用Python徒手撸一个股票回测框架搭建【推荐】
通过纯Python完成股票回测框架的搭建。
什么是回测框架?
无论是传统股票交易还是量化交易,无法避免的一个问题是我们需要检验自己的交易策略是否可行,而最简单的方式就是利用历史数据检验交易策略,而回测框架就是提供这样的一个平台让交易策略在历史数据中不断交易,最终生成最终结果,通过查看结果的策略收益,年化收益,最大回测等用以评估交易策略的可行性。
代码地址在最后。
本项目并不是一个已完善的项目, 还在不断的完善。
回测框架
回测框架应该至少包含两个部分, 回测类, 交易类.
回测类提供各种钩子函数,用于放置自己的交易逻辑,交易类用于模拟市场的交易平台,这个类提供买入,卖出的方法。
代码架构
以自己的回测框架为例。主要包含下面两个文件
backtest/
backtest.py
broker.py
backtest.py主要提供BackTest这个类用于提供回测框架,暴露以下钩子函数.
def initialize(self): """在回测开始前的初始化""" pass def before_on_tick(self, tick): pass def after_on_tick(self, tick): pass def before_trade(self, order): """在交易之前会调用此函数 可以在此放置资金管理及风险管理的代码 如果返回True就允许交易,否则放弃交易 """ return True def on_order_ok(self, order): """当订单执行成功后调用""" pass def on_order_timeout(self, order): """当订单超时后调用""" pass def finish(self): """在回测结束后调用""" pass @abstractmethod def on_tick(self, bar): """ 回测实例必须实现的方法,并编写自己的交易逻辑 """ pass
玩过量化平台的回测框架或者开源框架应该对这些钩子函数不陌生,只是名字不一样而已,大多数功能是一致的,除了on_tick.
之所以是on_tick而不是on_bar, 是因为我希望交易逻辑是一个一个时间点的参与交易,在这个时间点我可以获取所有当前时间的所有股票以及之前的股票数据,用于判断是否交易,而不是一个时间点的一个一个股票参与交易逻辑。
而broker.py主要提供buy,sell两个方法用于交易。
def buy(self, code, price, shares, ttl=-1):
"""
限价提交买入订单
---------
Parameters:
code:str
股票代码
price:float or None
最高可买入的价格, 如果为None则按市价买入
shares:int
买入股票数量
ttl:int
订单允许存在的最大时间,默认为-1,永不超时
---------
return:
dict
{
"type": 订单类型, "buy",
"code": 股票代码,
"date": 提交日期,
"ttl": 存活时间, 当ttl等于0时则超时,往后不会在执行
"shares": 目标股份数量,
"price": 目标价格,
"deal_lst": 交易成功的历史数据,如
[{"price": 成交价格,
"date": 成交时间,
"commission": 交易手续费,
"shares": 成交份额
}]
""
}
"""
if price is None:
stock_info = self.ctx.tick_data[code]
price = stock_info[self.deal_price]
order = {
"type": "buy",
"code": code,
"date": self.ctx.now,
"ttl": ttl,
"shares": shares,
"price": price,
"deal_lst": []
}
self.submit(order)
return order
def sell(self, code, price, shares, ttl=-1):
"""
限价提交卖出订单
---------
Parameters:
code:str
股票代码
price:float or None
最低可卖出的价格, 如果为None则按市价卖出
shares:int
卖出股票数量
ttl:int
订单允许存在的最大时间,默认为-1,永不超时
---------
return:
dict
{
"type": 订单类型, "sell",
"code": 股票代码,
"date": 提交日期,
"ttl": 存活时间, 当ttl等于0时则超时,往后不会在执行
"shares": 目标股份数量,
"price": 目标价格,
"deal_lst": 交易成功的历史数据,如
[{"open_price": 开仓价格,
"close_price": 成交价格,
"close_date": 成交时间,
"open_date": 持仓时间,
"commission": 交易手续费,
"shares": 成交份额,
"profit": 交易收益}]
""
}
"""
if code not in self.position:
return
if price is None:
stock_info = self.ctx.tick_data[code]
price = stock_info[self.deal_price]
order = {
"type": "sell",
"code": code,
"date": self.ctx.now,
"ttl": ttl,
"shares": shares,
"price": price,
"deal_lst": []
}
self.submit(order)
return order
由于我很讨厌抽象出太多类,抽象出太多类及方法,我怕我自己都忘记了,所以对于对象的选择都是尽可能的使用常用的数据结构,如list, dict.
