python读csv文件时指定行为表头或无表头的方法
pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头。若设置为-1,则无表头。示例如下:
(1)不设置header参数(默认)时:
df1 = pd.read_csv('target.csv',encoding='utf-8')
df1
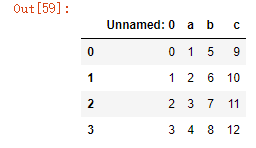
(2)header=1时:
import pandas as pd
df2 = pd.read_csv('target.csv',encoding='utf-8',header=1)
df2

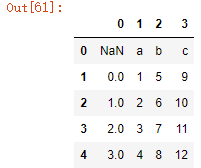
(3)header=-1时(可用于读取无表头CSV文件):
df3 = pd.read_csv('target.csv',encoding='utf-8',header=-1)
df3
PS:python 从 CSV 文件中删除表头
假设你有一个枯燥的任务,要删除几百 CSV 文件的第一行。也许你会将它们送入一个自动化的过程,只需要数据,不需要每列顶部的表头。可以在 Excel 中打开每个文件,删除第一行,并重新保存该文件,但这需要几个小时。让我们写一个程序来做这件事。该程序需要打开当前工作目录中所有扩展名为.csv 的文件,读取 CSV 文件的内容,并除掉第一行的内容重新写入同名的文件。这将用新的、无表头的内容替换CSV 文件的旧内容。
总的来说,该程序必须做到以下几点:
- 找出当前工作目录中的所有 CSV 文件。
- 读取每个文件的全部内容。
- 跳过第一行,将内容写入一个新的 CSV 文件。
在代码层面上,这意味着该程序需要做到以下几点:
- 循环遍历从 os.listdir()得到的文件列表,跳过非 CSV 文件。
- 创建一个 CSV Reader 对象,读取该文件的内容,利用 line_num 属性确定要跳过哪一行。
- 创建一个 CSV Writer 对象,将读入的数据写入新文件。针对这个项目,打开一个新的文件编辑器窗口,并保存为 removeCsvHeader.py。
循环遍历每个 CSV 文件
程序需要做的第一件事情,就是循环遍历当前工作目录中所有 CSV 文件名的列表。让 removeCsvHeader.py 看起来像这样:
#! python3
# removeCsvHeader.py - Removes the header from all CSV files in the current
# working directory
import csv, os
os.makedirs('headerRemoved', exist_ok=True)
# Loop through every file in the current working directory.
for csvFilename in os.listdir('.'):
if not csvFilename.endswith('.csv'):
continue # skip non-csv files
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python读取csv文件示例(python操作csv)
复制代码 代码如下: import csvfor line in open("test.csv"):name,age,birthday = line.split(",")name = name.strip(' \t\r\n');age = age.strip(' \t\r\n');birthday = birthday.strip(' \t\r\n'); print (name + '\t' + age + '\t' + birthday) csv文件 复制代码 代
-
Python读取mat文件,并转为csv文件的实例
初学Python,遇到需要将mat文件转为csv文件,看了很多博客,最后找到了解决办法,代码如下: #方法1 from pandas import Series,DataFrame import pandas as pd import numpy as np import h5py datapath = 'E:/workspacelxr/contem/data.mat' file = h5py.File(datapath,'r') file.keys() def Print(name):prin
-
python实现对csv文件的列的内容读取
以下代码测试在python2.7 mac上运行成功 import csv with open('/Users/wangzhao/Downloads/test.csv', 'U') as csvfile: reader = csv.DictReader(csvfile) column = [row['Employee Name'] for row in reader] print column import csv with open('/Users/wangzhao/Downloads/test
-
Python读取csv文件分隔符设置方法
Windows下的分隔符默认的是逗号,而MAC的分隔符是分号.拿到一份用分号分割的CSV文件,在Win下是无法正确读取的,因为CSV模块默认调用的是Excel的规则. 所以我们在读取文件的时候需要添加分割符变量. import csv import os cwd = os.getcwd() print ("Current folder is %s" % (cwd) ) csvfile = open( cwd + '\data\eclipse\change-metrics.csv','r
-

Python实现读取及写入csv文件的方法示例
本文实例讲述了Python实现读取及写入csv文件的方法.分享给大家供大家参考,具体如下: 新建csvData.csv文件,数据如下: 具体代码如下: # coding:utf-8 import csv # 读取csv文件方式1 csvFile = open("csvData.csv", "r") reader = csv.reader(csvFile) # 返回的是迭代类型 data = [] for item in reader: print(item) dat
-
python 循环读取txt文档 并转换成csv的方法
如下所示: # -*- coding: utf-8 -*- """ Created on Fri Jul 29 15:49:06 2016 @author: user """ import os #从文件中读取某一行 linecache.checkcache可以刷新cache ,linecache可以缓存某一行的信息 import linecache def GetFileNameAndExt(filename): (filepath,tempf
-
python 读取目录下csv文件并绘制曲线v111的方法
