Python DataFrame一列拆成多列以及一行拆成多行
摘要
在进行数据分析时,我们经常需要把DataFrame的一列拆成多列或者根据某列把一行拆成多行,这篇文章主要讲解这两个目标的实现。
1.读取数据

2.将City列转成多列(以‘|'为分隔符)
这里使用匿名函数lambda来讲City列拆成两列。

3.将DataFrame一行拆成多行(以‘|'为分隔符)
方法一:在刚刚得到的DataFrame基础上操作,如下图所以,可以明显看到我们按照City列将DataFrame拆成了多行。主要是先将DataFrame拆成多列,然后拆成多个DataFrame再使用concat组合。但是这种方法碰到City列切割不均匀的时候可能会麻烦一点,因此,这个时候你可以使用万能方法二。

方法二:这个方法的主要思想是,首先将DataFrame中需要拆分的列进行拆分,再使用stack()进行轴变换,然后通过index来join即可,如下所示。
首先,将刚刚的df还原成原始形式:

接下来取出其City列,并切分成多列之后轴转换,之后重新设置索引,并且重命名为Company
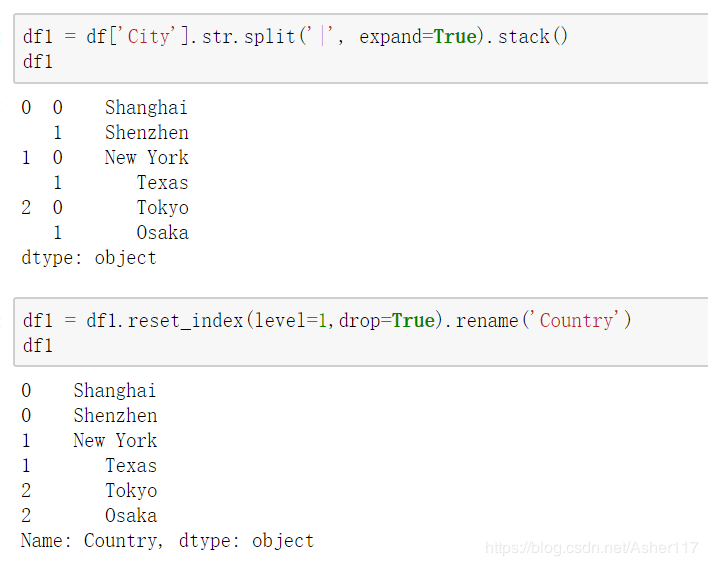
最后删除df里面的Country列,并将DataFrame-df1 使用join到df里面得到最后的结果。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
使用Python向DataFrame中指定位置添加一列或多列的方法
对于这个问题,相信很多人都会很困惑,本篇文章将会给大家介绍一种非常简单的方式向DataFrame中任意指定的位置添加一列. 在此之前或许有不少读者已经了解了最普通的添加一列的方式,如下: import pandas as pd feature = pd.read_csv("C://Users//Machenike//Desktop//xzw//lr_train_data.txt", delimiter="\t", header=None, usecols=[0, 1
-
Python Dataframe 指定多列去重、求差集的方法
1)去重 指定多列去重,这是在dataframe没有独一无二的字段作为PK(主键)时,需要指定多个字段一起作为该行的PK,在这种情况下对整体数据进行去重. Attention:主要用到了drop_duplicates方法,并设置参数subset为多个字段名构成的数组. 具体代码如下: >>>import pandas as pd >>>data={'state':[1,1,2,2,1,2,2],'pop':['a','b','c','d','b','c','d']} &
-
Python DataFrame一列拆成多列以及一行拆成多行
摘要 在进行数据分析时,我们经常需要把DataFrame的一列拆成多列或者根据某列把一行拆成多行,这篇文章主要讲解这两个目标的实现. 1.读取数据 2.将City列转成多列(以'|'为分隔符) 这里使用匿名函数lambda来讲City列拆成两列. 3.将DataFrame一行拆成多行(以'|'为分隔符) 方法一:在刚刚得到的DataFrame基础上操作,如下图所以,可以明显看到我们按照City列将DataFrame拆成了多行.主要是先将DataFrame拆成多列,然后拆成多个DataFrame再
-
python DataFrame获取行数、列数、索引及第几行第几列的值方法
1.df=DataFrame([{'A':'11','B':'12'},{'A':'111','B':'121'},{'A':'1111','B':'1211'}]) print df.columns.size#列数 2 print df.iloc[:,0].size#行数 3 print df.ix[[0]].index.values[0]#索引值 0 print df.ix[[0]].values[0][0]#第一行第一列的值 11 print df.ix[[1]].values[0][1]
-
python DataFrame 修改列的顺序实例
假设我有一个DataFrame(df)如下: name age id mike 10 1 tony 14 2 lee 20 3 现在我想把id 放到最前面,变成: id name age df_id = df.id df = df.drop('id',axis=1) df.insert(0,'id',df_id) 以上这篇python DataFrame 修改列的顺序实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Python中datet
-
python dataframe常见操作方法:实现取行、列、切片、统计特征值
实例如下所示: # -*- coding: utf-8 -*- import numpy as np import pandas as pd from pandas import * from numpy import * data = DataFrame(np.arange(16).reshape(4,4),index = list("ABCD"),columns=list('wxyz')) print data print data[0:2] #取前两行数据 print'+++++
-

Python中序列的修改、散列与切片详解
前言 本文主要给大家介绍了关于Python中序列的修改.散列与切片的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. Vector类:用户定义的序列类型 我们将使用组合模式实现 Vector 类,而不使用继承.向量的分量存储在浮点数数组中,而且还将实现不可变扁平序列所需的方法. Vector 类的第 1 版要尽量与前一章定义的 Vector2d 类兼容. Vector类第1版:与Vector2d类兼容 Vector 类的第 1 版要尽量与前一章定义的 Vector2d
-
pandas中的DataFrame按指定顺序输出所有列的方法
问题: 输出新建的DataFrame对象时,DataFrame中各列的显示顺序和DataFrame定义中的顺序不一致. 例如: import pandas as pd grades = [48,99,75,80,42,80,72,68,36,78] df = pd.DataFrame( {'ID': ["x%d" % r for r in range(10)], 'Gender' : ['F', 'M', 'F', 'M', 'F', 'M', 'F', 'M', 'M', 'M'],
-
Python Numpy 实现交换两行和两列的方法
numpy应该是一个和常用的包了,但是在百度查了很久,也没有查到如何交换两列(交换两行的有),所以查看了其他的文档,找到了方法. 交换两行 比如a = np.array([[1,2,3],[2,3,4],[1,6,5], [9,3,4]]),想要交换第二行和第三行,看起来很简单,直接写代码: import numpy as np a = np.array([[1,2,3],[2,3,4],[1,6,5], [9,3,4]]) tmp = a[1] a[1] = a[2] a[2] = tmp 运
-
Python从Excel中读取日期一列的方法
如下所示: import xlrd import datetime file=u"伏特加.xls"#注意读中文文件名稍微处理一下 data=xlrd.open_workbook(file) table = data.sheet_by_index(0)#按照索引读Excel文件 colContent=table.col_values(1)#读某一列,日期在第二列 nrows=table.nrows #行数 print nrows ncols = table.ncols#列数 print