Python正则表达式匹配数字和小数的方法
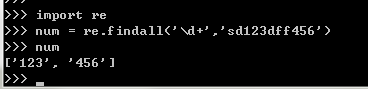
1.正则匹配数字,\为转义字符,d+为匹配一次或多次
如下所示:返回的结果为列表
2.正则匹配小数
如下所示,返回的结果125.6为字符串

总结
以上所述是小编给大家介绍的Python正则表达式匹配数字和小数的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

Python使用中文正则表达式匹配指定中文字符串的方法示例
本文实例讲述了Python使用中文正则表达式匹配指定中文字符串的方法.分享给大家供大家参考,具体如下: 业务场景: 从中文字句中匹配出指定的中文子字符串 .这样的情况我在工作中遇到非常多, 特梳理总结如下. 难点: 处理GBK和utf8之类的字符编码, 同时正则匹配Pattern中包含汉字,要汉字正常发挥作用,必须非常谨慎.推荐最好统一为utf8编码,如果不是这种最优情况,也有酌情处理. 往往一个具有普适性的正则表达式会简化程序和代码的处理,使过程简洁和事半功倍,这往往是高手和菜鸟最显著的差别.
-
python使用正则表达式替换匹配成功的组
正则表达式简介 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念.正则表达式使用单个字符串来描述.匹配一系列符合某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索.替换那些符合某个模式的文本. 许多程序设计语言都支持利用正则表达式进行字符串操作.例如,在Perl中就内建了一个功能强大的正则表达式引擎.正则表达式这个概念最初是由Unix中的工
-
Python匹配中文的正则表达式
正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同:但不用担心,不被支持的语法通常是不常用的部分. Python正则表达式简介 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 P
-
python正则表达式去掉数字中的逗号(python正则匹配逗号)
分析 数字中经常是3个数字一组,之后跟一个逗号,因此规律为:***,***,*** 正则式 复制代码 代码如下: [a-z]+,[a-z]? 复制代码 代码如下: import re sen = "abc,123,456,789,mnp"p = re.compile("\d+,\d+?") for com in p.finditer(sen): mm = com.group() print "hi:", mm print &qu
-
详解python里使用正则表达式的全匹配功能
详解python里使用正则表达式的全匹配功能 python中很多匹配,比如搜索任意位置的search()函数,搜索边界的match()函数,现在还需要学习一个全匹配函数,就是搜索的字符与内容全部匹配,它就是fullmatch()函数. 例子如下: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'This is some text -- with punctua
-
python字符串中匹配数字的正则表达式
Python 正则表达式简介 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. 本章节给大家介
-
Python正则表达式非贪婪、多行匹配功能示例
本文实例讲述了Python正则表达式非贪婪.多行匹配功能.分享给大家供大家参考,具体如下: 一些regular的tips: 1 非贪婪flag >>> re.findall(r"a(\d+?)","a23b") # 非贪婪模式 ['2'] >>> re.findall(r"a(\d+)","a23b") ['23'] 注意比较这种情况: >>> re.findall(r&q
-
Python正则表达式匹配HTML页面编码
html页面一般都会指定一个编码,如何获取到是处理html页面的第一步,因为错误的编码必然带来后面处理的问题.这里我用python的正则表达式写了个: import re a = ["<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />", '<meta http-equiv=Content-Type content="text/ht
-
python正则表达式中的括号匹配问题
问题: m = re.findall('[0-9]*4[0-9]*', '[4]') 可以匹配到4. m = re.findall('([0-9])*4([0-9])*', '[4]') 匹配不到4. 这是为什么呢?PS,这个是一个简化的说明,我要用的正则比这个复杂,所以要用到(),表示一个序列的匹配. 补充一点,我放在notepad++中用的时候,两种写法都能匹配出来,不知道为什么python中就不行了. 答案: python的正则中用()会进行匹配,所以返回结果是['',''],就是两个()
-
Python正则表达式匹配数字和小数的方法