这里用一个dict代表一个订单。
上面的这些方法保证了一个回测框架的基本交易逻辑,而回测的运行还需要一个调度器不断的驱动这些方法,这里的调度器如下。
class Scheduler(object): """
整个回测过程中的调度中心, 通过一个个时间刻度(tick)来驱动回测逻辑
所有被调度的对象都会绑定一个叫做ctx的Context对象,由于共享整个回测过程中的所有关键数据,
可用变量包括:
ctx.feed: {code1: pd.DataFrame, code2: pd.DataFrame}对象
ctx.now: 循环所处时间
ctx.tick_data: 循环所处时间的所有有报价的股票报价
ctx.trade_cal: 交易日历
ctx.broker: Broker对象
ctx.bt/ctx.backtest: Backtest对象
可用方法:
ctx.get_hist
"""
def __init__(self):
""""""
self.ctx = Context()
self._pre_hook_lst = []
self._post_hook_lst = []
self._runner_lst = []
def run(self):
# runner指存在可调用的initialize, finish, run(tick)的对象
runner_lst = list(chain(self._pre_hook_lst, self._runner_lst, self._post_hook_lst))
# 循环开始前为broker, backtest, hook等实例绑定ctx对象及调用其initialize方法
for runner in runner_lst:
runner.ctx = self.ctx
runner.initialize()
# 创建交易日历
if "trade_cal" not in self.ctx:
df = list(self.ctx.feed.values())[0]
self.ctx["trade_cal"] = df.index
# 通过遍历交易日历的时间依次调用runner
# 首先调用所有pre-hook的run方法
# 然后调用broker,backtest的run方法
# 最后调用post-hook的run方法
for tick in self.ctx.trade_cal:
self.ctx.set_currnet_time(tick)
for runner in runner_lst:
runner.run(tick)
# 循环结束后调用所有runner对象的finish方法
for runner in runner_lst:
runner.finish()
在Backtest类实例化的时候就会自动创建一个调度器对象,然后通过Backtest实例的start方法就能启动调度器,而调度器会根据历史数据的一个一个时间戳不断驱动Backtest, Broker实例被调用。
为了处理不同实例之间的数据访问隔离,所以通过一个将一个Context对象绑定到Backtest, Broker实例上,通过self.ctx访问共享的数据,共享的数据主要包括feed对象,即历史数据,一个数据结构如下的字典对象。
{code1: pd.DataFrame, code2: pd.DataFrame}
而这个Context对象也绑定了Broker, Backtest的实例, 这就可以使得数据访问接口统一,但是可能导致数据访问混乱,这就要看策略者的使用了,这样的一个好处就是减少了一堆代理方法,通过添加方法去访问其他的对象的方法,真不嫌麻烦,那些人。
绑定及Context对象代码如下:
class Context(UserDict):
def __getattr__(self, key):
# 让调用这可以通过索引或者属性引用皆可
return self[key]
def set_currnet_time(self, tick):
self["now"] = tick
tick_data = {}
# 获取当前所有有报价的股票报价
for code, hist in self["feed"].items():
df = hist[hist.index == tick]
if len(df) == 1:
tick_data[code] = df.iloc[-1]
self["tick_data"] = tick_data
def get_hist(self, code=None):
"""如果不指定code, 获取截至到当前时间的所有股票的历史数据"""
if code is None:
hist = {}
for code, hist in self["feed"].items():
hist[code] = hist[hist.index <= self.now]
elif code in self.feed:
return {code: self.feed[code]}
return hist
class Scheduler(object):
"""
整个回测过程中的调度中心, 通过一个个时间刻度(tick)来驱动回测逻辑
所有被调度的对象都会绑定一个叫做ctx的Context对象,由于共享整个回测过程中的所有关键数据,
可用变量包括:
ctx.feed: {code1: pd.DataFrame, code2: pd.DataFrame}对象
ctx.now: 循环所处时间
ctx.tick_data: 循环所处时间的所有有报价的股票报价
ctx.trade_cal: 交易日历
ctx.broker: Broker对象
ctx.bt/ctx.backtest: Backtest对象
可用方法:
