redis缓存穿透解决方法
缓存技术可以用来减轻数据库的压力,提升访问效率。目前在企业项目中对缓存也是越来越重视。但是缓存不是说随随便便加入项目就可以了。将缓存整合到项目中,这才是第一步。而缓存带来的穿透问题,进而导致的雪蹦问题都是我们迫切需要解决的问题。本篇文章将我平时项目中的解决方案分享给大家,以供参考。
一、缓存穿透的原理
缓存的正常使用如图:
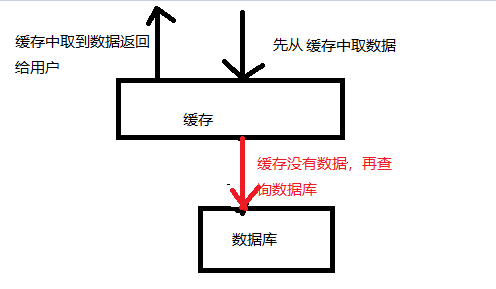
如图所示,缓存的使用流程:
1、先从缓存中取数据,如果能取到,则直接返回数据给用户。这样不用访问数据库,减轻数据库的压力。
2、如果缓存中没有数据,就会访问数据库。
这里面就会存在一个BUG,如图:
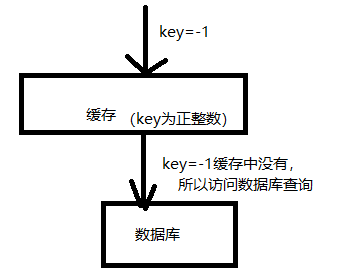
如图,缓存就像是数据库的一道防火墙,将请求比较频繁的数据放到缓存中,从而减轻数据库的压力。 但是如果有人恶意攻击,那就很轻松的穿透你的缓存,将所有的压力都给数据库。比如上图,你缓存的key都是正整数,但是我偏偏使用负数作为key访问你的缓存,这样就会导致穿透缓存,将压力直接给数据库。
二、导致缓存穿透的原因
缓存穿透的问题,肯定是再大并发情况下。依此为前提,我们分析缓存穿透的原因如下:
1、恶意攻击,猜测你的key命名方式,然后估计使用一个你缓存中不会有的key进行访问。
2、第一次数据访问,这时缓存中还没有数据,则并发场景下,所有的请求都会压到数据库。
3、数据库的数据也是空,这样即使访问了数据库,也是获取不到数据,那么缓存中肯定也没有对应的数据。这样也会导致穿透。
三、解决缓存穿透
缓存穿透在于一步步规避穿透的原因,如图:
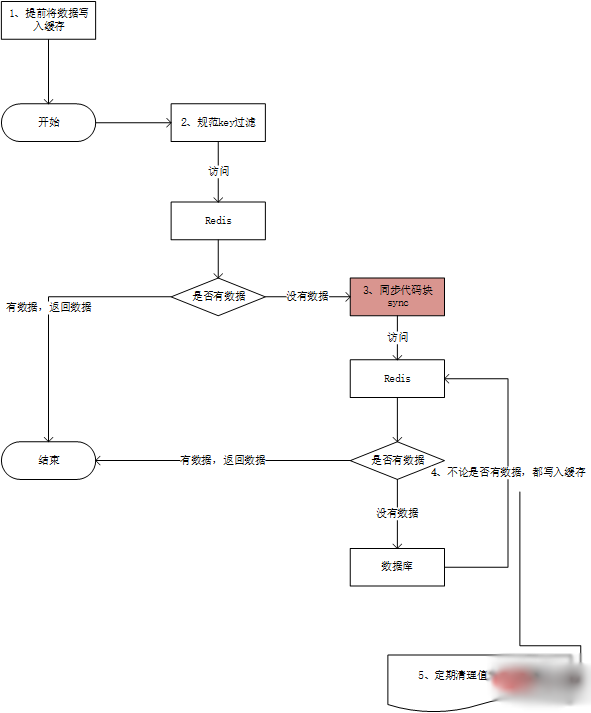
如上图所示,解决的步骤如下:
1、再web服务器启动时,提前将有可能被频繁并发访问的数据写入缓存。—这样就规避大量的请求在第3步出现排队阻塞。
2、规范key的命名,并且统一缓存查询和写入的入口。这样,在入口处,对key的规范进行检测。–这样保存恶意的key被拦截。
3、Synchronized双重检测机制,这时我们就需要使用同步(Synchronized)机制,在同步代码块前查询一下缓存是否存在对应的key,然后同步代码块里面再次查询缓存里是否有要查询的key。 这样“双重检测”的目的,还是避免并发场景下导致的没有意义的数据库的访问(也是一种严格避免穿透的方案)。
这一步会导致排队,但是第一步中我们说过,为了避免大量的排队,可以提前将可以预知的大量请求提前写入缓存。
4、不管数据库中是否有数据,都在缓存中保存对应的key,值为空就行。–这样是为了避免数据库中没有这个数据,导致的平凡穿透缓存对数据库进行访问。
5、第4步中的空值如果太多,也会导致内存耗尽。导致不必要的内存消耗。这样就要定期的清理空值的key。避免内存被恶意占满。导致正常的功能不能缓存数据。
相关推荐
-
redis缓存穿透解决方法
缓存技术可以用来减轻数据库的压力,提升访问效率.目前在企业项目中对缓存也是越来越重视.但是缓存不是说随随便便加入项目就可以了.将缓存整合到项目中,这才是第一步.而缓存带来的穿透问题,进而导致的雪蹦问题都是我们迫切需要解决的问题.本篇文章将我平时项目中的解决方案分享给大家,以供参考. 一.缓存穿透的原理 缓存的正常使用如图: 如图所示,缓存的使用流程: 1.先从缓存中取数据,如果能取到,则直接返回数据给用户.这样不用访问数据库,减轻数据库的压力. 2.如果缓存中没有数据,就会访问数据库. 这里面就
-

Redis缓存穿透/击穿工具类的封装
目录 1. 简单的步骤说明 2. 逻辑缓存数据类型 3. 缓冲工具类的封装 3.1 CacheClient 类的类图结构 3.2 CacheClient 类代码 1. 简单的步骤说明 创建一个逻辑缓存数据类型 封装缓冲穿透和缓冲击穿工具类 2. 逻辑缓存数据类型 这里主要是创建一个可以往Redis里边存放的数据类型 RedisData 的Java类型 import lombok.Data; import java.time.LocalDateTime; @Data public class Re
-
ajax的get请求时缓存处理解决方法