1.正则匹配数字,\为转义字符,d+为匹配一次或多次 如下所示:返回的结果为列表 2.正则匹配小数 如下所示,返回的结果125.6为字符串 总结 以上所述是小编给大家介绍的Python正则表达式匹配数字和小数的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持! 如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
-
Python正则表达式匹配日期与时间的方法
下面给大家介绍下Python正则表达式匹配日期与时间 #!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'Randy' import re from datetime import datetime test_date = '他的生日是2016-12-12 14:34,是个可爱的小宝贝.二宝的生日是2016-12-21 11:34,好可爱的.' test_datetime = '他的生日是2016-12-12 14:34,是个可
-
Python 正则表达式匹配数字及字符串中的纯数字
Python 正则表达式匹配数字 电话号码:\d{3}-\d{8}|\d{4}-\d{7} QQ号:[1-9][0-9]{4,} 中国邮政编码:[1-9]\d{5}(?!\d) 身份证:\d{15}|\d{18} ip地址:\d+\.\d+\.\d+\.\d+ [1-9]\d* 正整数 -[1-9]\d* 负整数 -?[1-9]\d* 整数 [1-9]\d*|0 非负整数 -[1-9]\d*|0 非正整数 [1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 正浮点数 -([1-
-
Python 正则表达式匹配字符串中的http链接方法
利用Python正则表达式匹配字符串中的http链接.主要难点是用正则表示出http 链接的模式. import re pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') # 匹配模式 string = 'Its after 12 noon, do you know where your rooftops are? http://tinyur
-
python正则表达式匹配不包含某几个字符的字符串方法
一.匹配目标 文件中所有以https?://开头,以.jpg|.png|.jpeg结尾的字符串 二.尝试过程 1) 自然想到正则表达式r'(https?://.*?.jpg|https?://.*?.png|https?://.*?.jpeg)简化书写为r'(https?://.*?\.(?:jpg|png|jpeg) 匹配结果:['http://sdsdsdadadsdsdsddsdsdawwii,https://sdsdoijcjz.jpg']发现结果并非我们想要的,仔细查看,结果中出现了,
-
Python正则表达式匹配字符串中的数字
1.使用"\d+"匹配全数字 代码: import re zen = "Arizona 479, 501, 870. Carlifornia 209, 213, 650." m = re.findall("\d+", zen) print(m) 结果: ['479', '501', '870', '209', '213', '650'] 但是上述这种方式也会引入非纯数据,例子如下: import re zen = "Arizona 47
-
解决Python正则表达式匹配反斜杠''\''问题
在学习Python正则式的过程中,有一个问题一直困扰我,如何去匹配一个反斜杠(即"\")? 一.引入 在学习了Python特殊字符和原始字符串之后,我觉得答案应该是这样的: 1)普通字符串:'\\' 2)原始字符串:r'\' 但事实上在提取诸如"3\8"反斜杠之前的数字时,我屡次碰壁,始终得不到结果.最终发现自己理解错了,原来原始字符串和"正则转义"没有一点关系:下面详细谈一谈. 二.字符串转义 反斜杠,在Python中比较特殊,就是它可以用来构
-
Python正则匹配判断手机号是否合法的方法
正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),是计算机科学的一个概念.正则表达式使用单个字符串来描述.匹配一系列匹配某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索.替换那些匹配某个模式的文本. # 需求 # 定义一个函数,用于判断输入的手机号是否合法 # 并判断它的运营商 # 思路步骤: # 1.首先了解三大运营商的号段分布 # 2.获取用户输入内容 #
-
python正则表达式 匹配反斜杠的操作方法
python正则表达式 匹配反斜杠 正则 需要把原始字符串不被转义的条件下传递给正则模块,正则再去转义. r表示r后面的字符串为原始字符串,防止计算机将 \ 理解为转义字符. r'^\\$' 首先按照原始字符串给到compile函数 ,正则再把r'^\\$'中的\`翻译成\ backslash='\\' print(backslash) regular_backslash=re.compile(r'^\\$') print(regular_backslash.search(regular_bac