ctx.get_hist """ def __init__(self): """""" self.ctx = Context() self._pre_hook_lst = [] self._post_hook_lst = [] self._runner_lst = [] def add_feed(self, feed): self.ctx["feed"] = feed def add_hook(self, hook, typ="post"): if typ == "post" and hook not in self._post_hook_lst: self._post_hook_lst.append(hook) elif typ == "pre" and hook not in self._pre_hook_lst: self._pre_hook_lst.append(hook) def add_broker(self, broker): self.ctx["broker"] = broker def add_backtest(self, backtest): self.ctx["backtest"] = backtest # 简写 self.ctx["bt"] = backtest def add_runner(self, runner): if runner in self._runner_lst: return self._runner_lst.append(runner)
为了使得整个框架可扩展,回测框架中框架中抽象了一个Hook类,这个类可以在在每次回测框架调用前或者调用后被调用,这样就可以加入一些处理逻辑,比如统计资产变化等。
这里创建了一个Stat的Hook对象,用于统计资产变化。
class Stat(Base):
def __init__(self):
self._date_hist = []
self._cash_hist = []
self._stk_val_hist = []
self._ast_val_hist = []
self._returns_hist = []
def run(self, tick):
self._date_hist.append(tick)
self._cash_hist.append(self.ctx.broker.cash)
self._stk_val_hist.append(self.ctx.broker.stock_value)
self._ast_val_hist.append(self.ctx.broker.assets_value)
@property
def data(self):
df = pd.DataFrame({"cash": self._cash_hist,
"stock_value": self._stk_val_hist,
"assets_value": self._ast_val_hist}, index=self._date_hist)
df.index.name = "date"
return df
而通过这些统计的数据就可以计算最大回撤年化率等。
def get_dropdown(self):
high_val = -1
low_val = None
high_index = 0
low_index = 0
dropdown_lst = []
dropdown_index_lst = []
for idx, val in enumerate(self._ast_val_hist):
if val >= high_val:
if high_val == low_val or high_index >= low_index:
high_val = low_val = val
high_index = low_index = idx
continue
dropdown = (high_val - low_val) / high_val
dropdown_lst.append(dropdown)
dropdown_index_lst.append((high_index, low_index))
high_val = low_val = val
high_index = low_index = idx
if low_val is None:
low_val = val
low_index = idx
if val < low_val:
low_val = val
low_index = idx
if low_index > high_index:
dropdown = (high_val - low_val) / high_val
dropdown_lst.append(dropdown)
dropdown_index_lst.append((high_index, low_index))
return dropdown_lst, dropdown_index_lst
@property
def max_dropdown(self):
"""最大回车率"""
dropdown_lst, dropdown_index_lst = self.get_dropdown()
if len(dropdown_lst) > 0:
return max(dropdown_lst)
else:
return 0
@property
def annual_return(self):
"""
年化收益率
y = (v/c)^(D/T) - 1
v: 最终价值
c: 初始价值
D: 有效投资时间(365)
注: 虽然投资股票只有250天,但是持有股票后的非交易日也没办法投资到其他地方,所以这里我取365
参考: https://wiki.mbalib.com/zh-tw/%E5%B9%B4%E5%8C%96%E6%94%B6%E7%9B%8A%E7%8E%87
"""
D = 365
c = self._ast_val_hist[0]
v = self._ast_val_hist[-1]
