Python中的支持向量机SVM的使用(附实例代码)
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类。因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm。
一、导入sklearn算法包
Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明:http://scikit-learn.org/stable/auto_examples/index.html。
skleran中集成了许多算法,其导入包的方式如下所示,
逻辑回归:from sklearn.linear_model import LogisticRegression
朴素贝叶斯:from sklearn.naive_bayes import GaussianNB
K-近邻:from sklearn.neighbors import KNeighborsClassifier
决策树:from sklearn.tree import DecisionTreeClassifier
支持向量机:from sklearn import svm
二、sklearn中svc的使用
(1)使用numpy中的loadtxt读入数据文件
loadtxt()的使用方法:

fname:文件路径。eg:C:/Dataset/iris.txt。
dtype:数据类型。eg:float、str等。
delimiter:分隔符。eg:‘,'。
converters:将数据列与转换函数进行映射的字典。eg:{1:fun},含义是将第2列对应转换函数进行转换。
usecols:选取数据的列。
以Iris兰花数据集为例子:
由于从UCI数据库中下载的Iris原始数据集的样子是这样的,前四列为特征列,第五列为类别列,分别有三种类别Iris-setosa, Iris-versicolor, Iris-virginica。
当使用numpy中的loadtxt函数导入该数据集时,假设数据类型dtype为浮点型,但是很明显第五列的数据类型并不是浮点型。
因此我们要额外做一个工作,即通过loadtxt()函数中的converters参数将第五列通过转换函数映射成浮点类型的数据。
首先,我们要写出一个转换函数:
def iris_type(s):
it = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
return it[s]
接下来读入数据,converters={4: iris_type}中“4”指的是第5列:
path = u'D:/f盘/python/学习/iris.data' # 数据文件路径
data = np.loadtxt(path, dtype=float, delimiter=',', converters={4: iris_type})
读入结果:

(2)将Iris分为训练集与测试集
x, y = np.split(data, (4,), axis=1) x = x[:, :2] x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6)
1.split(数据,分割位置,轴=1(水平分割) or 0(垂直分割))。
2.x = x[:, :2]是为方便后期画图更直观,故只取了前两列特征值向量训练。
3. sklearn.model_selection.train_test_split随机划分训练集与测试集。train_test_split(train_data,train_target,test_size=数字, random_state=0)
参数解释:
- train_data:所要划分的样本特征集
- train_target:所要划分的样本结果
- test_size:样本占比,如果是整数的话就是样本的数量
- random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
(3)训练svm分类器
# clf = svm.SVC(C=0.1, kernel='linear', decision_function_shape='ovr') clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr') clf.fit(x_train, y_train.ravel())
kernel='linear'时,为线性核,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
kernel='rbf'时(default),为高斯核,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
decision_function_shape='ovr'时,为one v rest,即一个类别与其他类别进行划分,
decision_function_shape='ovo'时,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
(4)计算svc分类器的准确率
print clf.score(x_train, y_train) # 精度 y_hat = clf.predict(x_train) show_accuracy(y_hat, y_train, '训练集') print clf.score(x_test, y_test) y_hat = clf.predict(x_test) show_accuracy(y_hat, y_test, '测试集')
结果为:

如果想查看决策函数,可以通过decision_function()实现
print 'decision_function:\n', clf.decision_function(x_train) print '\npredict:\n', clf.predict(x_train)
结果为:


decision_function中每一列的值代表距离各类别的距离。
(5)绘制图像
1.确定坐标轴范围,x,y轴分别表示两个特征
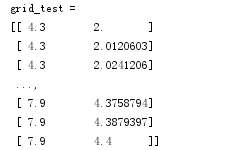
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围 x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围 x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j] # 生成网格采样点 grid_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点 # print 'grid_test = \n', grid_testgrid_hat = clf.predict(grid_test) # 预测分类值grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
这里用到了mgrid()函数,该函数的作用这里简单介绍一下:
假设假设目标函数F(x,y)=x+y。x轴范围1~3,y轴范围4~6,当绘制图像时主要分四步进行:
【step1:x扩展】(朝右扩展):
[1 1 1]
[2 2 2]
[3 3 3]
【step2:y扩展】(朝下扩展):
[4 5 6]
[4 5 6]
[4 5 6]
【step3:定位(xi,yi)】:
[(1,4) (1,5) (1,6)]
[(2,4) (2,5) (2,6)]
[(3,4) (3,5) (3,6)]
【step4:将(xi,yi)代入F(x,y)=x+y】
因此这里x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j]后的结果为:

再通过stack()函数,axis=1,生成测试点
2.指定默认字体
mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False
3.绘制
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF']) cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light) plt.scatter(x[:, 0], x[:, 1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本 plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolors='none', zorder=10) # 圈中测试集样本 plt.xlabel(u'花萼长度', fontsize=13) plt.ylabel(u'花萼宽度', fontsize=13) plt.xlim(x1_min, x1_max) plt.ylim(x2_min, x2_max) plt.title(u'鸢尾花SVM二特征分类', fontsize=15) # plt.grid() plt.show()
pcolormesh(x,y,z,cmap)这里参数代入x1,x2,grid_hat,cmap=cm_light绘制的是背景。
scatter中edgecolors是指描绘点的边缘色彩,s指描绘点的大小,cmap指点的颜色。
xlim指图的边界。
最终结果为:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python机器学习之SVM支持向量机
SVM支持向量机是建立于统计学习理论上的一种分类算法,适合与处理具备高维特征的数据集. SVM算法的数学原理相对比较复杂,好在由于SVM算法的研究与应用如此火爆,CSDN博客里也有大量的好文章对此进行分析,下面给出几个本人认为讲解的相当不错的: 支持向量机通俗导论(理解SVM的3层境界) JULY大牛讲的是如此详细,由浅入深层层推进,以至于关于SVM的原理,我一个字都不想写了..强烈推荐. 还有一个比较通俗的简单版本的:手把手教你实现SVM算法 SVN原理比较复杂,但是思想很简单,一句话概括,就
-
Python中使用支持向量机SVM实践
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)SVM一般
-
Python中支持向量机SVM的使用方法详解
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类.因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm. 一.导入sklearn算法包 Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明 skleran中集成了许多算法,其导入包的方式如下所示, 逻辑回归:from sklearn.linear_model import LogisticRegression 朴素贝叶斯:fro
-
Python中使用支持向量机(SVM)算法
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)S
-
Python SVM(支持向量机)实现方法完整示例
本文实例讲述了Python SVM(支持向量机)实现方法.分享给大家供大家参考,具体如下: 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=>end: 结束 op1=>operation: 读入数据 op2=>operation: 格式化数据 cond=>condition: 是否达到迭代次数 op3=>operation: 寻找超平面分割最小间隔 ccond=>cond
-
Python中 CSV格式清洗与转换的实例代码
题目: CSV格式清洗与转换 描述 附件是一个CSV格式文件,提取数据进行如下格式转换: (1)按行进行倒序排列:
-
Python中的支持向量机SVM的使用(附实例代码)
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类.因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm. 一.导入sklearn算法包 Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明:http://scikit-learn.org/stable/auto_examples/index.html. skleran中集成了许多算法,其导入包的方式如下所示, 逻辑回归:from
-
Python中如何使用if语句处理列表实例代码
前言 每条if语句的核心都是一个值为True或False的表达式,这种表达式被称为条件测试.Python根据条件测试的值为True还是False来决定是否执行if语句中的代码.条件测试为True,则执行:否则,不执行. 本文将给大家详解介绍关于Python中用if语句处理列表的相关内容,下面话不多说了,来一起看看详细的介绍吧 1 基本用法 可以直接在列表迭代循环中,使用 if 语句: books=['半生缘','往事并不如烟','心是孤独的猎手'] for book in books: if(b
-
python中opencv支持向量机的实现
目录 支持向量机 理论基础 SVM使用介绍 例子介绍 完整程序 支持向量机 支持向量机(Support Vector Machine, SVM)是一种二分类模型,目标是寻找一个标准(称为超平面)对样本数据进行分割,分割的原则是确保分类最优化(类别之间的间隔最大). 当数据集较小时,使用支持向量机进行分类非常有效. 支持向量机是最好的现成分类器之一,“现成”是指分类器不加修改即可直接使用. 在对原始数据分类的过程中,可能无法使用线性方法实现分割.支持向量机在分类时,把无法线性分割的数据映射到高维空
-
python 与GO中操作slice,list的方式实例代码
python 与GO中操作slice,list的方式实例代码 GO代码中遍历slice,寻找某个slice,统计个数. type Element interface{} func main() { a := []int{1, 2, 3, 4, 1} for _, i := range a { fmt.Println(i) } for i := 0; i < len(a); i++ { //fmt.Println(i) } fmt.Println(index0(a, 3)) fmt.Println
-
python 中if else 语句的作用及示例代码
引入:if-else的作用,满足一个条件做什么,否则做什么. if-else语句语法结构 if 判断条件: 要执行的代码 else: 要执行的代码 判断条件:一般为关系表达式或bool类型的值 执行过程:程序运行到if处,首先判断所带的条件,如果条件成立,就是返回值是True,则执行下面的代码:如果条件不成立则返回值是False, 则继续执行下面的代码. 示例1:模拟用户登录 提示输入用户名和密码 如果用户名是Admin,密码等于123.com, 提示用户登录成功 如果用户名不是Admin,提示
-
Python中的单继承与多继承实例分析
本文实例讲述了Python中的单继承与多继承.分享给大家供大家参考,具体如下: 单继承 一.介绍 Python 同样支持类的继承,如果一种语言不支持继承,类就没有什么意义.派生类的定义如下所示: class DerivedClassName(BaseClassName1): <statement-1> . . . <statement-N> 需要注意圆括号中基类的顺序,若是基类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找基类
-
对python中基于tcp协议的通信(数据传输)实例讲解
阅读目录 tcp协议:流式协议(以数据流的形式通信传输).安全协议(收发信息都需收到确认信息才能完成收发,是一种双向通道的通信) tcp协议在OSI七层协议中属于传输层,它上承用户层的数据收发,下启网络层.数据链路层.物理层.可以说很多安全数据的传输通信都是基于tcp协议进行的. 为了让tcp通信更加方便需要引入一个socket模块(将网络层.数据链路层.物理层封装的模块),我们只要调用模块中的相关接口就能实现传输层下面的繁琐操作. 简单的tcp协议通信模板:(需要一个服务端和一个客户端) 服务