6.测试类 7.数据 一.简介 Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC.Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成. 它们均提供标准化的数据水平扩展.分布式事务和分布式治理等功能,可适用于如 Java 同构.异构语言.云原生等各种多样化的应用场景. Apache Sh
-
Springboot2.x+ShardingSphere实现分库分表的示例代码
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务.而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库. 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案. 垂直分片往往需要对架构和设计进行调整.通常来讲,是来不及应对互联网业务需求快速变化
-
Java中ShardingSphere分库分表实战
目录 一. 项目需求 二. 简介sharding-sphere 三. 项目实战 四. 测试 一. 项目需求 我们做项目的时候,数据量比较大,单表千万级别的,需要分库分表,于是在网上搜索这方面的开源框架,最常见的就是mycat,sharding-sphere,最终我选择后者,用它来做分库分表比较容易上手. 二. 简介sharding-sphere 官网地址: https://shardingsphere.apache.org/ ShardingSphere是一套开源的分布式数据库中间件解决方案组成
-
SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表
目录 一.序言 1.组件及版本选择 2.预期目标 二.代码实现 (一)素材准备 1.实体类 2.Mapper类 3.全局配置文件 (二)增删查改 1.保存数据 2.查询列表数据 3.分页查询数据 4.查询详情 5.删除数据 6.修改数据 三.理论分析 1.选择分片列 2.扩容 一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于SpringBoot+Myba