days = (self._date_hist[-1] - self._date_hist[0]).days
ret = (v / c) ** (D / days) - 1
return ret
至此一个笔者需要的回测框架形成了。
交易历史数据
在回测框架中我并没有集成各种获取数据的方法,因为这并不是回测框架必须集成的部分,规定数据结构就可以了,数据的获取通过查看数据篇,
回测报告
回测报告我也放在了回测框架之外,这里写了一个Plottter的对象用于绘制一些回测指标等。结果如下:
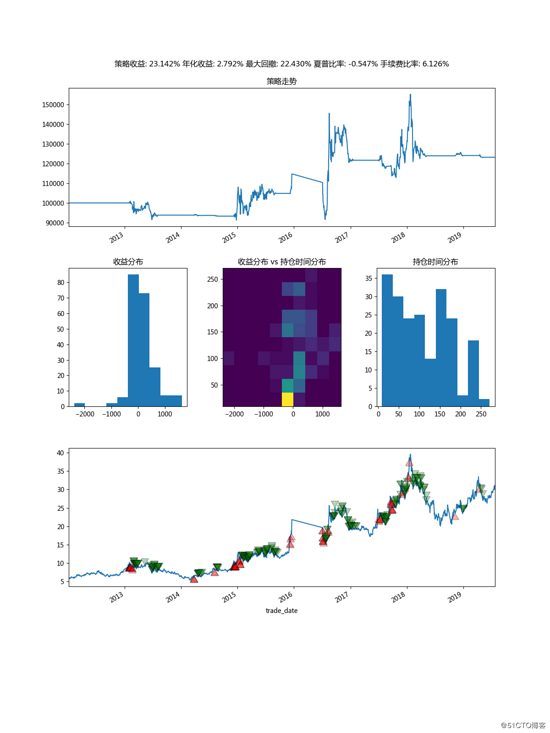
回测示例
下面是一个回测示例。
import json
from backtest import BackTest
from reporter import Plotter
class MyBackTest(BackTest):
def initialize(self):
self.info("initialize")
def finish(self):
self.info("finish")
def on_tick(self, tick):
tick_data = self.ctx["tick_data"]
for code, hist in tick_data.items():
if hist["ma10"] > 1.05 * hist["ma20"]:
self.ctx.broker.buy(code, hist.close, 500, ttl=5)
if hist["ma10"] < hist["ma20"] and code in self.ctx.broker.position:
self.ctx.broker.sell(code, hist.close, 200, ttl=1)
if __name__ == '__main__':
from utils import load_hist
feed = {}
for code, hist in load_hist("000002.SZ"):
# hist = hist.iloc[:100]
hist["ma10"] = hist.close.rolling(10).mean()
hist["ma20"] = hist.close.rolling(20).mean()
feed[code] = hist
mytest = MyBackTest(feed)
mytest.start()
order_lst = mytest.ctx.broker.order_hist_lst
with open("report/order_hist.json", "w") as wf:
json.dump(order_lst, wf, indent=4, default=str)
stats = mytest.stat
stats.data.to_csv("report/stat.csv")
print("策略收益: {:.3f}%".format(stats.total_returns * 100))
print("最大回彻率: {:.3f}% ".format(stats.max_dropdown * 100))
print("年化收益: {:.3f}% ".format(stats.annual_return * 100))
print("夏普比率: {:.3f} ".format(stats.sharpe))
plotter = Plotter(feed, stats, order_lst)
plotter.report("report/report.png")
项目地址
https://github.com/youerning/stock_playground
总结
以上所述是小编给大家介绍的用Python徒手撸一个股票回测框架,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python3使用pandas获取股票数据的方法
如下所示: from pandas_datareader import data, wb from datetime import datetime import matplotlib.pyplot as plt end = datetime.now() start = datetime(end.year - 1, end.month, end.day) alibaba = data.DataReader('BABA', 'yahoo', start, end) alibaba['Adj Clo
-
使用Python写一个量化股票提醒系统
大家在没有阅读本文之前先看下python的基本概念, Python是一种解释型.面向对象.动态数据类型的高级程序设计语言. Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年. 像Perl语言一样, Python 源代码同样遵循 GPL(GNU General Public License)协议. 本文是小兵使用万能的Python写一个量化股票系统!下面是一个小马的迷你量化系统. 这个小迷小量化系统,麻雀虽小但是五脏俱全,我们今天先从实时提醒这个模
-

使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
用Python徒手撸一个股票回测框架搭建【推荐】
通过纯Python完成股票回测框架的搭建. 什么是回测框架? 无论是传统股票交易还是量化交易,无法避免的一个问题是我们需要检验自己的交易策略是否可行,而最简单的方式就是利用历史数据检验交易策略,而回测框架就是提供这样的一个平台让交易策略在历史数据中不断交易,最终生成最终结果,通过查看结果的策略收益,年化收益,最大回测等用以评估交易策略的可行性. 代码地址在最后. 本项目并不是一个已完善的项目, 还在不断的完善. 回测框架 回测框架应该至少包含两个部分, 回测类, 交易类. 回测类提供各种钩子函数