本文实例讲述了ajax的get请求时缓存处理解决方法.分享给大家供大家参考.具体分析如下: 很多时候在Ajax的get方法调用的时候由于缓存的原因无法及时获取正确的数据,这里就来分析一下解决这一问题的方法: 1. 在url后面添加一个随机数,如: 复制代码 代码如下: http://www.test.com?a=a&b=b&r=Math.random(); 2. 在url后面添加时间戳: 复制代码 代码如下: var t = new Date().getTime(); http://www
-
SpringBoot使用Redis缓存的实现方法
(1)pom.xml引入jar包,如下: <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> (2)修改项目启动类,增加注解@EnableCaching,开启缓存功能,如下: package springboot; import org
-
docker django无法访问redis容器的解决方法
docker-compose.yal文件中: redis: image: redis container_name: xdemo.redis ports: - 6379:6379 restart: always django setting.py中配置redis: CACHES = { 'default': { 'BACKEND': 'django_redis.cache.RedisCache', 'LOCATION': 'redis://127.0.0.1:6379', "OPTIONS&qu
-
详解在Java程序中运用Redis缓存对象的方法
这段时间一直有人问如何在Redis中缓存Java中的List 集合数据,其实很简单,常用的方式有两种: 1. 利用序列化,把对象序列化成二进制格式,Redis 提供了 相关API方法存储二进制,取数据时再反序列化回来,转换成对象. 2. 利用 Json与java对象之间可以相互转换的方式进行存值和取值. 正面针对这两种方法,特意写了一个工具类,来实现数据的存取功能. 1. 首页在Spring框架中配置 JedisPool 连接池对象,此对象可以创建 Redis的连接 Jedis对象.当然,必须导
-
SpringBoot使用Redis缓存MySql的方法步骤
目录 1项目组成 2运行springboot 2.1官网download最基本的restful应用 2.2运行应用 3访问mysql 4设置redis缓存 1 项目组成 应用:springboot rest api 数据库:mysql jdbc框架:jpa 缓存中间件:redis 2 运行springboot 2.1 官网download最基本的restful应用 教程地址:https://spring.io/guides/gs/rest-service/ 直接download成品,找到git命
-
Redis缓存穿透出现原因及解决方案
在并发式的项目当中,一定要考虑一个缓存穿透的情况.那么什么是缓存穿透呢?简单的说来,就是当大量请求的key根本不在缓存当中,所以导致了请求直接到了数据库上,根本没有经过缓存这一层.比如一个黑客故意制造我们缓存中不存在的key发送大量的请求,就会导致请求直接落到数据库上. 也就是说,缓存穿透就是:1.缓存层不命中.2,存储层不命中,不将空的结果写回缓存.3,返回空结果给客户端. 一般mysql的默认最大连接数是150左右,当然这个是可以用show variables like '%max_conn
-
详解Redis缓存穿透/击穿/雪崩原理及其解决方案
目录 1.简介 2.缓存穿透 2.1描述 2.2解决方案 3.缓存击穿 3.1描述 3.2解决方案 4.缓存雪崩 4.1描述 4.1解决方案 5.布隆过滤器 5.1描述 5.2数据结构 5.3"一定不在集合中" 5.4"可能在集合中" 5.5"删除困难" 5.6为什么不使用HashMap呢? 1. 简介 如图所示,一个正常的请求 1.客户端请求张铁牛的博客. 2.服务首先会请求redis,查看请求的内容是否存在. 3.redis将请求结果返回给服
-
利用ganglia监控redis的最新解决方法
前言 Ganglia主要用来监控系统性能的软件,通过曲线很容易见到每个节点的工作状态,对合理调整,分配系统资源,提高系统整体性能起到重要作用,支持浏览器方式访问,但不能监控节点硬件技术指标.Ganglia是分布式的监控系统. Redis现在在业务中应用已经很广泛了,但是如何监控redis,实时的观察redis的性能,在搜索引擎搜索"ganglia监控redis",发现都是13年的老文章,都是说要到https://github.com/ganglia/gmond_python_modul