实例如下: # -*- coding: utf-8 -*- """ Spyder Editor This temporary script file is located here: C:\Users\user\.spyder2\.temp.py """ """ Show how to modify the coordinate formatter to report the image "z"
-
python读取csv和txt数据转换成向量的实例
最近写程序需要从文件中读取数据,并把读取的数据转换成向量. 查阅资料之后找到了读取csv文件和txt文件两种方式,下面结合自己的实验过程,做简要记录,供大家参考: 1.读取csv文件的数据 import csv filtpath = "data_test.csv" with open(filtpath,'r') as csvfile: reader = csv.reader(csvfile) header = next(reader) data = [] for line in rea
-
python读取与写入csv格式文件的示例代码
在数据分析中经常需要从csv格式的文件中存取数据以及将数据写书到csv文件中.将csv文件中的数据直接读取为 dict 类型和 DataFrame 是非常方便也很省事的一种做法,以下代码以鸢尾花数据为例. csv文件读取为dict 代码 # -*- coding: utf-8 -*- import csv with open('E:/iris.csv') as csvfile: reader = csv.DictReader(csvfile, fieldnames=None) # fieldna
-
python读csv文件时指定行为表头或无表头的方法
pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头.若设置为-1,则无表头.示例如下: (1)不设置header参数(默认)时: df1 = pd.read_csv('target.csv',encoding='utf-8') df1 (2)header=1时: import pandas as pd df2 = pd.read_csv('target.csv',encoding='utf-8',header=1) df2 (3)header=-1时(可用
-
Python读csv文件去掉一列后再写入新的文件实例
用了两种方式解决该问题,都是网上现有的解决方案. 场景说明: 有一个数据文件,以文本方式保存,现在有三列user_id,plan_id,mobile_id.目标是得到新文件只有mobile_id,plan_id. 解决方案 方案一:用python的打开文件写文件的方式直接撸一遍数据,for循环内处理数据并写入到新文件. 代码如下: def readwrite1( input_file,output_file): f = open(input_file, 'r') out = open(outpu
-
python的pandas工具包,保存.csv文件时不要表头的实例
用pandas处理.csv文件时,有时我们希望保存的.csv文件没有表头,于是我去看了DataFrame.to_csv的document. 发现只需要再添加header=None这个参数就行了(默认是True), 下面贴上document: DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=Non
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
Python如何读取csv文件时添加表头/列名
目录 读取csv文件时添加表头/列名 解决方法 更改csv文件表头 读取csv文件时添加表头/列名 有时,我们读取的csv文件数据时发现没有表头/列名,是因为Python读取csv文件数据本来就没有表头,用pandas.read读取时,则第一行自动会被识别为columns,从而给后面的分析造成不便,这时候需要我们在读取文件数据的同时添加列名. 解决方法 1.在读取文件数据之后再定义列名 df = pd.read_csv('评论.csv',header=None) df.columns = ["昵
-
Python取读csv文件做dbscan分析
目录 1.读取csv数据做dbscan分析 2.输出结果显示 3.计算效率 1.读取csv数据做dbscan分析 读取csv文件中相应的列,然后进行转化,处理为本算法需要的格式,然后进行dbscan运算,目前公开的代码也比较多,本文根据公开代码修改, 具体代码如下: from sklearn import datasets import numpy as np import random import matplotlib.pyplot as plt import time import cop
-
python 读txt文件,按‘,’分割每行数据操作
按行读取TXT文件 fname = './新建文件夹/yob2010.txt' //文件夹路径 with open(fname,'r+',encoding='utf-8') as f: for line in f.readlines(): //按行读取每行 print(line[:-1].split(',')) //切片去掉换行符,再以','分割字符串 ,得到一个列表 s = [i[:-1].split(',') for i in f.readlines()] //列表生成器,将文件每行数据按上
-
利用python 读写csv文件
1.读文件 import csv csv_reader = csv.reader(open("data.file", encoding="utf-8")) for row in csv_reader: print(row) csv_reader把每一行数据转化成了一个list,list中每个元素是一个字符串. 2.写文件 读文件时,我们把csv文件读入列表中,写文件时会把列表中的元素写入到csv文件中. list = ["1", "2&
-
python删除csv文件的行列
1. 读取数据 用pandas中的read_csv()函数读取出csv文件中的数据: import pandas as pd df = pd.read_csv("comments.csv") df.head(2) 用drop函数进行文件中数据的删除行或者删除列操作. 2. 删除列操作 方法一:假设我们要删除的列的名称为 '观众ID','评分' : df=df.drop(['观众ID','评分'],axis=1) 方法二: #删除指定列 df.drop(columns=["城市
-
Python将CSV文件转化为HTML文件的操作方法
What' s CSV CSV 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本). 纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据.CSV文件由任意数目的记录组成,记录间以某种换行符分隔:每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符. 通常,所有记录都有完全相同的字段序列.通常都是纯文本文件.建议使用WORDPAD或是记事本来开