-
使用Python从零开始撸一个区块链
作者认为最快的学习区块链的方式是自己创建一个,本文就跟随作者用Python来创建一个区块链. 对数字货币的崛起感到新奇的我们,并且想知道其背后的技术--区块链是怎样实现的. 但是完全搞懂区块链并非易事,我喜欢在实践中学习,通过写代码来学习技术会掌握得更牢固.通过构建一个区块链可以加深对区块链的理解. 准备工作 本文要求读者对Python有基本的理解,能读写基本的Python,并且需要对HTTP请求有基本的了解. 我们知道区块链是由区块的记录构成的不可变.有序的链结构,记录可以是交易.文件或任何你
-
python使用pandas进行量化回测
下面文章描述可能比excel高级一点,距离backtrader这些框架又差一点.做最基础的测试可以,如果后期加入加仓功能,或者是止盈止损等功能,很不合适.只能做最简单的技术指标测试. 导包,常用包导入: import os import akshare as ak import requests import numpy as np import pandas as pd import matplotlib.pyplot as plt import talib as ta %matplotlib
-
基于Python轻松制作一个股票K线图网站
目录 获取股票数据 PyEcharts 作图 构建 Web 框架 视图函数编写 模板编写 编辑主逻辑 前端页面编写 在前面的文章中,我们学习了如何使用 Tkinter 构建股票数据抓取以及展示K线图功能,虽然大致的功能已经具备,但是在当今这个人手一个 Web 服务的年代,GUI 程序还是没有 Web 服务来的香啊. 我们需要用到的知识包括 PyEcharts 的使用,tushare 库获取股票数据的方法以及 Flask 的基本用法. 获取股票数据 我们先来看下 tushare 的使用,这个应该是
-
Python爬虫回测股票的实例讲解
股票和基金一直是热门的话题,很多周围的人都选择不同种类的理财方式.就股票而言,肯定是短时间内收益最大化,这里我们需要用python爬虫的方法,来帮助我们获取一些股票的数据,这样才能更好的买到相应的股票.下面我们就python爬虫获取股票数据的方法带来详细的讲解. 1.生成上证与深证所有股票的代码: #上证代码 shanghaicode = [] for i in range(600000, 604000, 1): shanghaicode.append(str(i)) #深证代码 shenzhe
-
python实现马丁策略回测3000只股票的实例代码
上一篇文章讲解了如何实现马丁策略,但没有探索其泛化能力,所以这次来尝试回测3000只股票来查看盈利比例. 批量爬取股票数据 这里爬取数据继续使用tushare,根据股票代码来遍历,因为爬取数据需要一定时间,不妨使用多线程来爬取,这里要注意tushare规定每分钟爬取不能超过500次,除非你有很多积分,所以线程数要适当调低. 首先我们生成上证与深证所有股票的代码: #上证代码 shanghaicode = [] for i in range(600000, 604000, 1): shanghai
-
Python实现判断一个整数是否为回文数算法示例
本文实例讲述了Python实现判断一个整数是否为回文数算法.分享给大家供大家参考,具体如下: 第一个思路是先将整数转换为字符串,再将字符串翻转并与原字符串做比较 def isPalindrome(self, x): """ :type x: int :rtype: bool """ #思路:先将整数转换为字符串,再将字符串翻转并与原字符串做比较 x = str(x) return x == x[::-1] 代码简洁 第二个思路,尝试着不用字符串,
-
基于Python编写一个根据姓名测性别的小程序
目录 导语 一.准备环节 1.1安装环境 二.准备素材 三.开始敲代码 3.1导入模块 3.2定义界面 3.3预测性别 3.4读取数据 3.5附完整的源码 四.效果展示 总结 导语 以前上英语课老师都会教哪些名字一听就知道是男生的,比如David.Tom.Jerry,然后Angela.Sophia一听就是女生的名字.当你以为所有名字一听就可以辨别男女的时候,你就想错了~就像中文里面“贾凡”,你以为是男生,其实是女生也说不定.这种难分性别的名字 其实很多呢~为了避免宝宝的性别和提前取好的名字冲突,
-
Python写的一个简单监控系统
市面上有很多开源的监控系统:Cacti.nagios.zabbix.感觉都不符合我的需求,为什么不自己做一个呢 用Python两个小时徒手撸了一个简易的监控系统,给大家分享一下,希望能对大家有所启发 首先数据库建表 建立一个数据库"falcon",建表语句如下: CREATE TABLE `stat` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `host` varchar(256) DEFAULT NULL, `mem_free`
-
如何用Python徒手写线性回归
对于大多数数据科学家而言,线性回归方法是他们进行统计学建模和预测分析任务的起点.这种方法已经存在了 200 多年,并得到了广泛研究,但仍然是一个积极的研究领域.由于良好的可解释性,线性回归在商业数据上的用途十分广泛.当然,在生物数据.工业数据等领域也不乏关于回归分析的应用. 另一方面,Python 已成为数据科学家首选的编程语言,能够应用多种方法利用线性模型拟合大型数据集显得尤为重要. 如果你刚刚迈入机器学习的大门,那么使用 Python 从零开始对整个线性回归算法进行编码是一次很有意义的尝试,